Clear Sky Science · nl
Een 7T fMRI-dataset van synthetische afbeeldingen voor out-of-distribution modellering van visie
Waarom dit belangrijk is voor het begrijpen van visie en AI
Onze ogen nemen elke dag een enorme verscheidenheid aan beelden op, van bossen en gezichten tot verkeersborden en schermruis. Toch zijn veel hersen- en kunstmatige-intelligentiestudies gebaseerd op een smalle doorsnede van deze visuele wereld: foto’s van natuurlijke scènes. Dit artikel introduceert een nieuw soort hersendataset die bewust buiten die comfortzone treedt, en gebruikt zorgvuldig ontworpen synthetische afbeeldingen om zowel onze theorieën over menselijke visie als de daaruit geïnspireerde AI-modellen op de proef te stellen.
Het bouwen van een nieuw visueel testplatform
De auteurs breiden de invloedrijke Natural Scenes Dataset (NSD) uit, waarin ultra‑hoge‑resolutie hersenactiviteit werd vastgelegd met 7‑Tesla MRI terwijl proefpersonen tienduizenden foto’s bekeken. Die oorspronkelijke dataset heeft al bijgedragen aan enkele van de meest nauwkeurige modellen van hoe de visuele cortex op beelden reageert. Omdat alle afbeeldingen echter relatief gewone foto’s zijn, is het lastig te bepalen of een model dat goed presteert op NSD echt algemene principes van visie vastlegt of zich simpelweg heeft gespecialiseerd op dat specifieke type beelden. Om dit aan te pakken scanden de onderzoekers dezelfde acht vrijwilligers opnieuw, dit keer met 284 “synthetische” afbeeldingen die bewust buiten de gebruikelijke fotowereld stappen.
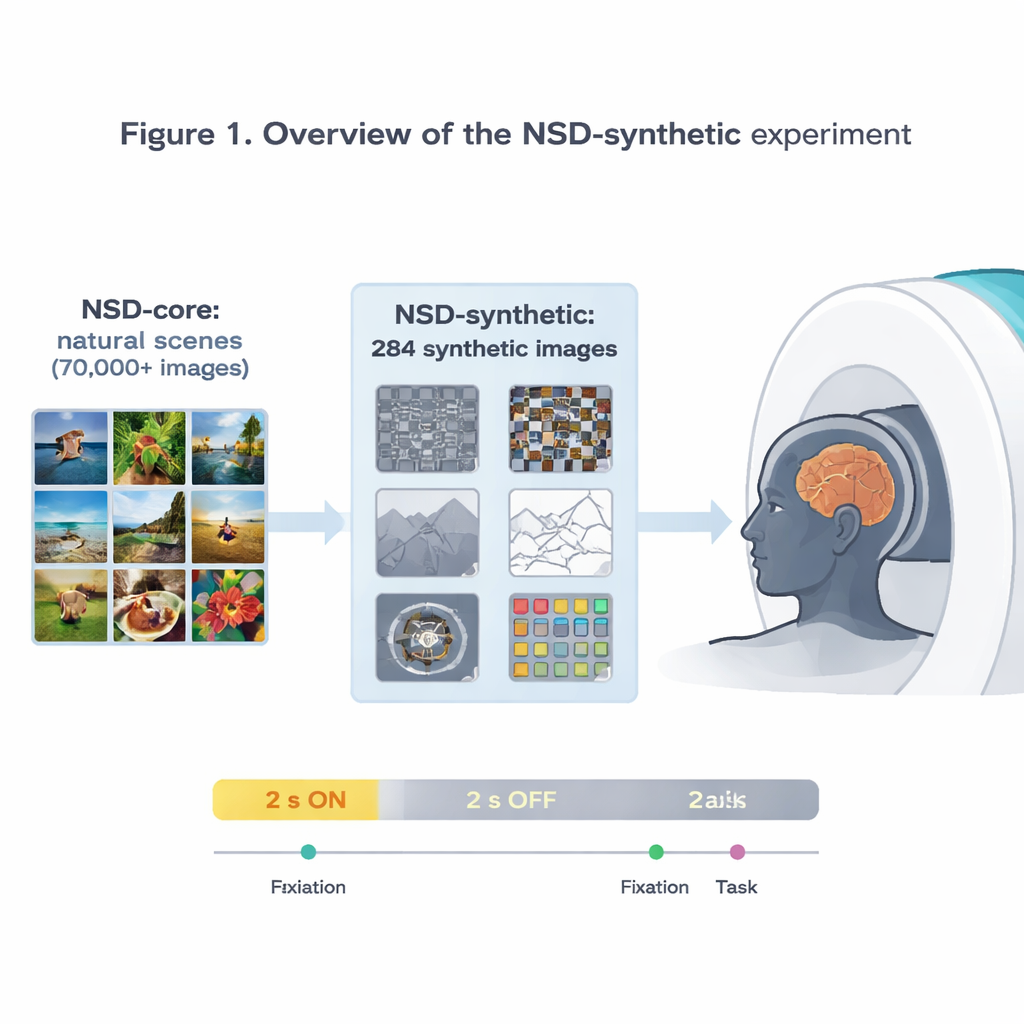
Vreemde afbeeldingen, betrouwbare hersenreacties
De synthetische afbeeldingen bestrijken acht families: verschillende soorten visuele ruis, eenvoudige natuurlijke scènes en hun aangepaste versies (zoals ondersteboven of lijntekeningen), scènes met verminderd contrast of verstoorde fase, afzonderlijke woorden op verschillende posities, spiraalgratings die gevoeligheid voor fijne patronen beproeven, en felgekleurde ruisvlekken. Terwijl deelnemers ofwel op een klein knipperend stipje gericht waren of een eenvoudige beeldvergelijkingstaak uitvoerden, maten de onderzoekers elke 1,6 seconden hersenactiviteit. Ze laten zien dat deze vreemd ogende stimuli toch sterke, betrouwbare signalen produceren, vooral in vroege visuele gebieden die reageren op basiskenmerken zoals randen, contrast en kleur. Activiteitspatronen over de cortex komen overeen met bekende voorkeuren van gespecialiseerde regio’s, zoals een woordselectief gebied dat het sterkst reageert op centraal geplaatste woorden en een scèneselectief gebied dat het meest reageert op omgevingsbeelden.
Aantonen dat de data echt “out of distribution” zijn
Om modellen uit te dagen moeten de hersenreacties in deze nieuwe dataset wezenlijk verschillen van die opgewekt door natuurlijke foto’s. De auteurs comprimeren activiteitspatronen uit zowel de originele NSD- als de synthetische sessie tot een tweedimensionale kaart die weerspiegelt hoe vergelijkbaar reacties zijn over afbeeldingen. In die ruimte clusteren reacties op synthetische afbeeldingen apart van reacties op natuurlijke foto’s, zelfs wanneer rekening wordt gehouden met verschillen tussen scansessies. Bovendien groeperen synthetische afbeeldingen zich vanzelfsprekend naar visueel type—ruis bij ruis, gratings bij gratings, enzovoort—wat aantoont dat de hersenen deze stimuli ordenen volgens hun onderliggende structuur en niet alleen op basis van oppervlakkige verschijningsvorm.
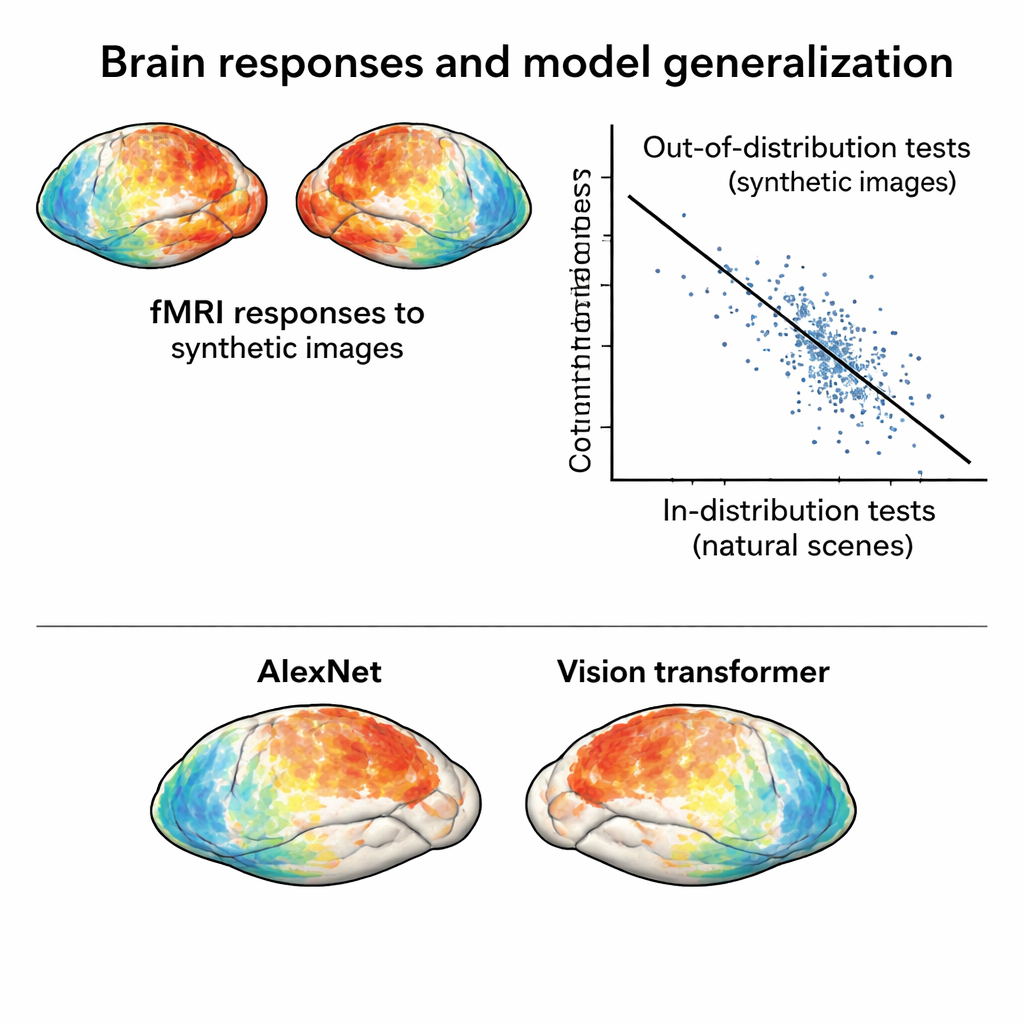
Hersenen en AI-modellen aan een zwaardere test onderwerpen
Met deze nieuwe “out‑of‑distribution” dataset trainde het team standaard encoding-modellen: wiskundige hulpmiddelen die hersenreacties voorspellen uit beeldkenmerken geëxtraheerd door diepe neurale netwerken. Modellen die alleen op de natuurlijke foto’s zijn getraind presteren goed wanneer ze getest worden op vergelijkbare foto’s, maar hun nauwkeurigheid daalt flink bij het voorspellen van reacties op de synthetische afbeeldingen. Die daling komt niet door ruis in de data—de synthetische reacties zijn juist heel zuiver—maar door echte modeltekorten. Cruciaal is dat het vergelijken van verschillende neurale netwerkarchitecturen onder deze strengere omstandigheden contrasten blootlegt die nauwelijks zichtbaar zijn bij in‑distribution tests. Bijvoorbeeld, een moderne vision transformer en een zelfgestuurd netwerk presteren beide beter dan klassieke convolutionele netwerken bij synthetische afbeeldingen, wat suggereert dat de trainingswijze van een model sterk bepaalt hoe robuust het is.
Hoe ver van vertrouwde beelden kunnen modellen gaan?
De auteurs gaan verder en behandelen “afstand” tot de trainingsdata als een continuüm, niet als een ja‑of‑nee‑label. Ze meten hoe ver de hersenreactie op elk beeld ligt van de wolk van reacties op natuurlijke scènes. Hoe verder een synthetische afbeelding in deze ruimte verwijderd is, hoe slechter modellen doorgaans presteren en hoe minder nauwkeurig ze kunnen identificeren welke afbeelding iemand zag op basis van alleen hersenactiviteit. Ze tonen ook aan dat zelfs binnen de wereld van gewone foto’s slim gekozen testsets zich als “licht out of distribution” kunnen gedragen: modellen doen het het beste op afbeeldingen uit dezelfde cluster als hun trainingsset, minder goed op verder verwijderde natuurlijke scènes, en het slechtst op de synthetische stimuli. Dit graduele beeld maakt de nieuwe dataset tot een hulpmiddel om precies te onderzoeken welke vormen van visuele structuur huidige modellen missen.
Wat dit betekent voor toekomstig hersen- en AI-onderzoek
Voor niet‑specialisten is de kernboodschap dat sterke prestaties op vertrouwde afbeeldingen geen garantie zijn dat een door de hersenen geïnspireerd AI-model werkelijk heeft vastgelegd hoe wij zien. Door NSD‑synthetic vrij te geven naast de oorspronkelijke NSD bieden de auteurs een publieke “crashtestbaan” voor visiemodellen: een manier om te zien waar ze falen wanneer de afbeeldingen abstracter, kleurrijker of minder natuurlijk worden. Omdat de dataset openlijk beschikbaar is en nauw geïntegreerd met een bestaande, veelgebruikte bron, zal het waarschijnlijk een standaardbenchmark worden voor het testen en verbeteren van theorieën over menselijke visie en de artificiële netwerken die proberen die na te bootsen.
Bronvermelding: Gifford, A.T., Cichy, R.M., Naselaris, T. et al. A 7T fMRI dataset of synthetic images for out-of-distribution modeling of vision. Nat Commun 17, 1589 (2026). https://doi.org/10.1038/s41467-026-69345-9
Trefwoorden: visuele cortex, fMRI-dataset, synthetische afbeeldingen, out-of-distribution, diepe neurale netwerken