Clear Sky Science · nl
Betrouwbare voorspelling van Enzyme Commission-nummers met een hiërarchische interpreteerbare transformer
Waarom het voorspellen van enzymtaken belangrijk is
Elke levende cel draait op talloze kleine chemische machines die enzymen worden genoemd. Elk enzym heeft een specifieke “taak”, en die taak wordt gecodeerd in een Enzyme Commission (EC)-nummer, een vierdelige code die een beetje lijkt op een postadres. Het correct toewijzen van EC-nummers is cruciaal om metabolisme te begrijpen, nieuwe medicijnen te ontwerpen, microben te ontwerpen die brandstoffen of alternatieven voor plastics produceren, en te volgen hoe ecosystemen chemicaliën verwerken. Maar experimenten om enzymfuncties vast te stellen zijn traag en duur. Deze studie introduceert HIT-EC, een nieuw kunstmatig-intelligentiesysteem dat betrouwbaar EC-nummers kan voorspellen uit eiwitsequenties en tegelijk uitlegt waarom het een bepaalde voorspelling heeft gedaan.
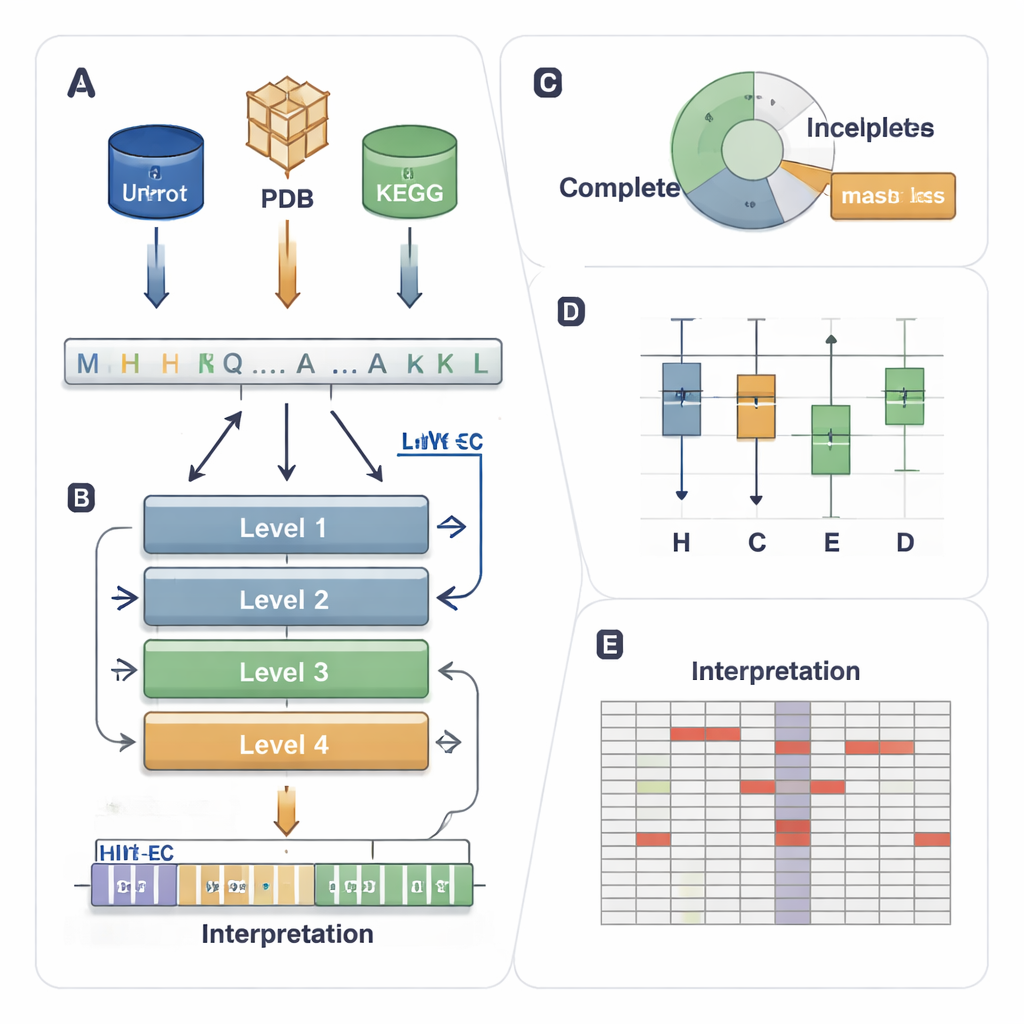
Een postcode-systeem voor enzymtaken
Het EC-systeem kent elk enzym een vierledig nummer toe, bijvoorbeeld 1.1.1.37. Het eerste cijfer geeft een brede klasse aan (bijvoorbeeld enzymen die elektronen verplaatsen of groepen overdragen), en de latere cijfers beschrijven preciezere reactiedetails. Deze hiërarchie is krachtig maar creëert ook een veeleisend voorspellingsprobleem: een model moet alle vier niveaus correct hebben uit duizenden mogelijke codes, zelfs wanneer sommige enzymen zeldzaam zijn of slechts deels zijn geannoteerd in databases (bijvoorbeeld 3.5.-.-, waarbij de gedetailleerde niveaus ontbreken). Bestaande computermethoden gebruiken ofwel 3D-structuur, sequentiegelijkheid of deep learning, maar ze hebben vaak moeite met ongewone enzymen, negeren deels gelabelde data en functioneren meestal als “black boxes” die weinig inzicht bieden in waarom ze een beslissing nemen.
Een vierlaagse AI die de EC-ladder volgt
HIT-EC (Hierarchical Interpretable Transformer for EC prediction) is opgezet om de vierstaps EC-hiërarchie te weerspiegelen. Het neemt een rauwe eiwitsequentie en voert die door vier transformerlagen, waarvan elke laag zich richt op één EC-niveau. Lokale verbindingen koppelen elk niveau aan het voorgaande, zodat een fijnmazige beslissing (het vierde cijfer) consistent moet zijn met bredere beslissingen (het eerste en tweede cijfer). Parallel daaraan houdt een globale stroom de volledige sequentiecontext op elk stadium zichtbaar. Het model kan ook getraind worden op sequenties met onvolledige labels door een “gemaskeerde loss” te gebruiken die ontbrekende EC-niveaus negeert in plaats van de sequentie weg te gooien. Dit stelt HIT-EC in staat te leren van het grote aandeel eiwitten in gecureerde databases dat slechts deels geannoteerd is.
Rivals overtreffen qua nauwkeurigheid en snelheid
De auteurs stelden een grote, zorgvuldig gefilterde dataset samen van ongeveer 200.000 enzymen met 1.938 verschillende EC-codes uit Swiss-Prot en de Protein Data Bank. In herhaalde hold-out tests versloeg HIT-EC drie toonaangevende methoden (CLEAN, ECPICK en DeepECtransformer) op zowel overall als per-klasse F1-scores, die de balans meten tussen juiste treffers en valse alarmen. Het presteerde vooral sterk op ondervertegenwoordigde EC-codes met 25 of minder bekende voorbeelden, waar eerdere methoden vaak tekortschoten. HIT-EC generaliseerde ook goed naar nieuwe enzymen die na de training aan Swiss-Prot werden toegevoegd en naar volledige genomen van diverse bacteriën, waaronder goed bestudeerde stammen van Escherichia coli, Bacillus subtilis en Mycobacterium tuberculosis. Ondanks zijn complexiteit was het model zeer efficiënt: op een standaard GPU verwerkte het een eiwit in ongeveer 38 milliseconden—tientallen malen sneller dan sommige concurrenten die afhankelijk zijn van trager soortgelijkheidszoeken of ensembles van veel modellen.
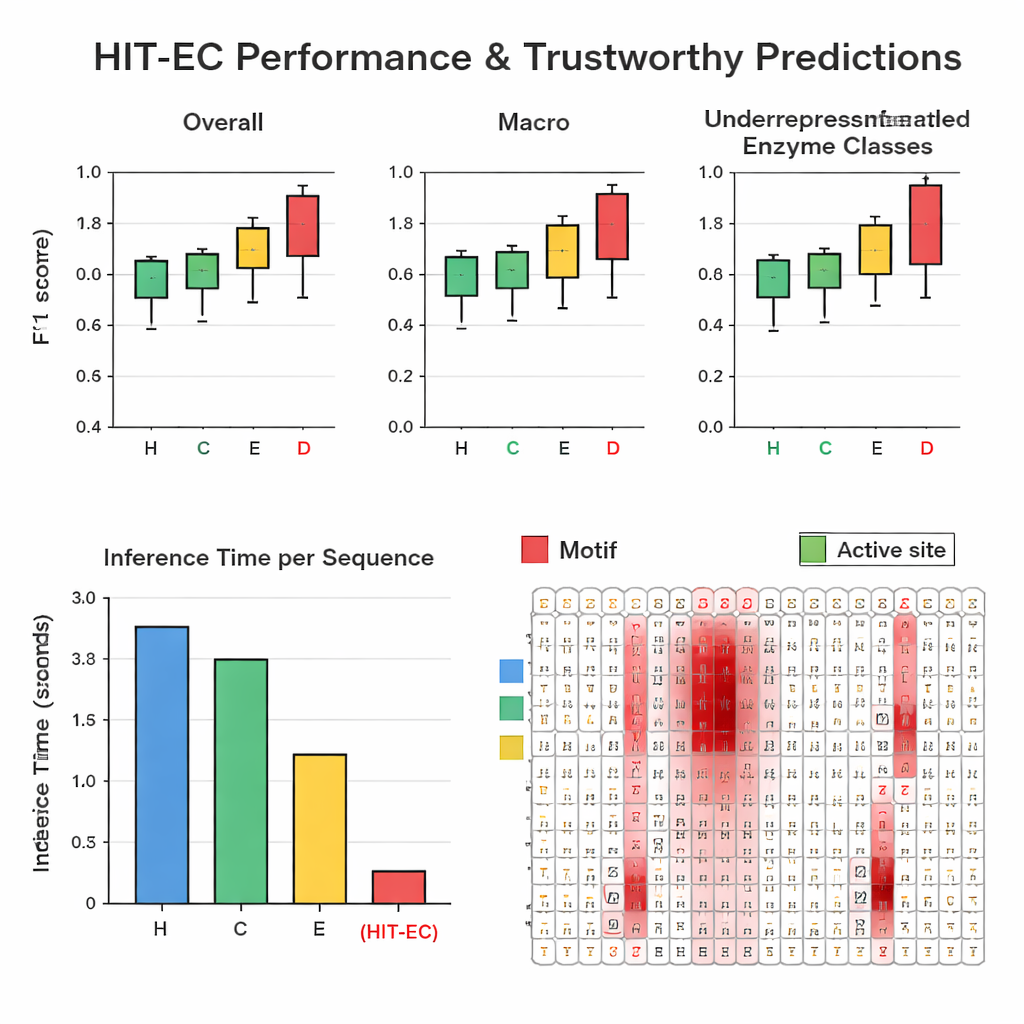
Zien waar het model "naar kijkt"
Om zijn voorspellingen betrouwbaar te maken, is HIT-EC zo ontworpen dat het toont welke aminozuren in de sequentie elke EC-niveaubeslissing hebben beïnvloed. De auteurs bouwden een interpretatiepad dat attentiegewichten combineert met gradientinformatie om te scoren hoe belangrijk elke positie is. Ze valideerden deze scores op goed gekarakteriseerde enzymfamilies. Bijvoorbeeld, in een cytochroom P450-familie (CYP106A2) benadrukte HIT-EC bekende functionele motieven zoals zuurstofbindende en heembindende regio’s, en identificeerde een subtiel EXXR-motief dat één benchmarkmodel miste. Voor klassieke vertegenwoordigers van elke topniveau EC-klasse—zoals alcoholdehydrogenase, hexokinase en carbonanhydrase—lichtten de relevantiescores van het model de leerboekachtige signatuurmotieven en substraatbindingsplaatsen op. Deze interpretaties leveren biochemisch “bewijs” dat het model zijn beslissingen baseert op betekenisvolle kenmerken, niet op toevallige correlaties.
Werk sturen aan zeldzame en opkomende enzymen
Het team testte HIT-EC verder op twee weinig bestudeerde enzymen die belangrijk zijn voor vervuilingsopruiming: een cytochroom P450 betrokken bij de afbraak van aromatische verontreinigingen, en een PET-afbrekende hydrolase van Streptomyces die helpt bij het verteren van plasticgerelateerde moleculen. Beide enzymen waren experimenteel gekarakteriseerd maar misten officiële EC-toewijzingen. HIT-EC voorspelde correct de verwachte EC-nummers en benadrukte motiefpatronen en katalytische residuen die overeenkomen met wat bekend is uit structurele en biochemische studies. Over het geheel genomen toont het werk aan dat HIT-EC niet alleen EC-nummers nauwkeuriger en sneller kan toewijzen dan huidige tools, vooral voor zeldzame functies, maar ook kan toelichten waarom een bepaald enzym wordt geacht een gegeven chemische taak uit te voeren. Deze combinatie van prestatie en interpreteerbaarheid maakt het een veelbelovende motor voor grootschalige, betrouwbare enzymannotatie in genomica, biotechnologie en milieuwetenschap.
Bronvermelding: Dumontet, L., Han, SR., Lee, J.H. et al. Trustworthy prediction of enzyme commission numbers using a hierarchical interpretable transformer. Nat Commun 17, 1146 (2026). https://doi.org/10.1038/s41467-026-68727-3
Trefwoorden: voorspelling van enzymfunctie, deep learning in de biologie, transformer-modellen, eiwitannotatie, bioremediatie-enzymen