Clear Sky Science · nl
Inverse-ontworpen nanofotonische neurale netwerkversnellers voor ultracompact optisch rekenen
Waarom het verkleinen van computers van licht ertoe doet
Moderne kunstmatige intelligentie draait op omvangrijke elektronische hardware die enorme hoeveelheden energie verbruikt en warmte genereert. Deze studie verkent een heel ander pad: het gebruiken van piepkleine lichtpatronen op een chip, in plaats van elektronenstromen, om delen van neurale netwerkberekeningen uit te voeren. De auteurs tonen aan dat ze door licht op nanoschaal te "vormen" ultracompacte optische versnellers kunnen bouwen die handgeschreven cijfers en medische beelden herkennen, terwijl ze veel minder ruimte en in principe veel minder energie vergen dan de huidige elektronica.
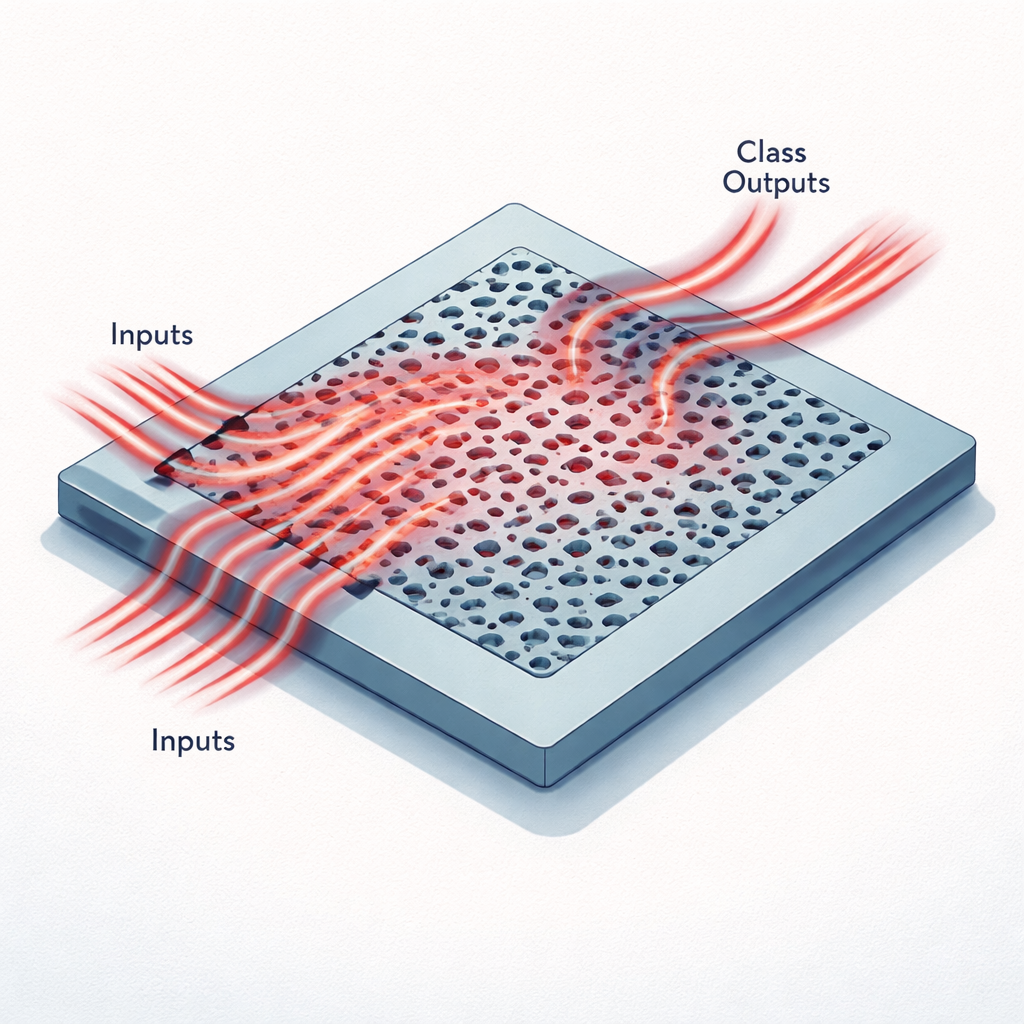
Mini‑chips die denken met licht
In plaats van draden en transistors gebruiken deze versnellers een vlak stuk silicium dat is geëtst met gaatjes en kanalen kleiner dan de golflengte van infraroodlicht. Gegevens uit een afbeelding worden eerst samengeperst tot een kleine reeks getallen, die vervolgens worden gecodeerd als de helderheid van licht dat meerdere smalle golfgeleiders binnenkomt op één telecommunicatiewaarneming. Terwijl dit licht de gepatroneerde regio in stroomt, wordt het verstrooid, interfereert het met zichzelf en wordt het omgeleid naar een handvol uitvoergolfgeleiders. Elke uitgang komt overeen met een mogelijke klasse, zoals een van de tien cijfers in de MNIST-dataset of een van de zes categorieën in een medische beeldset genaamd MedNIST. Het patroon van optische vermogens bij de uitgangen vervult dezelfde rol als de laatste laag van een digitaal neuraal netwerk.
Algoritmes het optische blauwdruk laten tekenen
Het met de hand ontwerpen van zo’n structuur zou praktisch onmogelijk zijn, omdat elk klein "voxel" materiaal kan veranderen hoe licht beweegt. De onderzoekers gebruiken in plaats daarvan een inverse‑ontwerpbenadering: ze beginnen met een willekeurig patroon van silicium en glas, simuleren hoe licht er driedimensionaal doorheen voortplant, en passen vervolgens het patroon aan om een verliesfunctie te verkleinen die classificatiefouten meet. Ze benutten de lineariteit van de Maxwellvergelijkingen—de wetten die licht beheersen—om deze training efficiënt te maken. In plaats van iedere trainingsafbeelding afzonderlijk te simuleren, simuleren ze elk inputkanaal één keer en reconstrueren dan de velden voor alle afbeeldingen als lineaire combinaties van deze vooraf berekende velden. Een wiskundige techniek genaamd de adjointmethode levert vervolgens exacte gradiënten die het algoritme vertellen hoe elk voxel een beetje verschoven moet worden om de prestatie te verbeteren.

Compacte beeldclassificatoren op een zandkorrel
Met deze strategie ontwierp het team twee nanofotonische neurale netwerkversnellers op een standaard silicon‑on‑insulatorplatform. De ene, slechts 20 bij 20 micrometer groot, classificeert handgeschreven cijfers uit de MNIST-dataset; de andere, 30 bij 20 micrometer, classificeert medische beelden uit MedNIST. In simulaties behaalden deze mini‑apparaten respectievelijk nauwkeurigheden van 97,8% en 99,1%. Gefabriceerde versies van dezelfde ontwerpen, getest met echte lasers en detectoren, bereikten 89% nauwkeurigheid voor MNIST en 90% voor MedNIST—indrukwekkende cijfers gezien de minuscuule omvang van de chips. De optische structuren herbergen ruwweg 160.000 tot 240.000 trainbare parameters in gebieden kleiner dan een stofdeeltje, wat neerkomt op ongeveer 400 miljoen parameters per vierkante millimeter.
Gebouwd voor snelheid, efficiëntie en schaal
Aangezien de apparaten passief zijn—er zijn geen bewegende onderdelen of herprogrammeerbare elementen tijdens inferentie—hebben ze nadat ze zijn gefabriceerd geen voortdurende afregeling nodig. De "gewichten" van het neurale netwerk zitten vast in de geometrie van de nanostructuur, zodat berekening plaatsvindt met de snelheid van het licht en in wezen in‑geheugen: licht komt binnen met gecodeerde gegevens en verlaat het apparaat al vermengd tot klasscores. De trainmethode is ook ontworpen om schaalbaar te zijn. Elke optimalisatiestap vereist slechts een vast aantal full‑physics‑simulaties bepaald door het aantal ingangen en uitgangen, niet door de omvang van de dataset, en deze simulaties kunnen over meerdere grafische verwerkingseenheden worden verdeeld. De auteurs schetsen verder hoe meerdere zulke optische kernen gestapeld kunnen worden met fotodetectoren ertussen, vergelijkbaar met lagen in een diep neuraal netwerk, en hoe multiplexen in golflengte of tijd de doorvoer kan verhogen.
Wat dit betekent voor toekomstige AI‑hardware
In eenvoudige termen laat dit werk zien dat het mogelijk is om op maat gemaakte stukjes glas en silicium te "groeien" die zich gedragen als gespecialiseerde neurale netwerklagen, allemaal binnen een oppervlak klein genoeg om er honderden of duizenden van op één enkele chip te plaatsen. Hoewel volledig optische computers nog aan de horizon liggen, zouden deze inverse‑ontworpen nanofotonische versnellers enkele van de energie‑intensiefste delen van AI‑workloads van elektronische processors kunnen overnemen. Gecombineerd met snelle modulatoren, detectoren en slim systeemontwerp wijzen ze op compacte, energiezuinige hardware waarin licht, in plaats van alleen elektriciteit, veel van het zware werk in machine learning doet.
Bronvermelding: Sved, J., Song, S., Li, L. et al. Inverse-designed nanophotonic neural network accelerators for ultra-compact optical computing. Nat Commun 17, 1059 (2026). https://doi.org/10.1038/s41467-026-68648-1
Trefwoorden: fotonische neurale netwerken, nanofotonica, optisch rekenen, hardwareversnellers, inverse ontwerp