Clear Sky Science · nl
Moleculaire kaartvorming in DNA‑PAINT via gewijzigde Gaussian Mengselmodellering
De onzichtbare wereld van moleculen zichtbaar maken
De moderne biologie vertrouwt steeds meer op microscopen die niet alleen cellen tonen, maar ook individuele moleculen daarin. Het omzetten van het zwakke, knipperende licht van die moleculen in een betrouwbare "kaart" van hun posities blijkt echter verrassend lastig. Deze studie introduceert een nieuwe computationele methode, G5M, die deze moleculaire kaarten veel nauwkeuriger en gedetailleerder maakt, en onderzoekers helpt te begrijpen hoe eiwitten gerangschikt en gegroepeerd zijn in echte cellen, tot op slechts enkele miljardsten van een meter.
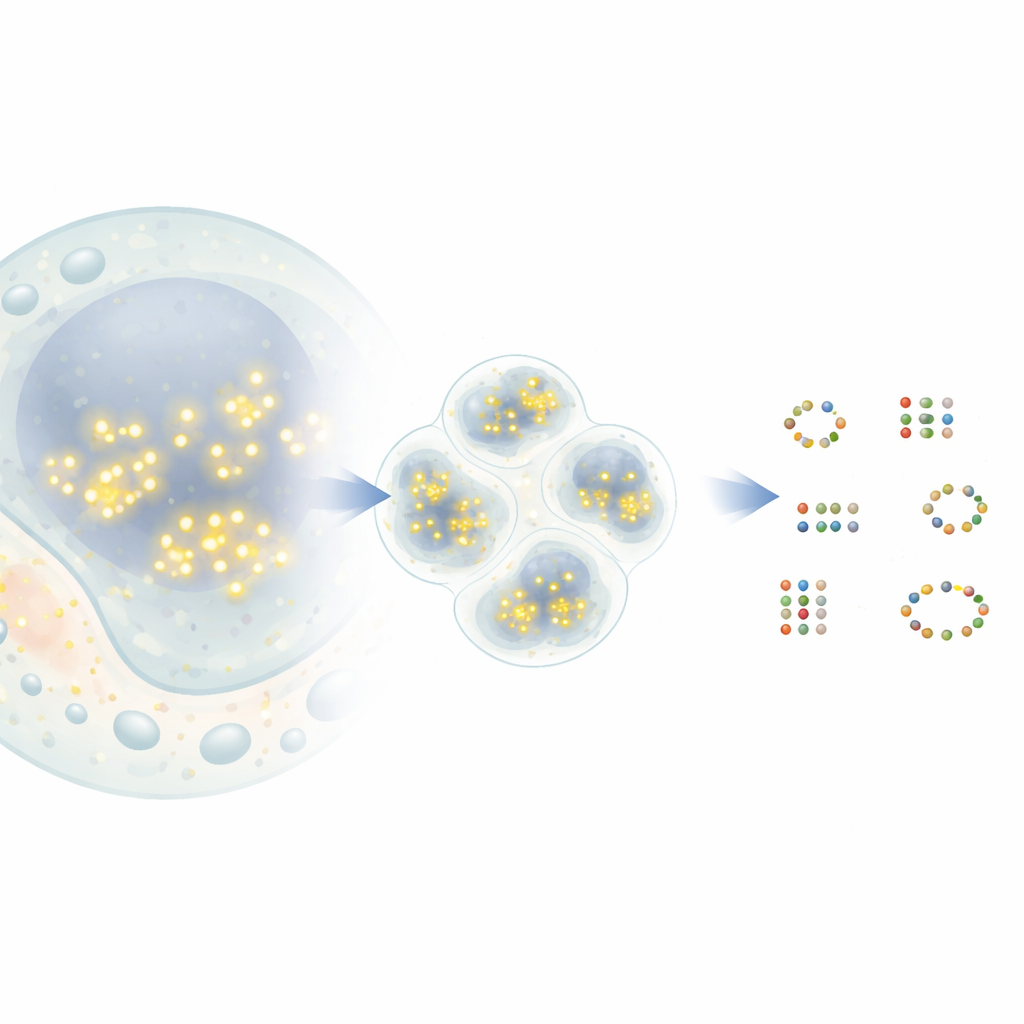
Van knipperende stippen naar moleculaire kaarten
In een populaire superresolutietechniek genaamd DNA‑PAINT binden korte DNA‑strengen met fluorescerende kleurstoffen kortstondig aan complementaire DNA‑tags die aan doelwitproteïnen zijn bevestigd. Elke keer dat een kleurstof bindt, verschijnt er een heldere stip in de microscoop voordat deze weer verdwijnt. In de loop van de tijd creëren veel van dergelijke gebeurtenissen een wolk van stippen rond elk eiwit. In principe markeert het centrum van elke wolk de werkelijke positie van een eiwit met precisie op nanometerschalige. In de praktijk kunnen echter stippen van nabijgelegen eiwitten overlappen en sommige stippen ontstaan door willekeurige achtergrondsignalen. Bestaande analysetools voegen vaak nabije buren samen tot één eiwit of verzinnen juist eiwitten die er niet zijn, waardoor de biologische inzichten die gewonnen kunnen worden beperkt blijven.
Een slimmer manier om echte moleculen te vinden
De nieuwe methode, G5M, behandelt de wolk van stippen als een mengsel van eenvoudige, klokvormige wolken, waarbij elke wolk overeenkomt met één echt molecuul. In plaats van alleen nabijgelegen stippen te groeperen op basis van dichtheid, gebruikt G5M een probabilistisch model dat opneemt wat al bekend is over het experiment: hoe nauwkeurig posities gemeten kunnen worden, hoe snel DNA‑strengen binden en loslaten, en hoe de microscoop licht in twee of drie dimensies vervaagt. Vervolgens test het verschillende mogelijke verklaringen—verschillende aantallen en vormen van wolken—en kiest automatisch diegene die de beste balans biedt tussen nauwkeurigheid en eenvoud. Aanvullende vangnetten verwerpen verdachte oplossingen, zoals wolken die te smal of te breed zijn, gebaseerd op te weinig stippen of niet duidelijk van elkaar gescheiden.
Kracht bewezen in simulaties en DNA‑nanostructuren
Om G5M te testen gebruikten de auteurs eerst realistische computersimulaties van eenvoudige scenes: paren van moleculen en kleine roosters van twaalf moleculen op slechts enkele nanometers afstand. Vergeleken met de momenteel leidende methode, bekend als Gradient Ascent, vond G5M veel meer van de moleculen die zichtbaar zouden moeten zijn bij de theoretische resolutiegrens, terwijl het bijna nooit moleculen rapporteerde die er niet waren. In belangrijke gevallen herkende het nauwgelegen paren zevenentwintig keer vaker dan de oudere methode en verbeterde het de effectieve resolutie met meer dan de helft. Het team bevestigde deze verbeteringen vervolgens experimenteel met DNA‑origami‑structuren—kunstmatige DNA‑vormen met dockingsites op precies bekende posities—waarmee werd aangetoond dat G5M betrouwbaar bijna alle verwachte sites kon tellen en lokaliseren onder verschillende beeldomstandigheden.
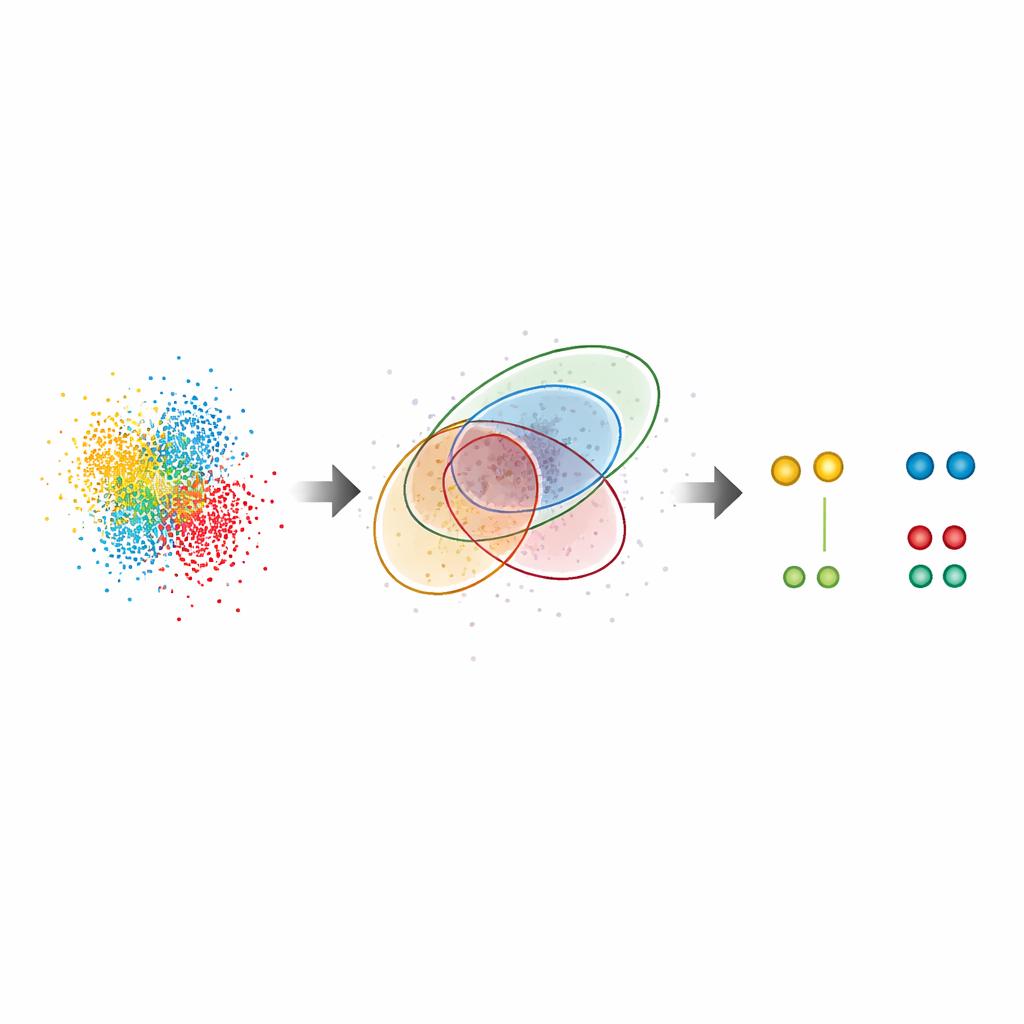
Verborgen patronen in echte cellen onthullen
Buiten testmonsters werd G5M toegepast op complexe biologische systemen. In kernporiecomplexen, de grote poorten in de celkern, reconstrueerde de methode de bekende ringachtige rangschikking van een sleutelproteïne, Nup96, zelfs waar partners slechts ongeveer tien nanometer van elkaar verwijderd waren. Het vond bijna twee keer zoveel eiwitparen als de standaardmethode en reproduceerde onafhankelijke schattingen van label‑efficiëntie, wat suggereert dat het noch veel moleculen mist noch valse toevoegt. De auteurs onderzochten ook CD20, een oppervlakte‑receptor die betrokken is bij bloedkankers en een doelwit van therapeutische antilichamen. Hier onthulde G5M significant meer kleine clusters (dimeren, trimeren en tetrameren) van CD20 op het celmembraan, waardoor duidelijk werd hoe een anti‑kankerantilichaam en gerelateerde geneesvormen deze receptoren herordenen. Het verbeterde zelfs de prestaties van een ultra‑hoge‑resolutiebenadering genaamd RESI, die steunt op het scheiden van signalen over meerdere beeldrondes.
Wat dit betekent voor toekomstige microscopie
Door betrouwbaardere informatie uit bestaande DNA‑PAINT‑gegevens te persen, laat G5M zien dat betere software alleen al nieuwe biologische details kan ontsluiten, zonder dat microscopen of kleurstoffen hoeven te worden gewijzigd. Het algoritme houdt valse detecties uiterst laag terwijl het moleculen oplost die bijna tegen elkaar aanliggen, wat essentieel is bij vragen als hoeveel eiwitten in een complex zitten, hoe ze geplaatst zijn of hoe een geneesmiddel hun rangschikking verandert. Geïntegreerd in het open‑source Picasso‑platform en robuust voor typische instellingen, is G5M gepositioneerd om een standaardhulpmiddel te worden om knipperende fluorescentie om te zetten in betrouwbare moleculaire kaarten, en onderzoekers te helpen de nanoschaalorganisatie van het leven in cellen in kaart te brengen.
Bronvermelding: Kowalewski, R., Reinhardt, S.C.M., Pachmayr, I. et al. Molecular mapping in DNA-PAINT via modified Gaussian Mixture Modeling. Nat Commun 17, 2315 (2026). https://doi.org/10.1038/s41467-026-70198-5
Trefwoorden: superresolutiemicroscopie, DNA‑PAINT, moleculaire kaartvorming, proteïne‑oligomerisatie, beeldanalyse-algoritmes