Clear Sky Science · nl
Terugkerende verbindingen vergemakkelijken herkenning van bedekte objecten door "explaining-away"
Hoe de hersenen zien wat er niet is
In het dagelijks leven herkennen we moeiteloos voorwerpen die deels verborgen zijn—een kat achter een gordijn, een auto achter een boom. Dit artikel onderzoekt hoe hersenen, en door de hersenen geïnspireerde kunstmatige netwerken, dit voor elkaar krijgen. De auteurs tonen aan dat schakelingen met feedbacklussen informatie over het bedekkende object kunnen gebruiken om mentaal in te vullen wat erachter zit, en onthullen zo een belangrijke truc waarop ons visueel systeem mogelijk vertrouwt wanneer de wereld rommelig en onvolledig is.
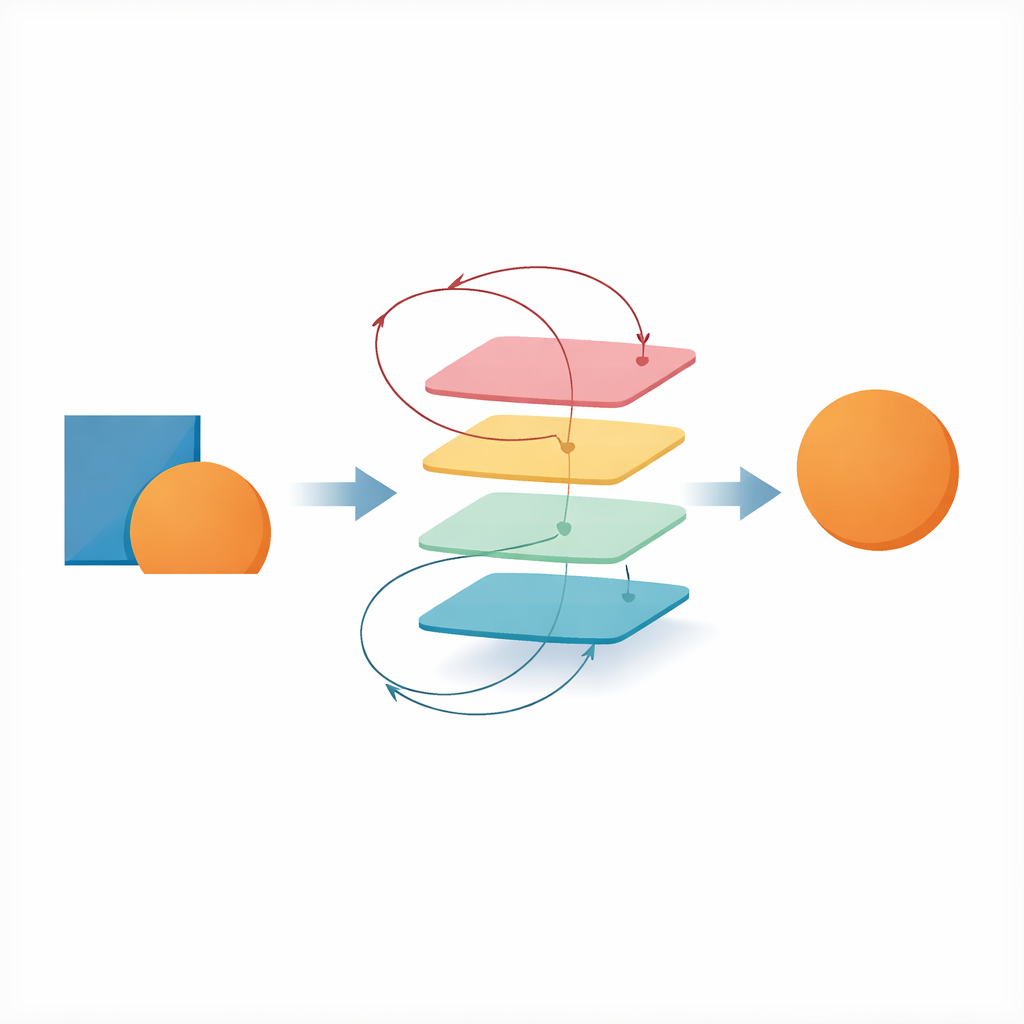
Waarom verborgen objecten een moeilijk probleem zijn
Wanneer een object geoccludeerd is, ontbreken veel van zijn gebruikelijke visuele kenmerken of zijn ze vervormd. Een eenvoudig feedforward visueel systeem, waarbij informatie rechtstroomt van ogen naar herkenningscentra, moet het verborgen object raden op basis van alleen de zichtbare fragmenten. Biologische hersenen zijn echter vol met recurrente verbindingen—lussen waarbij hogere gebieden terugpraten naar eerdere. Men vermoedde al lang dat zulke lussen helpen bij lastige taken zoals het herkennen van geoccludeerde objecten, maar het was onduidelijk welk voordeel ze precies bieden of hoe ze de interne representaties van wat we zien veranderen.
Brain-geïnspireerde netwerken op de proef gesteld
De auteurs bouwden een uitgebreide batterij diepe convolutionele netwerken die stadia van visuele verwerking nabootsen. Sommige waren puur feedforward, terwijl andere recurrente lussen of extra top-down feedback hadden. Ze trainden deze modellen op aangepaste afbeeldingssets waarin het ene modevoorwerp deels het andere bedekte. De netwerken moesten zowel het voorste (occluderende) als het achterste (geoccludeerde) voorwerp identificeren onder verschillende taakopzetten. De prestatie hing minder af van of een netwerk recurrent of feedforward was en meer van zijn "computationele diepte"—hoeveel opeenvolgende verwerkingsstappen een invoer doorliep. Diepe feedforwardmodellen konden het in de basistaak opnemen tegen of zelfs beter presteren dan recurrente modellen, wat laat zien dat recursie op zichzelf niet magisch superieur is.
Een speciale truc: het occluder verklaren (explaining away)
Hoewel diepte het belangrijkst was voor ruwe nauwkeurigheid, toonden recurrente netwerken een kenmerkend voordeel in hoe ze context gebruikten. Wanneer deze netwerken eerst werd gevraagd het voorste object te identificeren en pas daarna het verborgen object, verbeterde hun prestatie op het verborgen object vergeleken met wanneer ze het alleen classificeerden. Dit patroon verscheen niet in gewone feedforwardnetwerken die beide labels tegelijk uitvoerden. De auteurs interpreteren dit als "explaining away": zodra het systeem de occluder heeft herkend, kan het de vreemde, ontbrekende kenmerken in de afbeelding toeschrijven aan die occluder, in plaats van ze te zien als bewijs voor een merkwaardig nieuw object. In realistischer 3D-scenes en in een primaat-geïnspireerd model (CORnet) gaf dezelfde volgorde—voorwerp vooraan vóór het verborgen voorwerp—ook een verbeterde herkenning.
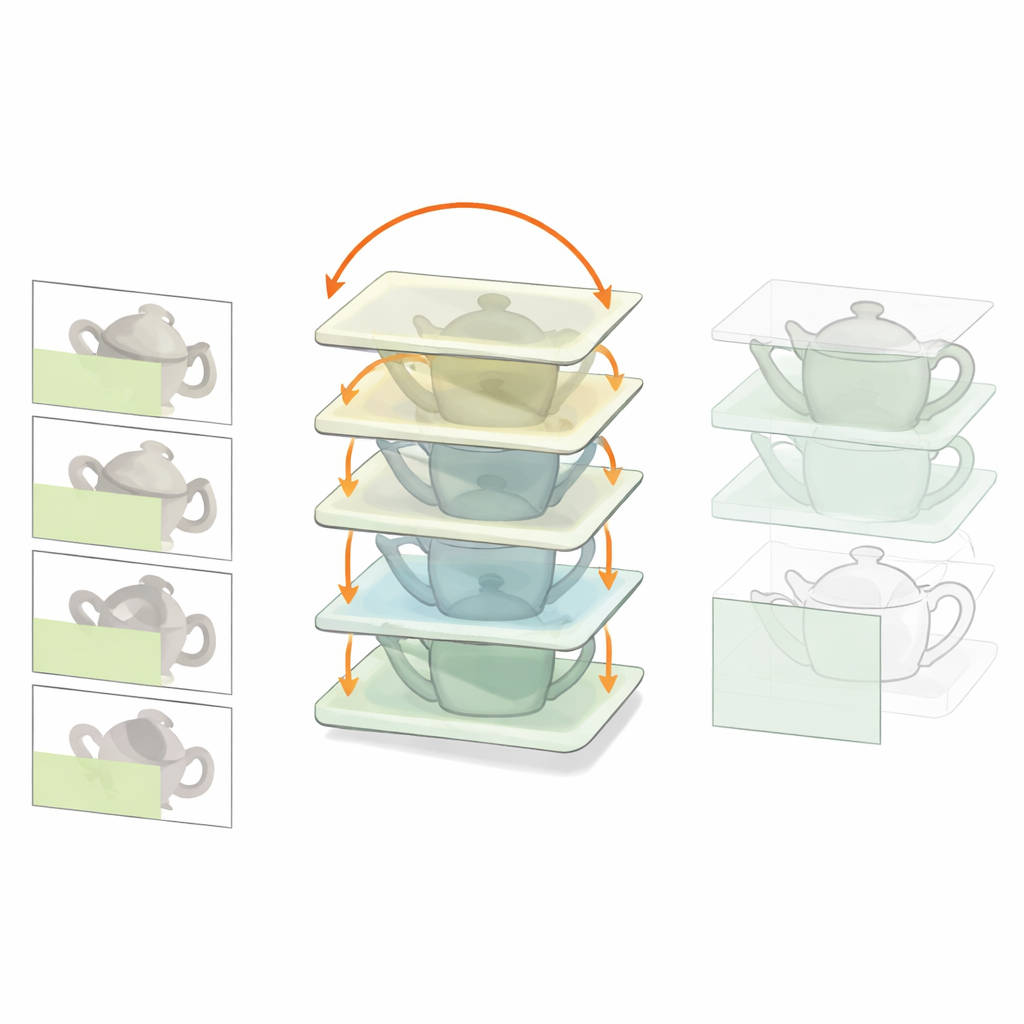
Hetzelfde effect zien bij mensen
Om te onderzoeken of mensen een vergelijkbare strategie gebruiken, voerden de onderzoekers een online experiment uit. De deelnemers zagen kort een enkel object, daarna een scène waarin het ene object het andere bedekte, en moesten uiteindelijk kiezen welke van twee opties het verborgen object was. In sommige proefjes was het aanvankelijke enkele object hetzelfde als de latere occluder; in andere was het ongelijk. Wanneer mensen net de werkelijke occluder hadden gezien, identificeerden ze het verborgen object nauwkeuriger en reageerden ze sneller, over een reeks occlusieniveaus. Dit suggereert dat onze hersenen, net als de recurrente netwerken, profiteren van het eerst verwerken van het blokkerende voorwerp en vervolgens die kennis gebruiken om het gedeeltelijke bewijs voor wat erachter ligt te interpreteren.
Verborgen beelden van binnenuit herbouwen
Om dieper op het mechanisme in te gaan, ontwierpen de auteurs een meer biologisch geïnspireerd model, Recon-Net, losjes gebaseerd op interacties tussen visuele cortex en prefrontale cortex. Recon-Net ontvangt een afbeelding met een geoccludeerd object plus een afzonderlijke weergave van de occluder en transformeert iteratief een interne representatie totdat deze overeenkomt met hoe een niet-geoccludeerde versie van het verborgen object eruit zou moeten zien. Opvallend is dat classifiers die alleen op schone, niet-geoccludeerde afbeeldingen zijn getraind, de outputs van Recon-Net bijna even goed kunnen herkennen als wanneer ze direct op geoccludeerde voorbeelden waren getraind. Dit betekent dat de recurrente verwerking effectief een schone interne weergave van het verborgen object "herstelt", ook al ontbreken de pixels.
Wat dit betekent voor hersenen en machines
Samengevat laat de studie zien dat feedbacklussen niet alleen over ruwe prestatie gaan, maar over een kwalitatief andere manier om context te gebruiken. Recurrente verbindingen ondersteunen van nature explaining-away: ze stellen het visuele systeem in staat te verklaren hoe een occluder vervormt wat we zien en om een stabiele interne representatie van het verborgen object te herstellen. Tegelijkertijd vinden de auteurs dat trainen op zwaar geoccludeerde beelden reacties op duidelijke beelden grotendeels ongewijzigd kan laten, wat leren in echte hersenen kan vergemakkelijken door constante herbedrading te vermijden. Deze inzichten wijzen op een gemeenschappelijk principe voor zowel neurowetenschap als kunstmatige intelligentie: wanneer de wereld informatie verbergt, kijken slimme systemen niet alleen harder—ze infereren waarom die informatie ontbreekt.
Bronvermelding: Kang, B., Midler, B., Chen, F. et al. Recurrent connections facilitate occluded object recognition by explaining-away. Nat Commun 17, 2225 (2026). https://doi.org/10.1038/s41467-026-68806-5
Trefwoorden: herkenning van bedekte objecten, recurrente neurale netwerken, visuele waarneming, explaining away, computationele neurowetenschap