Clear Sky Science · nl
Drie open vragen over de overdraagbaarheid van polygeen scores
Waarom het voorspellen van gezondheid uit DNA moeilijker is dan het lijkt
Artsen en onderzoekers hopen steeds vaker DNA-gebaseerde "polygeen scores" te gebruiken om iemands risico op veelvoorkomende aandoeningen zoals diabetes, hartziekte of astma te voorspellen. Maar deze scores werken vaak alleen goed bij mensen die lijken op de oorspronkelijke onderzoeksdeelnemers, meestal personen van Europese afkomst. Dit artikel onderzoekt waarom deze voorspellingen niet betrouwbaar "reizen" naar mensen met een andere genetische achtergrond of andere levensomstandigheden, en wat dat betekent voor het eerlijk toepassen van genetische risicoscores in de geneeskunde.
Wat polygeen scores beloven — en waar ze tekortschieten
Polygeen scores combineren de kleine effecten van veel genetische varianten in het hele genoom tot één getal bedoeld om een eigenschap te voorspellen, zoals lengte of bloeddruk. Ze worden opgebouwd uit zeer grote genome-wide association studies (GWAS) die DNA-markers koppelen aan eigenschappen in honderden duizenden vrijwilligers. Wanneer die scores echter op nieuwe groepen mensen worden toegepast, varieert hun nauwkeurigheid sterk. Meestal wordt de voorspelling slechter naarmate de nieuwe groep genetisch of sociaal meer verschilt van de oorspronkelijke GWAS-deelnemers. Dit staat bekend als het portability-probleem: een score die in de ene context werkt kan in een andere misleiden, wat—als men er kritiekloos op vertrouwt—gezondheidsongelijkheden kan verdiepen.
Voorbij afkomst: afstand op de genetische kaart
Om dit probleem te onderzoeken gebruikten de auteurs gegevens uit de UK Biobank, met genetische en gezondheidsinformatie van meer dan 400.000 mensen. Ze bouwden polygeen scores voor 15 sterk erfelijke eigenschappen, zoals lengte, gewicht, bloedcelgetallen en cholesterolwaarden, gebaseerd op een grote groep voornamelijk Wit-Britse deelnemers. Vervolgens testten ze hoe goed deze scores eigenschappen voorspelden in 69.500 andere deelnemers met een breed scala aan genetische achtergronden. In plaats van mensen in brede afkomstscategorieën in te delen, plaatste het team elk individu op een continue "genetische afstand"-schaal: hoe ver iemands DNA-profiel lag van de gemiddelde GWAS-deelnemer wanneer geprojecteerd op een genetische kaart gebaseerd op hoofdcomponenten.
Voorspellende kracht neemt af — maar niet op eenvoudige of eerlijke manieren
Over deze genetische-afstandsschaal verschenen enkele bekende patronen. Voor lengte bijvoorbeeld nam de groepsgewijze voorspellingsnauwkeurigheid vloeiend af naarmate mensen genetisch verder van de GWAS-groep stonden. Toch verklaarde genetische afstand op individueel niveau slechts een klein deel van hoe goed hun eigenschappen werden voorspeld. Sociaaleconomische maatstaven, zoals de Townsend Deprivation Index (een buurtniveau-indicator van materiële achterstand), deden het ongeveer even goed—of iets beter—bij het verklaren van wie slechte voorspellingen ontving. Met andere woorden, mensen met een lagere sociaaleconomische status kregen vaker minder nauwkeurige genetische voorspellingen, zelfs binnen dezelfde genetische-afstandsgroep, wat benadrukt dat sociale context net zozeer kan bepalen of een score nuttig is als DNA.
Verschillende eigenschappen, verschillende historie, verschillende uitkomsten
Niet alle eigenschappen gedroegen zich hetzelfde. Voor lichaamsgewicht en lichaamsvet bereikte de voorspellingsnauwkeurigheid bijvoorbeeld een piek op gemiddelde genetische afstanden voordat ze afnam, en doorbrak daarmee het eenvoudige patroon "verder betekent slechter". Immuungerelateerde eigenschappen, zoals aantallen witte bloedcellen en lymfocyten, vertoonden bijzonder raadselachtig gedrag. Voor sommige van deze eigenschappen daalde de groepsgewijze voorspellingsnauwkeurigheid tot bijna nul, zelfs voor mensen die genetisch niet ver van de GWAS-steekproef stonden. De auteurs suggereren dat immuuneigenschappen mogelijk worden gevormd door snel veranderende evolutionaire druk—zoals vroegere infecties—die bepaalt welke DNA-varianten belangrijk zijn in verschillende populaties. In zulke gevallen kan de genetische architectuur zelf voldoende veranderd zijn, zodat een in één groep gebaseerde score in een andere groep bijna nutteloos wordt.
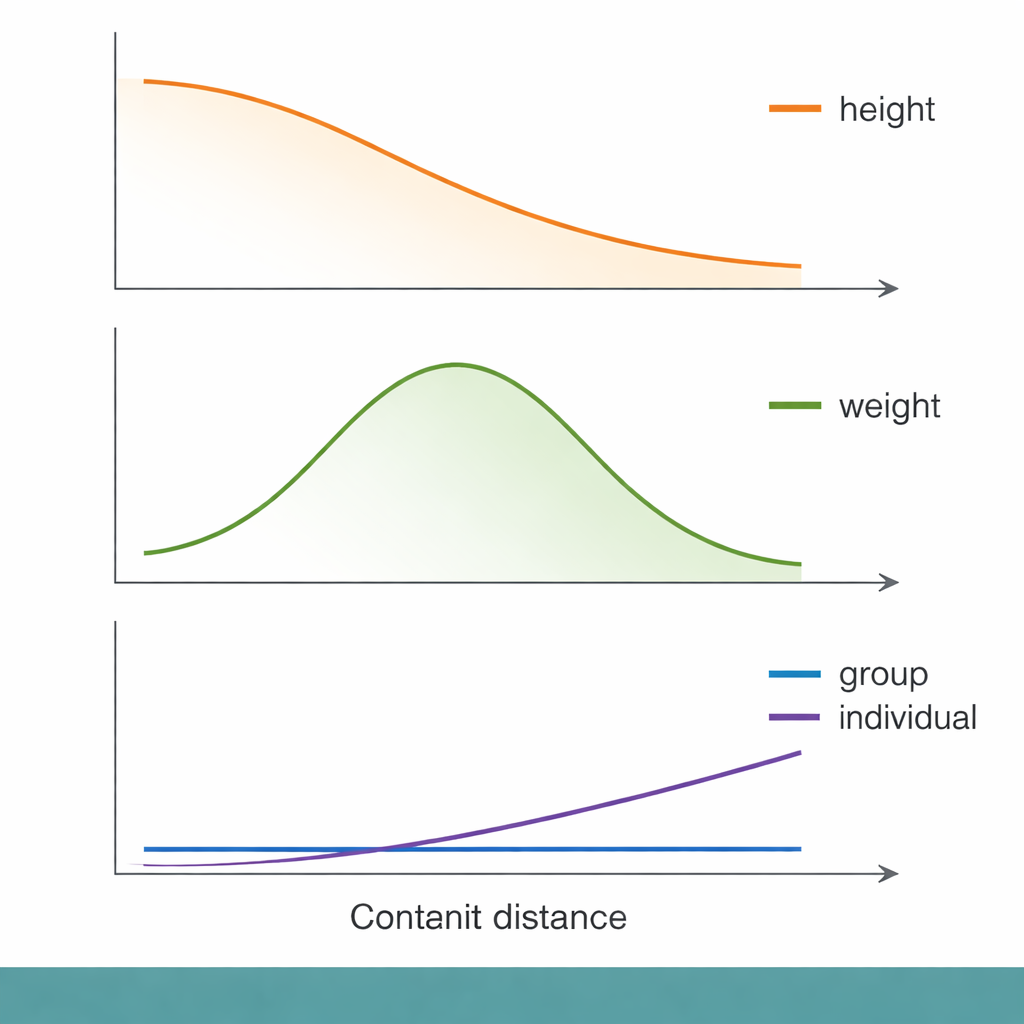
Hoe we prestaties scoren kan het verhaal omdraaien
Het beeld wordt nog complexer als we veranderen hoe "goede voorspelling" wordt gemeten. Veel eerder werk leunde op één statistiek, R², die vastlegt hoeveel variantie in een eigenschap een score in een groep verklaart. De auteurs laten zien dat andere maatstaven een ander beeld kunnen geven, vooral voor ziekten. Voor astma namen zowel precisie (hoeveel voorspelde gevallen echte gevallen zijn) als recall (hoeveel echte gevallen gevonden worden) af met genetische afstand op vergelijkbare manieren. Maar voor type 2 diabetes bleef precisie redelijk constant terwijl recall juist toenam met afstand—wat betekent dat de score een groter aandeel van echte gevallen vond in meer afgelegen groepen, ook al was hij in een genetisch dichterbijstaande groep gebouwd. Afhankelijk van of een kliniek meer geeft om het vinden van alle hoogrisicopatiënten of om het vermijden van valse alarmen, kan men tot tegengestelde conclusies komen over hoe overdraagbaar de score is.
Wat dit betekent voor het gebruik van DNA-scores in de praktijk
Samengevat betogen de onderzoekers dat we de bruikbaarheid van polygeen scores niet kunnen beoordelen door alleen naar brede afkomstsaanduidingen of één nauwkeurigheidsgetal te kijken. De kwaliteit van individuele voorspellingen hangt af van een mix van factoren: subtiele patronen van genetische gelijkenis, de evolutionaire geschiedenis van elke eigenschap, de omgevingen en sociale omstandigheden waarin mensen leven, en de specifieke manier waarop de score en zijn prestatiemaatstaf worden gekozen. Om polygeen scores eerlijk en effectief in de geneeskunde te kunnen toepassen, zullen onderzoekers betere methoden moeten ontwikkelen om fijnmazige genetische structuren vast te leggen, sociale en omgevingsinvloeden te modelleren en evaluatiemaatstaven af te stemmen op echte beslissingen. Tot die tijd moeten genetische risicoscores voorzichtig worden gebruikt, met aandacht voor de mensen—en contexten—waarin ze slecht werken evenals die waarin ze goed presteren.
Bronvermelding: Wang, J.Y., Lin, N., Zietz, M. et al. Three open questions in polygenic score portability. Nat Commun 17, 942 (2026). https://doi.org/10.1038/s41467-026-68565-3
Trefwoorden: polygeen scores, genetische voorspelling, gezondheidsverschillen, genetische afkomst, precisiegeneeskunde