Clear Sky Science · nl
DNA-diamant formuleert een ontbindbaar composietletterconstellatiemodel voor DNA-databewaring
Waarom toekomstige data in DNA zou kunnen leven
Onze telefoons, bedrijven en wetenschappelijke instrumenten genereren gegevens veel sneller dan harde schijven en magneetbanden kunnen meegroeien. DNA—dezelfde molecule die genetische informatie draagt in levende organismen—kan ook worden gebruikt om digitale bestanden in een ongelooflijk compacte, langdurige vorm op te slaan. Dit artikel introduceert een nieuwe manier om nog meer informatie in synthetische DNA-strengen te proppen, terwijl het praktisch en betrouwbaar blijft om terug te lezen, wat DNA-opslag mogelijk goedkoper en beter schaalbaar maakt.
Van vier DNA-letters naar rijkere mengsels
Traditionele DNA-opslag gebruikt de vier natuurlijke DNA-basen—A, T, G en C—om digitale bits te vertegenwoordigen, vergelijkbaar met nullen en enen op een schijf. In dat schema kan elke positie in een DNA-streng maximaal twee bits informatie dragen, omdat er slechts vier keuzes zijn. De auteurs bouwen voort op een opkomend idee: in plaats van op elke positie één enkele base te plaatsen, creëren ze zorgvuldig gecontroleerde mengsels van basen, genaamd composietletters. Bijvoorbeeld: een positie kan bestaan uit een 50:50-mengsel van A en T, of een 25:25:25:25-mengsel van alle vier de basen. Wanneer van elke streng veel kopieën worden gesynthetiseerd, onthult het sequentiëren van deze mengsels de basenverhoudingen en daarmee een digitaal symbool dat meer dan twee bits kan representeren.
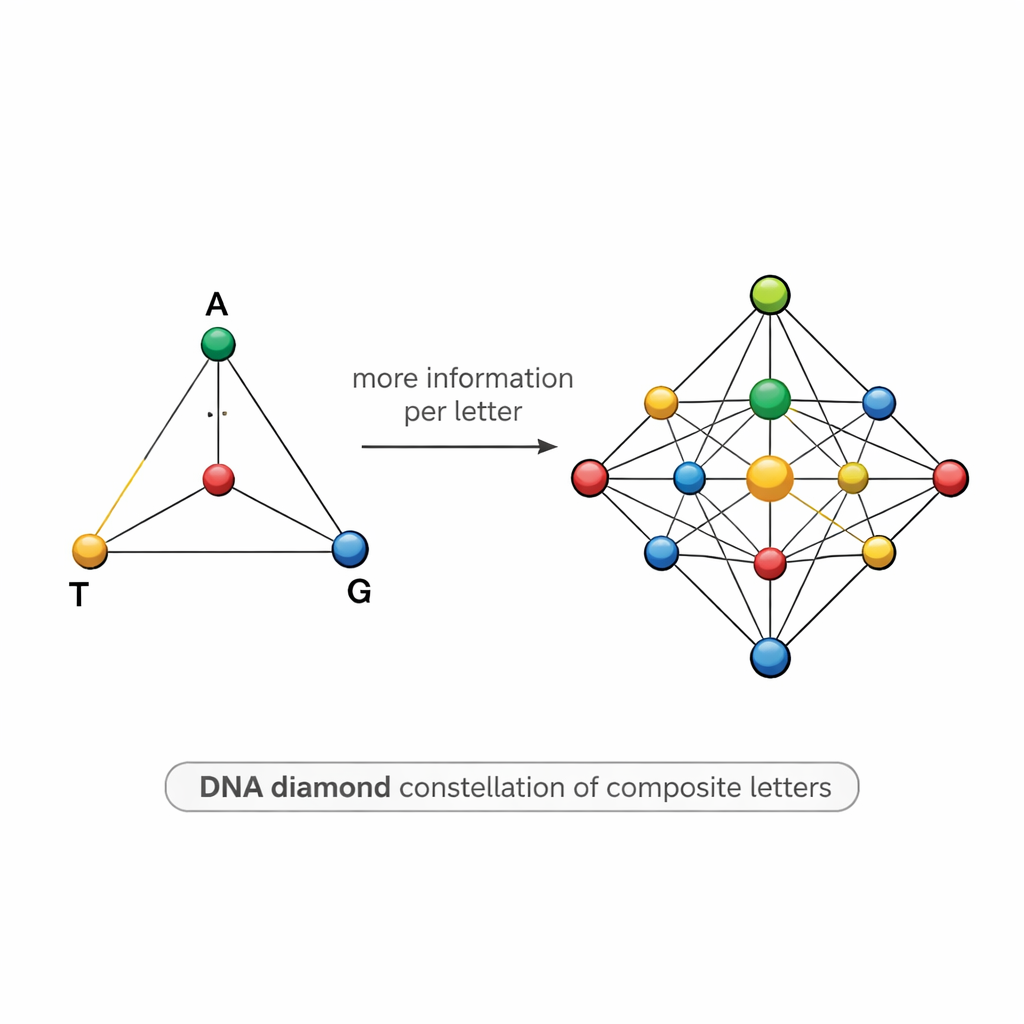
Een diamantvormige kaart van DNA-symbolen
Het ontwerpen van zulke mengsels is lastig. Als twee symbolen te veel op elkaar lijken—bijvoorbeeld het ene is 50% A en 50% T en het andere 55% A en 45% T—kan sequentiegeluid ze vervagen, fouten veroorzaken en wetenschappers dwingen veel meer kopieën te sequencen dan wenselijk. Om dit aan te pakken stelt het team een gestructureerd “DNA-diamant” model voor: een set van 15 composietletters gerangschikt als punten op een tetraëder waarvan de hoeken A, T, G en C zijn. De set bevat pure basen in de hoeken, gelijke mengsels van twee basen langs de randen, mengsels van drie basen op elk vlak, en een perfect gelijkmatig mengsel van alle vier basen in het midden. Deze zorgvuldig gekozen constellatie verhoogt de theoretische informatie per positie tot ongeveer 3,9 bits, terwijl de symbolen voldoende onderscheidend blijven om praktisch uit elkaar te houden.
Slimmer decoderen met entropie en indexering
Data teruglezen uit DNA betekent afleiden welke composietletter bedoeld was op elke positie aan de hand van ruisige metingen van basenfrequenties. De auteurs lenen een strategie uit de telecommunicatie die setpartitionering wordt genoemd. Eerst bekijken ze hoe “gemengd” een positie lijkt, gebruikmakend van een grootheid die entropie wordt genoemd en laag is voor zuivere basen en hoger voor complexe mengsels. Dit wijst snel elke positie toe aan een van vier groepen: zuivere basen, twee-basismengsels, drie-basismengsels of het vier-basismengsel. Vervolgens kiest binnen de geselecteerde groep een nauwkeurigere waarschijnlijkheidsberekening de meest waarschijnlijke letter. Deze tweeledige aanpak vermindert verwarring tussen symbolen en verkort de rekentijd vergeleken met eerdere methoden. Om verder te voorkomen dat strengen met elkaar worden verward, draagt elk DNA-fragment foutbestoorde indexsequenties aan beide uiteinden en worden reads met de verkeerde lengte—vaak veroorzaakt door insertie- of deletiefouten—gefilterd voordat decodering begint.
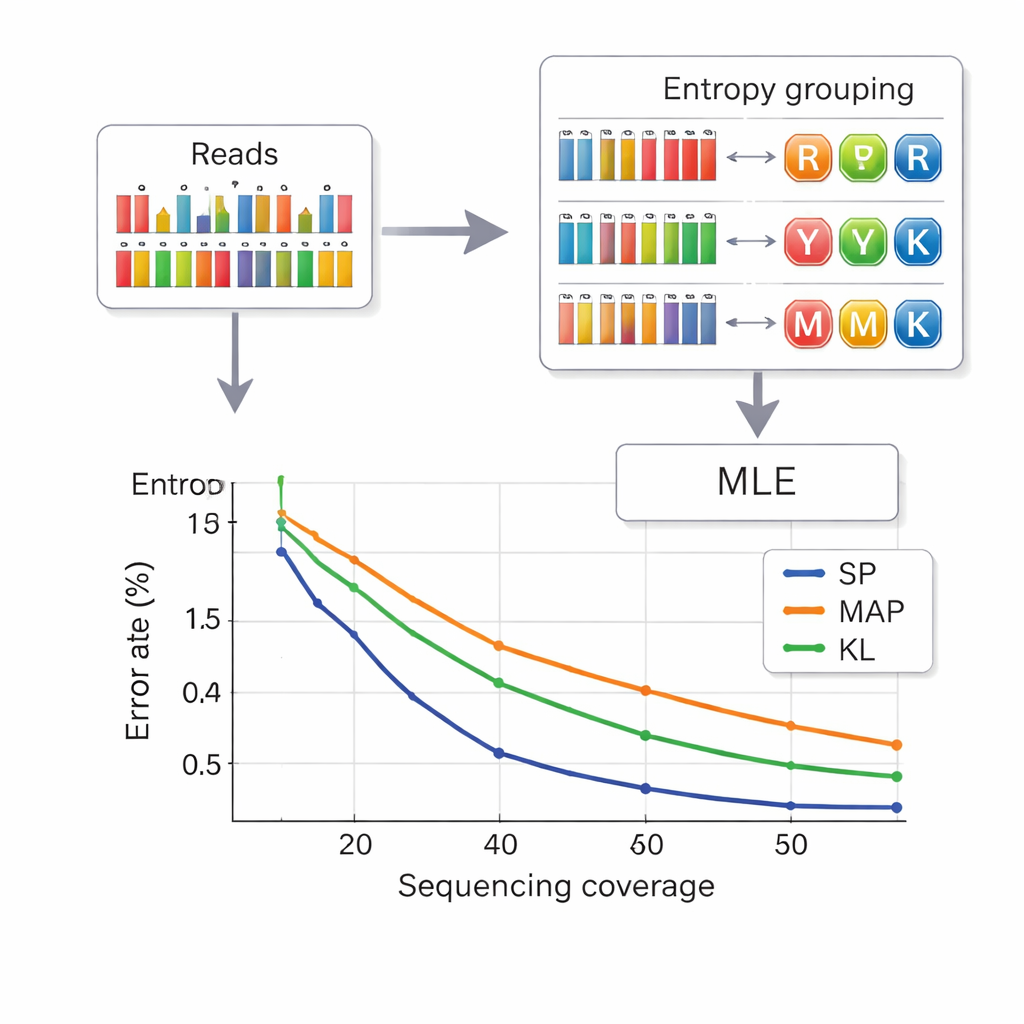
Meer data verpakken met minder reads
De onderzoekers testten hun systeem in zowel kleine als grote DNA-pools, gebruikmakend van commerciële synthesefaciliteiten. Met een achtletterig composietalfabet bereikten ze een payloaddichtheid van 2,5 bits per DNA-positie en konden ze bestanden perfect terugwinnen met gemiddeld 14 sequentie-reads per streng—betere dichtheid dan eerdere zessymboolschema’s terwijl er minder reads nodig waren. Met het volledige 15-letter DNA-diamantalfabet behaalden ze 3,125 bits per positie voor de hoofddata en herstelden nog steeds alles foutloos bij 33-voudige dekking. Simulaties en experimenten toonden ook aan dat hun entropiegebaseerde methode bijna even goed presteert als de meest accurate, maar tragere, decoderingstechniek, en duidelijk beter dan oudere technieken, vooral bij lagere sequentiedieptes.
Wat dit betekent voor toekomstig geheugen
Voor een lekenlezer is de kernboodschap dat de auteurs een manier hebben gevonden om DNA “nieuwe trucjes” te leren zonder nieuwe chemie uit te vinden: door de bestaande vier basen slim te mengen en ze slimmer te decoderen, kunnen ze meer bits per molecule opslaan terwijl ze de kosten beheersen. Hun diamantvormige alfabet, gecombineerd met robuuste indexering en foutcorrectie, laat zien dat hoogcapacitaire DNA-databewaring mogelijk is met relatief bescheiden sequentie-inspanning. Naarmate DNA-synthese en -sequentiëring goedkoper blijven worden, kunnen dergelijke ontwerpen helpen om DNA van een laboratoriumcuriosum te transformeren tot een realistisch medium voor het archiveren van ’s werelds digitale herinneringen.
Bronvermelding: Ge, Q., Ren, M., Qi, T. et al. DNA diamond formulates a decomposable composite letter constellation model for DNA data storage. Nat Commun 17, 1704 (2026). https://doi.org/10.1038/s41467-026-68861-y
Trefwoorden: DNA-databewaring, composietletters, informatiedichtheid, foutcorrectie, digitale archivering