Clear Sky Science · nl
Tekst-embeddingmodellen leveren gedetailleerde conceptuele kenniskaarten afgeleid van korte meerkeuzequizzen
Zien wat een leerling echt weet
Stel je voor dat een docent een gedetailleerde kaart van alles wat een leerling begrijpt zou kunnen openen — niet slechts een enkele testscores, maar een levend beeld van sterke punten, hiaten en hoe nieuwe ideeën wortel schieten. Deze studie laat zien dat zulke kaarten misschien dichterbij zijn dan we denken. Door korte meerkeuzequizzen te combineren met moderne taalhulpmiddelen die in zoekmachines en chatbots worden gebruikt, tonen de auteurs aan hoe je een handvol antwoorden kunt omzetten in rijke, evoluerende portretten van iemands kennis.
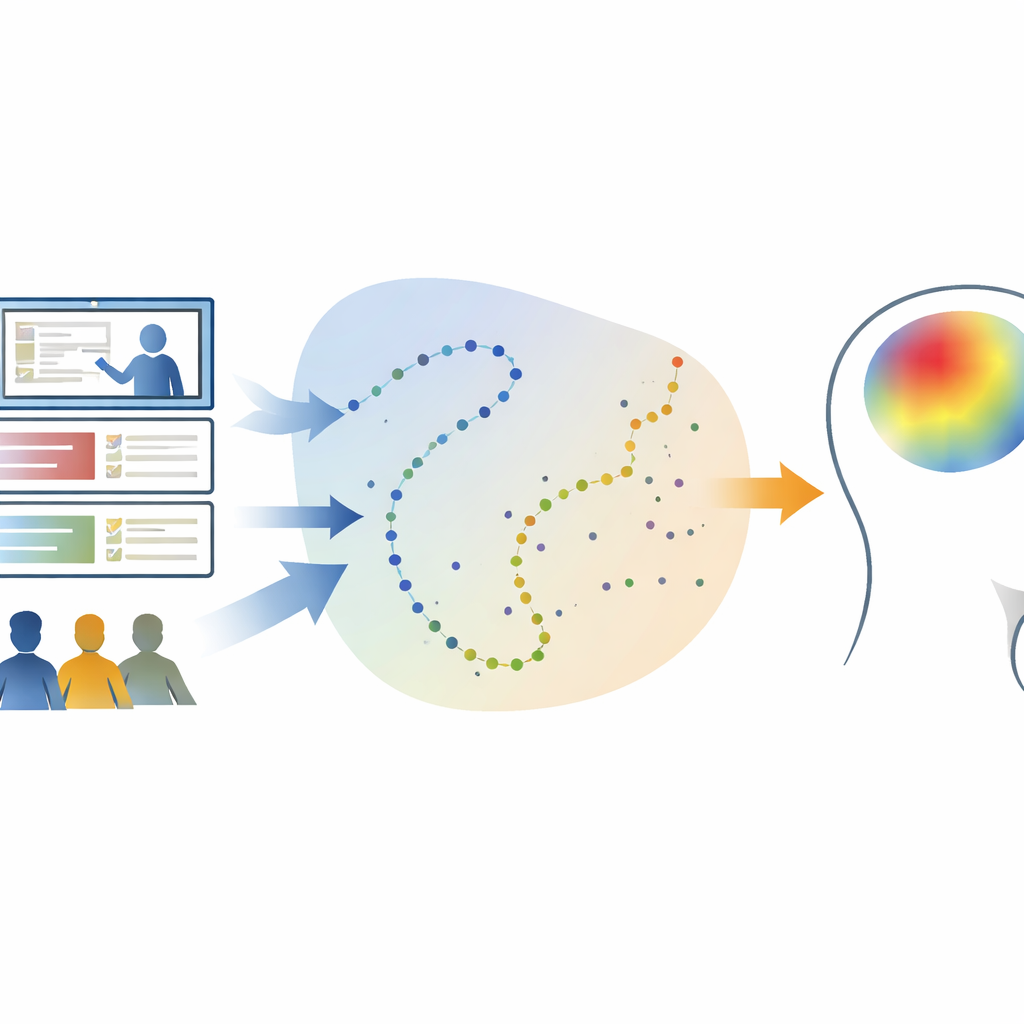
Van eenvoudige quizzen naar rijke leerk kaarten
De meeste toetsen reduceren het werk van een leerling tot een enkel nummer of cijfer. Dat cijfer verbergt veel: twee leerlingen met dezelfde score kunnen heel verschillende dingen weten. De onderzoekers wilden die verborgen details terugwinnen zonder meer toetsen toe te voegen. Hun kernidee is dat elke quizvraag naar bepaalde ideeën verwijst en van andere wegwijst, en dat het patroon van juiste en verkeerde antwoorden over de vragen heen gebruikt kan worden om te reconstrueren wat een leerling waarschijnlijk begrijpt over vele verwante ideeën.
Woorden omzetten in een landschap van ideeën
Om dit te doen gebruikte het team een techniek uit de natuurlijke taalverwerking die tekst weergeeft als punten in een hoge-dimensionale ruimte, waar nabijgelegen punten gerelateerde betekenissen hebben. Ze voerden transcripties van twee Khan Academy natuurkundecolleges — een over de vier fundamentele natuurkrachten en een ander over hoe sterren ontstaan — in een topicmodel dat terugkerende thema’s in de formuleringen ontdekt. Elk kort fragment van het college, en elke quizvraag, werd omgezet in een coördinaat in deze abstracte ruimte. Het resultaat is een soort conceptueel landschap waarin de colleges kronkelende paden tekenen en de vragen als verspreide herkenningspunten verschijnen.
Vragen koppelen aan leermomenten
Met dit landschap in handen konden de auteurs nagaan over welke delen van een college elke vraag eigenlijk ging. Ze vonden dat de meeste vragen sterk overeenkwamen met smalle stroken van het pad van een college, hoewel de vragen niet waren gebruikt om het model te trainen en vaak een andere woordkeuze hadden dan de video’s. Dit stelde hen in staat om te schatten hoeveel elke leerling wist over de inhoud op elk moment van elke video. Door drie korte quizzen te vergelijken die voor, tussen en na de video’s werden afgenomen, konden ze zien hoe kennis over de inhoud van elk college scherp toenam na de bijbehorende video en later op een hoog niveau bleef.
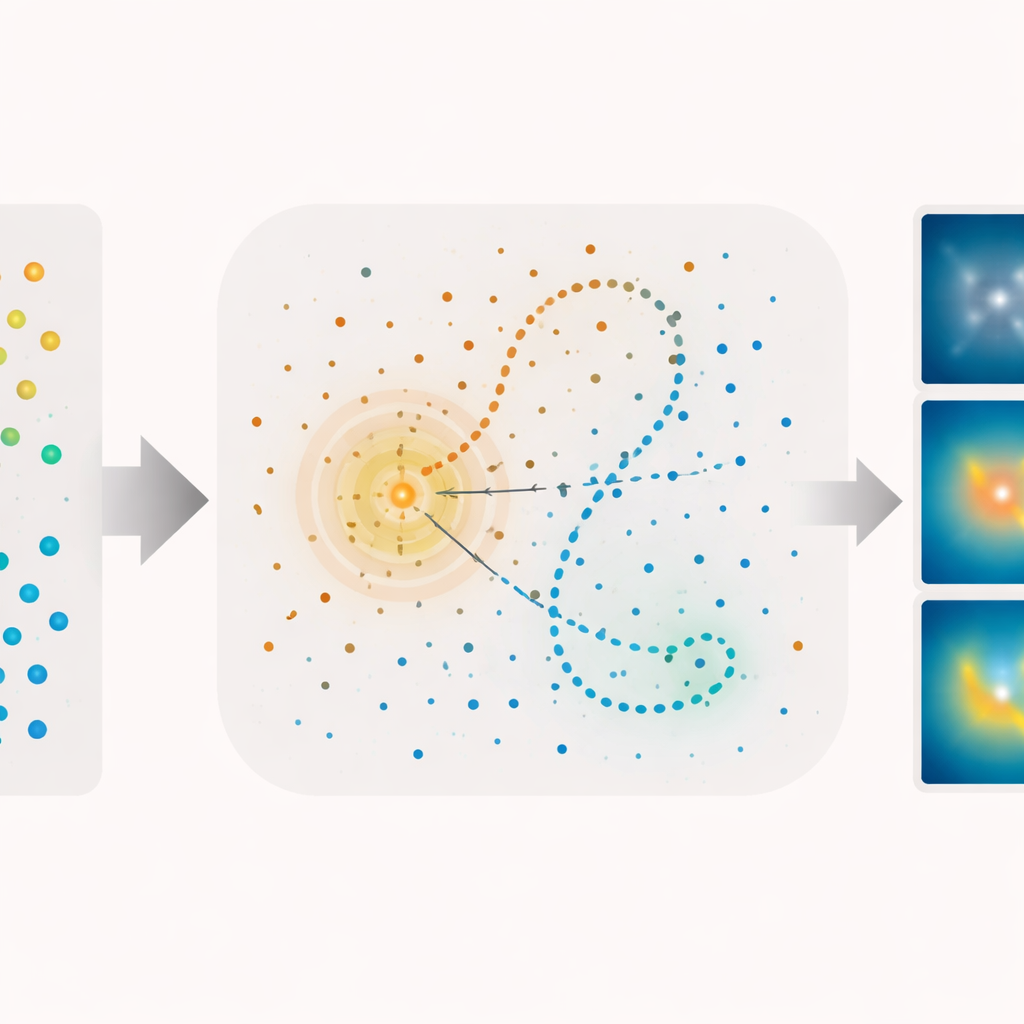
Succes voorspellen en de verspreiding van kennis traceren
Het model deed meer dan het verleden afspelen; het kon ook prestaties voorspellen. Toen de onderzoekers hun kennisramingen gebruikten om te voorspellen of een leerling een bepaalde vraag correct zou beantwoorden, waren de voorspellingen in alle drie de quizzen veel beter dan toeval. Ze onderzochten ook hoe kennis ‘overslaat’ naar nabijgelegen concepten in het landschap. Als een leerling het antwoord op één vraag kende, was de kans groter dat ze ook de antwoorden wisten op andere vragen waarvan de coördinaten dichtbij lagen, en dit voordeel vervaagde geleidelijk met afstand. Ten slotte maakten het team tweedimensionale ‘kenniskaarten’ en ‘leerskaarten’ waarop te zien was waar in de ruimte leerlingen het meest wisten vóór instructie, waar kennis toenam na elk college, en hoe die winst sterk geconcentreerd was rond de daadwerkelijk onderwezen concepten.
Gevolgen voor slimmere onderwijstools
In gewone bewoordingen laat dit werk zien dat een korte, goed ontworpen quiz veel meer kan onthullen dan een ruwe score doet vermoeden. Door cursusmateriaal en vragen in een gedeelde conceptuele ruimte te embedden, zouden docenten — of toekomstige educatieve software — fijnmazige kaarten kunnen bouwen van wat elke leerling begrijpt, hoe dat begrip is georganiseerd en hoe het door de tijd verandert. Zulke kaarten zouden gepersonaliseerde lessen kunnen aansturen die specifieke hiaten aanpakken, nuttige verbindingen tussen ideeën benadrukken en mogelijk zelfs helpen voorspellen hoe gemakkelijk een leerling nieuw materiaal zal begrijpen. Hoewel het huidige kader zich richt op tekst en nog niet alle subtiliteiten van menselijk begrip vangt, biedt het een veelbelovende weg naar evaluatiemethoden die zowel informatiever zijn voor opvoeders als minder belastend voor leerlingen.
Bronvermelding: Fitzpatrick, P.C., Heusser, A.C. & Manning, J.R. Text embedding models yield detailed conceptual knowledge maps derived from short multiple-choice quizzes. Nat Commun 17, 2055 (2026). https://doi.org/10.1038/s41467-026-69746-w
Trefwoorden: conceptueel leren, onderwijstechnologie, tekst-embeddings, adaptief testen, learning analytics