Clear Sky Science · nl
Concurrerende cognitieve drijfveren bij menselijk verkennen in afwezigheid van trade-off met exploiteren
Waarom we verkennen, zelfs wanneer er niets op het spel staat
Stel je voor dat je restaurantrecensies scrolt of door onbekende straten in een stad zwerft: je bent aan het verkennen, maar je klikken of stappen leveren op het moment zelf niets op of kosten je niets. Deze studie onderzoekt hoe onze nieuwsgierigheid eruitziet in zulke situaties met lage inzet, en of die verschilt van de manier waarop we verkennen wanneer elke keuze direct winst of verlies oplevert. Door onmiddellijke beloningen weg te nemen in een zorgvuldig gecontroleerd experiment, onthullen de auteurs verborgen touwtrekpartijen in ons beslissingsproces tussen twee soorten informatiezoekgedrag.
Beloningen veranderen in kleuren
De meeste laboratoriumstudies naar verkennen gebruiken gokachtige spellen waarbij elke keuze punten of geld oplevert. Daardoor is het moeilijk te bepalen of mensen echt nieuwsgierig zijn of gewoon achter beloningen aan zitten. Hier ontwierpen de onderzoekers een nieuwe taak waarbij de “beloningen” slechts kleurtonen waren, geen punten. Bij elke proef kozen vrijwilligers tussen twee abstracte vormen, elk gekoppeld aan een zak die voornamelijk blauwtintige of voornamelijk oranjeachtige uitkomsten produceerde. Belangrijk is dat het zien van een kleur niet meteen geld opleverde of kostte; het onthulde alleen het statistische patroon achter die optie, alsof je leert hoe een gokautomaat zich doorgaans gedraagt. 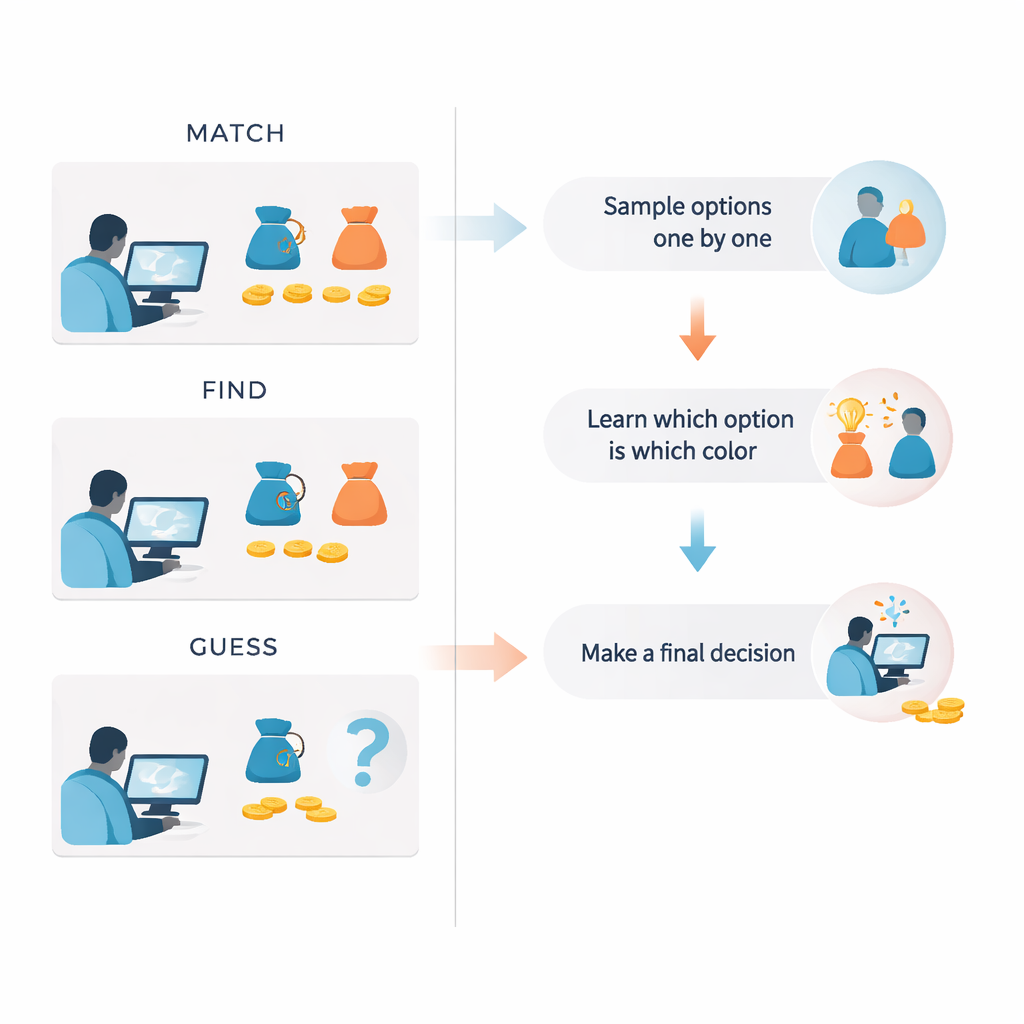
Drie manieren om dezelfde vraag te stellen
De slimme vondst was de steekproefervaring hetzelfde te houden terwijl alleen de instructies en het moment waarop beloningen verschenen veranderden. In de MATCH‑voorwaarde kregen mensen de opdracht om een doelkleur te verzamelen, en elke uitkomst die meer op die doelkleur leek leverde direct punten op, wat klassieke “explore–exploit”-dilemma’s nabootste. In de GUESS‑voorwaarde was er tijdens het bemonsteren geen doel; pas aan het einde van de reeks werd deelnemers gevraagd welke optie meestal blauw of meestal oranje was, en zij werden alleen betaald voor dat uiteindelijke antwoord. De FIND‑voorwaarde lag ertussenin: de doelkleur was vanaf het begin bekend, maar beloningen hingen nog steeds alleen af van een enkele uiteindelijke keuze. Over meerdere onafhankelijke groepen toonde het team aan dat de prestaties in alle voorwaarden ruim boven toeval lagen, wat bevestigt dat deelnemers de kleur–optie-koppelingen leerden.
Chunking versus onzekerheidsnajagen
Wanneer verkennen niet concurreerde met onmiddellijke beloning, gedroegen mensen zich op een verrassend gestructureerde manier. In de GUESS‑voorwaarde begonnen ze elke nieuwe reeks door herhaaldelijk dezelfde optie meerdere keren na elkaar te bemonsteren, alsof ze een degelijke eerste indruk van die ene wilden krijgen. Pas na dit “chunk” van herhaalde keuzes schakelden ze over en begonnen ze later in de reeks de voorkeur te geven aan welke optie op dat moment het meest onzeker was. De auteurs noemen de eerste neiging lokale onzekerheidsminimalisatie: de twijfel over de optie die je momenteel aanraakt verminderen. De latere neiging is globale onzekerheidsminimalisatie: doelbewust de optie bemonsteren waarvan je het minst weet. In tegenstelling hiermee trokken mensen in de MATCH‑voorwaarde, waar elke uitkomst duidelijke waarde had, zich snel naar de optie die het beste bij de doelkleur paste en vertoonden veel minder van dit initiële chunk‑patroon. 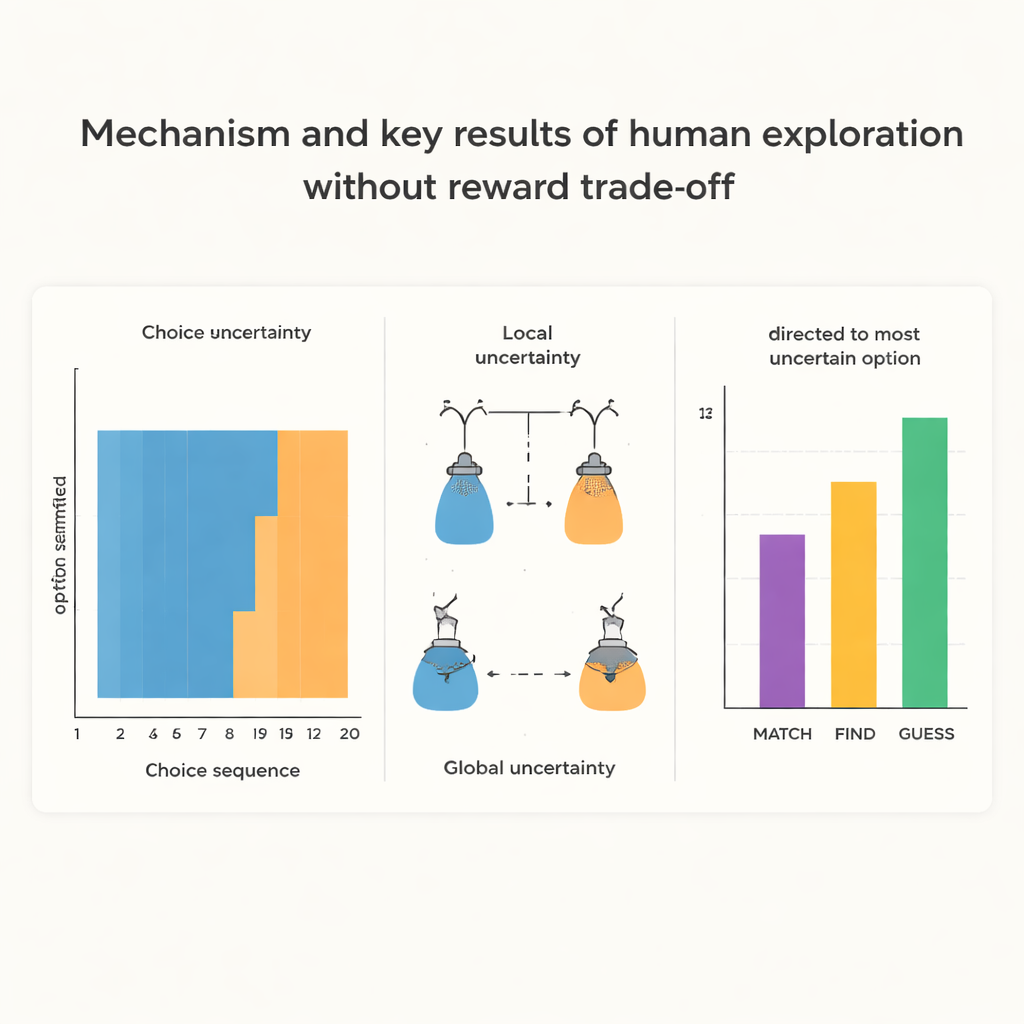
Onder de motorkap kijken met computationele modellen
Om deze patronen dieper te begrijpen, bouwden de onderzoekers wiskundige modellen die keuzes voorspellen op basis van de geschiedenis van waargenomen kleuren. Een “optimale” sampler, ongehinderd door mentale inspanning, zou altijd de meest onzekere optie kiezen om zo efficiënt mogelijk informatie te vergaren. Menselijke deelnemers gedroegen zich niet als deze ideale agent. Modelaanpassingen toonden aan dat mensen, naast een bescheiden neiging om onzekerheid na te jagen wanneer beloningen vertraagd waren, een sterke bias hadden om hun vorige keuze te herhalen en in veel gevallen te blijven herhalen totdat zij een persoonlijke drempel van vertrouwen in die optie bereikten. Interessant genoeg vertoonden individuen die sterker vroege chunking lieten zien vaak ook meer gerichte exploratie later en presteerden over het geheel beter, wat suggereert dat deze ogenschijnlijk suboptimale strategie gegeven menselijke cognitieve beperkingen een nuttig compromis kan zijn.
Waarom dit ertoe doet voor alledaagse nieuwsgierigheid
Deze bevindingen suggereren dat wanneer we verkennen zonder ons zorgen te maken over directe beloningen, twee krachten onze nieuwsgierigheid vormen. De ene duwt ons om bij wat we momenteel onderzoeken te blijven, om zeker te zijn dat we het echt begrijpen; de andere zet ons aan tot wat we overall het minst weten. In het echte leven weerspiegelt het doorbladeren van recensies, het leren van een nieuwe stad of het uitproberen van nieuwe tools waarschijnlijk dezelfde balans tussen lokaal en globaal informatiezoeken. De studie laat zien dat als we verkennen alleen bestuderen in beloningsrijke taken, we het risico lopen te misverstanden hoe mensen van nature kennis zoeken omwille van de kennis zelf.
Bronvermelding: Alméras, C., Chambon, V. & Wyart, V. Competing cognitive pressures on human exploration in the absence of trade-off with exploitation. Nat Commun 17, 883 (2026). https://doi.org/10.1038/s41467-026-68639-2
Trefwoorden: menselijk verkennen, besluitvorming, onzekerheid, informatie zoeken, cognitieve modellering