Clear Sky Science · nl
Uitgebreide benchmarking van single- en multi-ancestry polygenetische score-methoden met het PGS-hub platform
Waarom je DNA-risicoscore ertoe doet
Artsen worden beter in het uitlezen van ons DNA om te schatten wie een grotere kans heeft om veelvoorkomende aandoeningen te ontwikkelen, zoals hartziekten, diabetes of schizofrenie. Deze schattingen, polygenetische scores genoemd, combineren de kleine effecten van vele genetische varianten tot één getal. Er bestaan inmiddels veel concurrerende manieren om zulke scores te berekenen, en ze werken niet even goed voor mensen met verschillende ancestrale achtergronden. Deze studie zette een directe vergelijking van toonaangevende methoden op en bouwde een online dienst, PGS-hub, waarmee onderzoekers deze scores op een consistente en gebruiksvriendelijke manier kunnen berekenen.
Een alles-in-één locatie voor DNA-risicocalculators
De auteurs creëerden PGS-hub, een webplatform dat veel van de technische complexiteit rond polygenetische scores wegschermt. Gebruikers uploaden resultaten van genetische studies die samenvatten hoe miljoenen DNA-markers samenhangen met een ziekte of eigenschap. Vervolgens kiezen ze de ancestrale achtergrond van de populatie waarin ze geïnteresseerd zijn — bijvoorbeeld Europees of Afrikaans — en selecteren ze uit een menu van populaire scoringsmethoden. Achter de schermen zet PGS-hub de invoer om naar de juiste formaten, gebruikt vooraf gebouwde referentiepanels die beschrijven hoe nabijgelegen DNA-markers gecorreleerd zijn, en voert grote aantallen taken uit op een high-performance computersysteem. De output is een compact bestand met gewichten dat op individuele genomen kan worden toegepast om voor elke persoon een score te genereren. 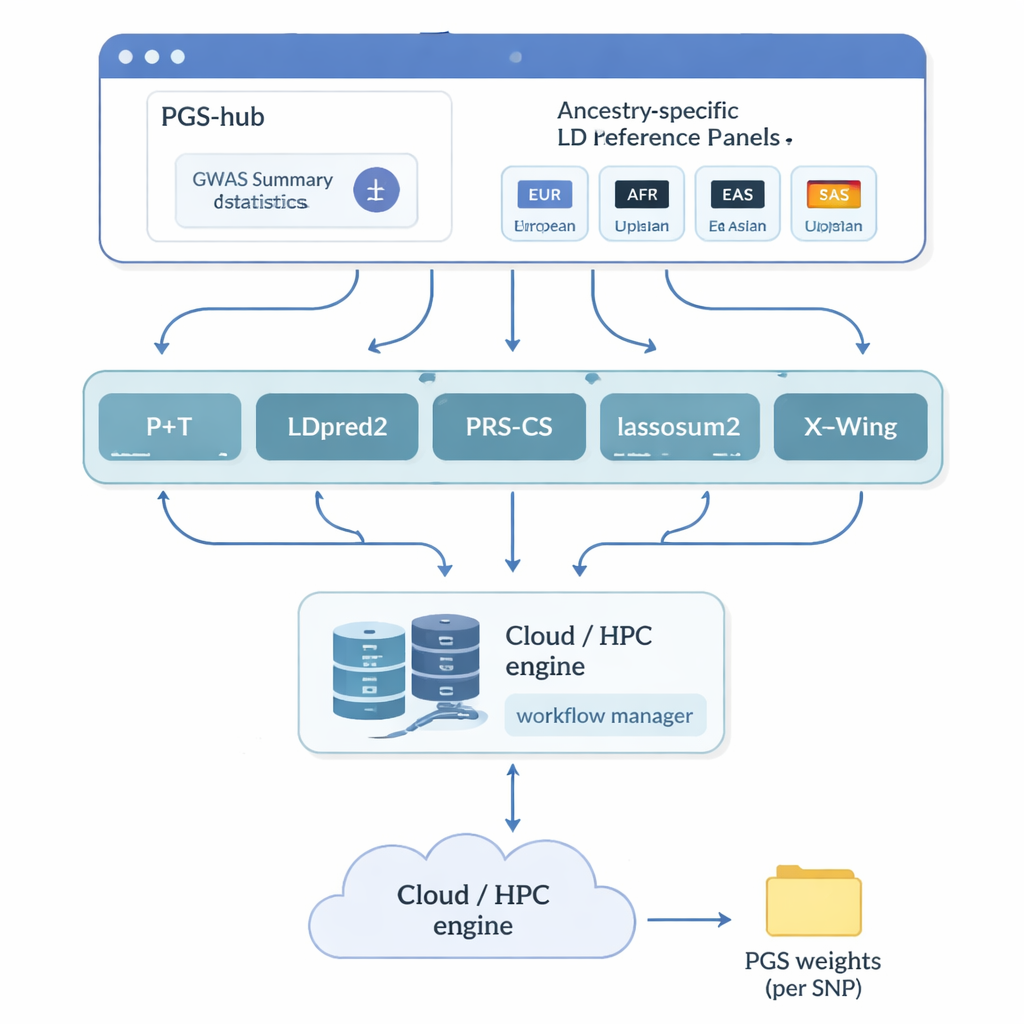
13 scoringsmethoden aan de tand gevoeld
Om te bepalen welke benaderingen het beste werken, vergeleek het team 13 state-of-the-art methoden over 36 ziekten en eigenschappen bij bijna 380.000 personen van Europese afkomst en iets meer dan 8.000 personen van Afrikaanse afkomst uit de UK Biobank. Ze evalueerden niet alleen hoe goed elke score voorspelde wie een ziekte had of een hogere eigenschapswaarde, maar ook hoeveel rekentijd en geheugen elke methode verbruikte. Bij Europeanen leverde één methode, LDpred2, over het algemeen de meest accurate scores op en versloeg deze vaak duidelijk andere methoden. Een handvol alternatieven — lassosum2, PRS-CS en SDPR — presteerde voor veel eigenschappen bijna even goed, terwijl sommige oudere methoden achterbleven. Voor eigenschappen zoals lengte of de ziekte van Crohn verklaarden de beste scores een aanzienlijk deel van het genetische risico; voor andere, zoals nierfunctie, hadden alle methoden moeite, wat wijst op zwakkere onderliggende genetische signalen.
Inzichten voor diverse populaties en gecombineerde methoden
Een belangrijke zorg bij genetische voorspelling is dat methoden die voornamelijk in Europeanen zijn getraind mogelijk niet goed generaliseren naar mensen met andere ancestrale achtergronden. Toen de auteurs hun benchmarks herhaalden met genetische studies van personen met Afrikaanse afkomst, presteerde elke methode slechter, wat het gebrek aan grote studies in deze populaties benadrukt. Toch behoorden LDpred2 en SDPR vaak tot de betere opties. Het team onderzocht ook “multi-ancestry” benaderingen die expliciet informatie over populaties heen combineren. Hier versloeg een relatief eenvoudige strategie — het lineair combineren van de beste ancestrie-specifieke LDpred2-scores tot één LDpred2-multi score — complexere multi-ancestry modellen zoals PRS-CSx en X-Wing voor zowel Europese als Afrikaanse groepen. Daarnaast toonden de auteurs aan dat het opbouwen van een ensemble, dat de sterkste scores van meerdere methoden mengt, de voorspelling over alle eigenschappen verder verbeterde, vooral voor sterk erfelijke aandoeningen zoals schizofrenie en coronaire hartziekte. 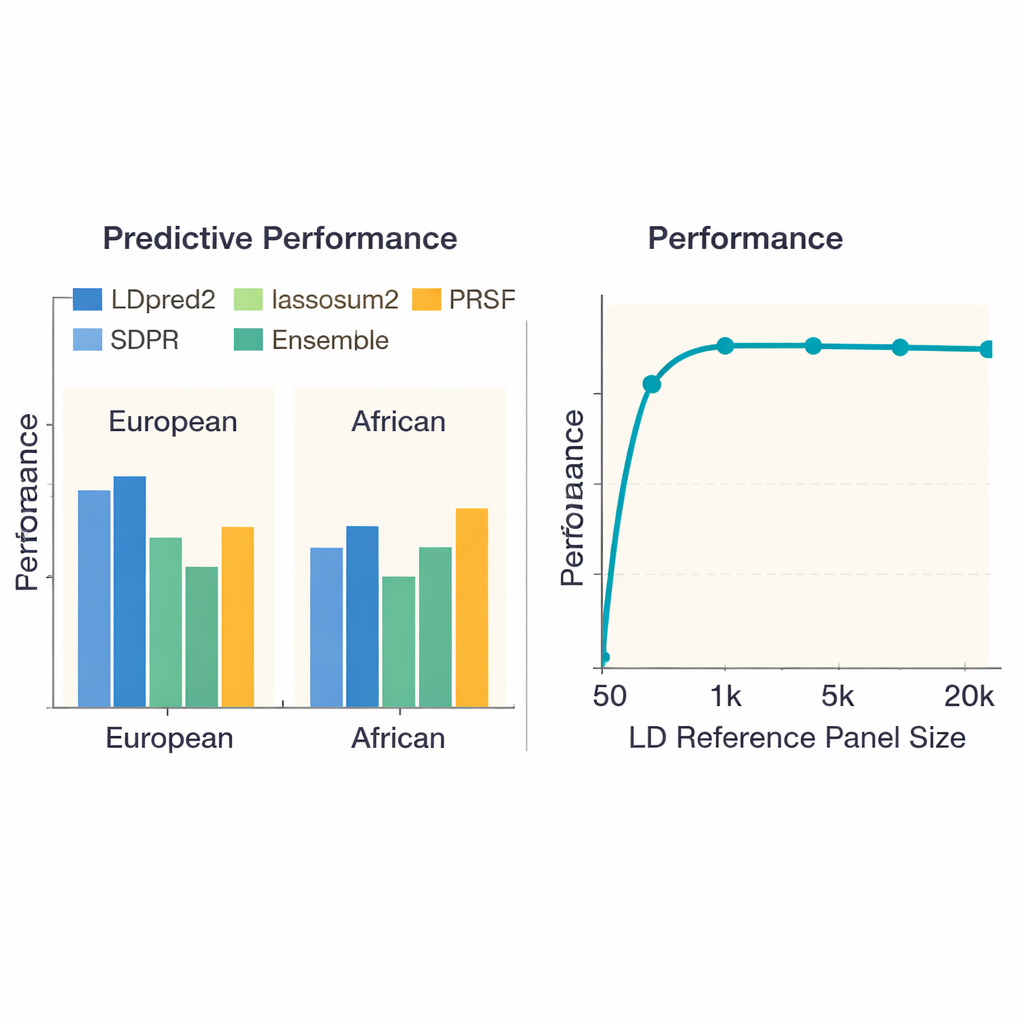
Hoe datakeuzes en rekenbeperkingen scores vormen
De studie onderzocht hoe de grootte van het referentiepanel — de groep personen die gebruikt wordt om te leren hoe nabijgelegen DNA-markers samen variëren — de prestatie beïnvloedt. Wanneer dit panel zeer klein was (minder dan 1.000 individuen), waren de scores merkbaar minder nauwkeurig. Naarmate het panel groeide tot ongeveer 5.000 personen verbeterde de prestatie scherp en vlakte daarna af, wat suggereert dat steeds grotere panels afnemende meeropbrengsten geven. Verrassend was dat het simpelweg toevoegen van meer DNA-markers niet altijd hielp: het gebruik van ongeveer 6,6 miljoen varianten maakte voorspellingen soms slechter dan het gebruik van een zorgvuldig gekozen set van ongeveer 1,1 miljoen, waarschijnlijk omdat extra markers meer ruis dan nuttig signaal toevoegden. De auteurs documenteerden ook grote verschillen in rekencost. Eenvoudige methoden zoals basis pruning-and-thresholding waren in minder dan een uur per eigenschap klaar, terwijl sommige Bayesiaanse benaderingen honderden CPU-uren vergden — informatie die van belang is voor grote projecten of groepen met beperkte middelen.
Wat dit betekent voor toekomstige DNA-gebaseerde voorspelling
Voor niet-specialisten is de kernboodschap dat niet alle DNA-risicoscores gelijk zijn en dat details van hun constructie sterk bepalen wie er baat bij heeft. Dit werk biedt praktische richtlijnen: methoden zoals LDpred2 en goed ontworpen ensembles geven doorgaans de meest betrouwbare voorspellingen in grote Europese datasets, en multi-ancestry combinaties kunnen complexere cross-populatie modellen overtreffen. Tegelijkertijd onderstreept de afname in nauwkeurigheid bij personen van Afrikaanse afkomst de dringende behoefte aan grotere en diversere genetische studies. Door veel methoden in één gestandaardiseerd online platform te bundelen verlaagt PGS-hub de drempel voor onderzoekers wereldwijd om polygenetische scores te genereren en te vergelijken — een belangrijke stap op weg naar eerlijke en effectieve toepassing van dergelijke scores in de geneeskunde.
Bronvermelding: Chen, X., Wang, F., Zhao, H. et al. Comprehensive benchmarking single and multi ancestry polygenic score methods with the PGS-hub platform. Nat Commun 17, 2014 (2026). https://doi.org/10.1038/s41467-026-68599-7
Trefwoorden: polygenetische scores, genetische risicovoorspelling, PGS-hub platform, multi-ancestry genomica, UK Biobank