Clear Sky Science · nl
Fysieke neurale netwerken met scherptebewuste training
Waarom dit belangrijk is voor de toekomst van AI-hardware
Naarmate kunstmatige intelligentie krachtiger wordt, wordt ze steeds vaker beperkt niet door slimme algoritmen maar door de chips die ze uitvoeren. Een veelbelovende uitweg is het bouwen van neurale netwerken direct in fysieke hardware met behulp van licht, analoge elektronica of andere golfgebaseerde systemen. Dit artikel introduceert een nieuwe manier om zulke “fysieke neurale netwerken” te trainen zodat ze nauwkeurig blijven, ook wanneer de echte wereld rommelig is — wanneer apparaten licht afwijkend zijn gebouwd, warmte verschuift of componenten uitlijning verliezen.
Van digitale hersenen naar fysieke machines
Moderne AI draait meestal op digitale hardware zoals grafische processors, waarbij training afhangt van het backpropagation-algoritme om miljoenen numerieke gewichten aan te passen. Fysieke neurale netwerken proberen deze berekening over te hevelen naar echte materialen en apparaten — zoals fotonische chips, interferometer-matrices of diffractieve optische opstellingen — waarvan het gedrag van nature de wiskunde van neurale netwerken nabootst. Omdat deze systemen informatie verwerken waar die wordt opgeslagen, kunnen ze veel sneller en energiezuiniger zijn dan conventionele chips. Maar trainen is lastig: of je traint een digitaal model en hoopt dat het overeenkomt met de hardware, of je traint direct op het apparaat zelf. Beide paden lopen vast wanneer echte apparaten afwijken van ideale modellen of in de loop van de tijd drift vertonen.
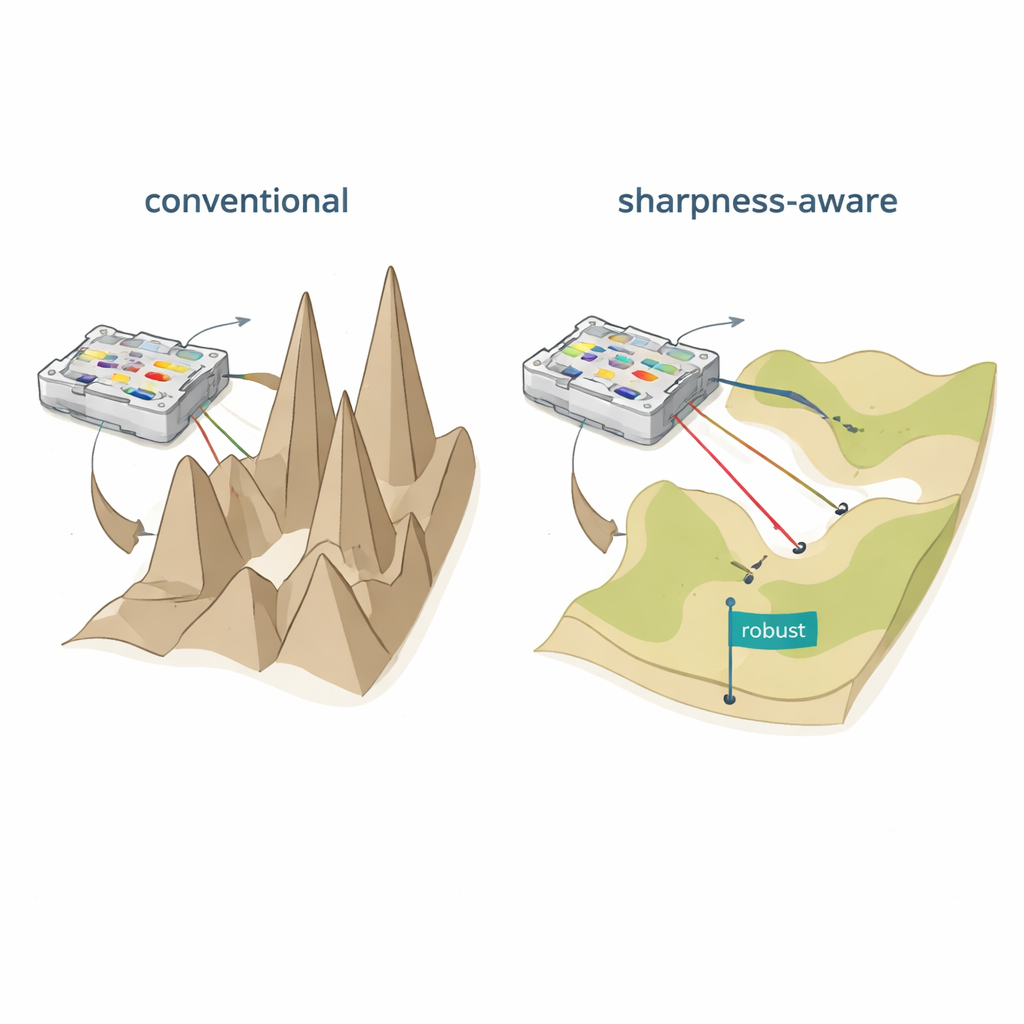
Twee gebrekkige manieren om fysieke netwerken te onderwijzen
De eerste benadering, in silico-training, leert alle parameters in een computermodel en kopieert die vervolgens naar de hardware. Dit werkt alleen goed als het wiskundige model vrijwel exact overeenkomt met het gefabriceerde apparaat, wat zelden het geval is zodra productvariaties, elektrische ruis en thermische effecten meespelen. De tweede benadering, in situ-training, betrekt het fysieke apparaat direct bij het leerproces en meet herhaaldelijk outputs terwijl parameters worden aangepast. Hoewel dit modelleerfouten omzeilt, veroorzaakt het andere problemen: graadinformatie is moeilijk en duur te verkrijgen, training wordt apparaat-specifiek en de resulterende parameters kunnen meestal niet naar een andere schijnbaar identieke chip worden overgedragen. In beide gevallen kunnen kleine veranderingen na inzet — zoals een kleine temperatuurschommeling of uitlijningfout — de nauwkeurigheid drastisch verminderen en dure retraining noodzakelijk maken.
Het vlakker maken van het leervlak
De auteurs stellen scherptebewuste training (SAT) voor, geïnspireerd door een machine-learningidee genaamd sharpness-aware minimization. In plaats van alleen instellingen te vinden die lage fouten op de trainingsdata opleveren, zoekt SAT ook naar regio’s waar de fout langzaam verandert wanneer de onderliggende fysieke parameters iets worden verschoven. In geometrische termen vindt traditionele training vaak een diepe maar smalle vallei in het “verlieslandschap”, waar zelfs kleine verschuivingen in stromen, fases of posities de prestaties laten instorten. SAT zoekt bewust naar brede, vlakke valleien waar de prestaties onder zulke verstoringen hoog blijven. Wiskundig voegt het een term toe aan het trainingsdoel die scherpe, sterk gekromde regio’s in de parameterruimte bestraft, en het benadert deze straf efficiënt met twee zorgvuldig gekozen gradientstappen in plaats van kostbare tweede-afgeleideberekeningen.
Aan tonen van robuustheid over verschillende optische platforms
Om te laten zien dat SAT niet aan één specifiek apparaat gebonden is, passen de auteurs het toe op drie verschillende optische neurale-netwerkplatforms. Op microring-resonator weight banks — kleine siliciumlussen die licht bij verschillende golflengten geleiden — tonen ze aan dat SAT-getrainde systemen een hoge classificatienauwkeurigheid behouden zelfs wanneer de temperatuur enkele graden verschuift, terwijl standaardtraining en ruisinjectiemethoden dramatisch falen. Ze breiden dit uit naar veeleisender taken zoals beeldclassificatie op CIFAR-10, beeldcompressie en reconstructie, en beeldgeneratie, waar SAT de prestaties stabiel houdt terwijl conventionele methoden bij bescheiden thermische verschuivingen degraderen. In simulaties van Mach–Zehnder-interferometer-matrices zijn SAT-getrainde modellen veel toleranter voor realistische fabricagefouten en, cruciaal, parameters die op één apparaat zijn getraind kunnen naar andere chips met verschillende imperfecties worden overgedragen zonder nauwkeurigheid te verliezen. Tenslotte, in een free-space diffractieve optische opstelling met een OLED-display, lenzen en een ruimtelijke lichtmodulator, verbetert SAT de tolerantie voor fysieke uitlijningsfouten zoals rotatie, pixelverschuivingen en schaling, ook al wordt de exacte relatie tussen deze uitlijningsfouten en de netwerkparameters niet expliciet gemodelleerd.
Een praktische route naar betrouwbare fysieke AI
In eenvoudige bewoordingen laat dit werk zien hoe hardware-neurale netwerken zo te onderwijzen dat ze de onvermijdelijke eigenaardigheden van echte apparaten “vergeven”. Door het leren te sturen richting vlakke, stabiele regio’s van het foutenlandschap maakt scherptebewuste training fysieke neurale netwerken zowel nauwkeuriger als robuuster tegen fabricagevariaties, temperatuurschommelingen en mechanische uitlijningsfouten. Omdat het zowel met als zonder gedetailleerde fysische modellen kan worden gebruikt en op meerdere soorten optische hardware werkt, biedt SAT een praktische werkwijze om snelle, energiezuinige fysieke AI-systemen van laboratoriumdemonstraties naar toepassingen in de echte wereld op te schalen.
Bronvermelding: Xu, T., Luo, Z., Liu, S. et al. Physical neural networks using sharpness-aware training. Nat Commun 17, 1766 (2026). https://doi.org/10.1038/s41467-026-68470-9
Trefwoorden: fysieke neurale netwerken, fotonicus rekenen, robust trainen, scherptebewuste optimalisatie, neuromorfe hardware