Clear Sky Science · nl
Single-shot matrix-matrix fotonische processor gebaseerd op ruimtelijk-spectrale hypermultiplexing en parallelle diffractie
Waarom snellere, groene rekenkracht ertoe doet
Elke keer dat we een digitale assistent iets vragen of door sociale media scrollen, werken krachtige kunstmatige-intelligentiemodellen op de achtergrond. Deze modellen worden zo groot dat conventionele computerchips moeite hebben om bij te blijven zonder enorme hoeveelheden energie te verbruiken. Dit artikel beschrijft een nieuw soort rekenhardware die licht in plaats van elektriciteit gebruikt om kernberekeningen voor AI uit te voeren, met als doel toekomstige systemen zowel sneller als veel energiezuiniger te maken.
Licht omzetten in een rekenmachine
Moderne AI berust op bewerkingen die matrixvermenigvuldigingen worden genoemd, die miljarden of biljoenen keren worden herhaald wanneer een neurale netwerk beelden of tekst analyseert. Elektronische chips voeren dit werk betrouwbaar uit, maar verspillen veel energie alleen al aan het heen en weer verplaatsen van gegevens binnen de chip. De onderzoekers in deze studie bouwen voort op een ander idee: laat het licht zelf de rekenkunde doen. In een optisch neurale netwerk wordt informatie in laserbundels gecodeerd, gemanipuleerd terwijl de bundels door lenzen en modulatoren gaan, en vervolgens uitgelezen met lichtsensoren. Omdat fotonen niet dezelfde warmte in geleidende banen veroorzaken als elektronen, kunnen dergelijke systemen in principe veel hogere snelheden en efficiëntie bereiken.
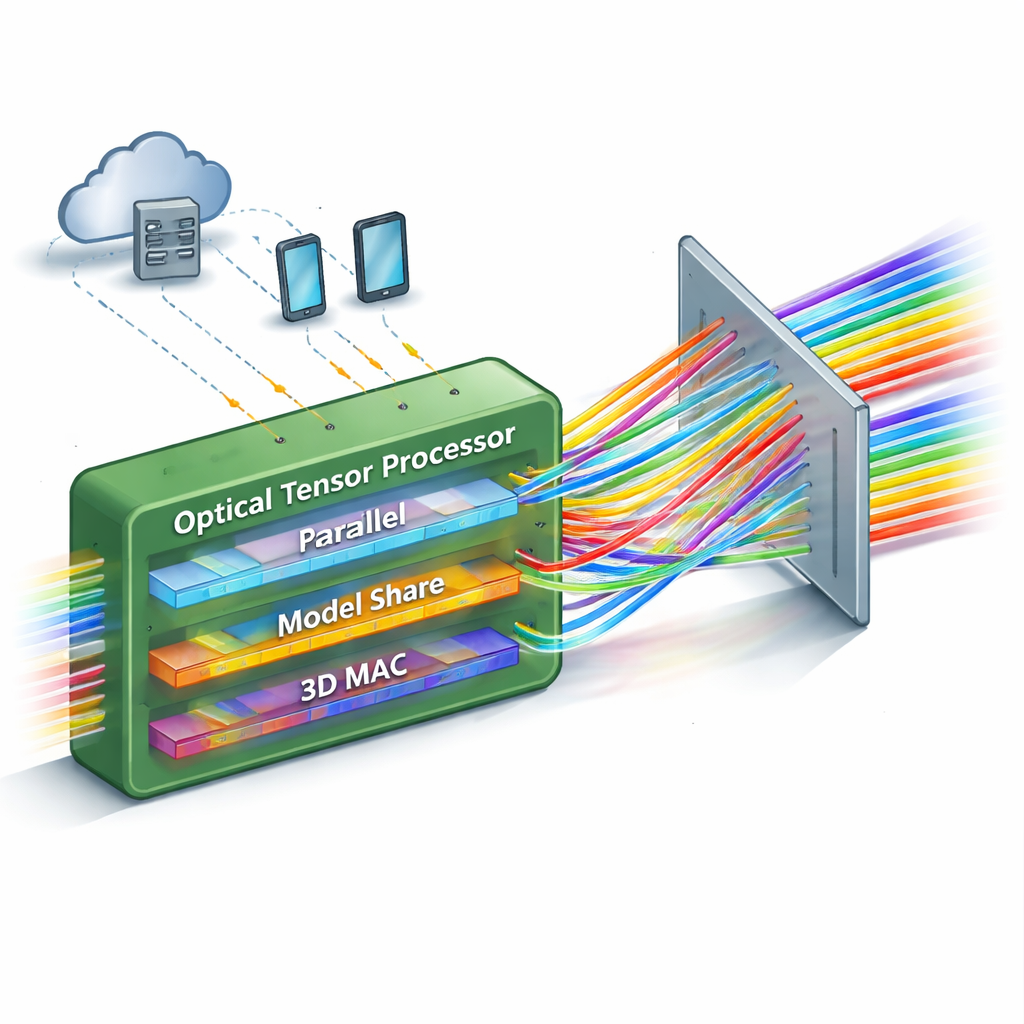
Veel berekeningen in één keer uitvoeren
De meeste bestaande optische neurale netwerken hebben een beperking: ze kunnen slechts een bescheiden aantal berekeningen parallel verwerken, of ze worden te complex om op te schalen. Dit werk introduceert een "single-shot" matrix–matrix fotonische processor die dramatisch vergroot hoeveel bewerkingen tegelijk kunnen worden gedaan. Het kernidee is informatie gelijktijdig in drie verschillende aspecten van licht te verpakken — de ruimtelijke positie, de kleur (golf-lengte) en de timing. Door deze dimensies zorgvuldig te ordenen, kan het apparaat een volledige matrix–matrixvermenigvuldiging uitvoeren, met duizenden multiply-and-accumulate-stappen, in één doorgang van licht door het systeem.
Een diffractierooster als verkeersleider voor licht
Centraal in het ontwerp staat een eenvoudig maar krachtig optisch element: een diffractierooster dat licht in verschillende hoeken splits afhankelijk van de kleur. Het team gebruikt een speciaal gerangschikt, driedimensionaal roosterachtig systeem als verkeersleider, dat veelgekleurde bundels van vele ingangs-kanalen naar herschikte uitgangs-kanalen leidt. Te verwerken gegevens worden gecodeerd als lichtintensiteiten op één set modulatoren, terwijl de gewichten van het neurale netwerk op een andere set worden gecodeerd. Wanneer de bundels samenkomen en door het rooster gaan, worden hun paden herschikt zodat elk uitgangskanaal vanzelf de juiste combinaties van gegevens en gewichten optelt. Tijdintegreerende detectoren accumuleren dan bijdragen over meerdere korte tijdstappen, waardoor de grootte van de berekening effectief wordt vergroot zonder extra complexiteit in de optiek toe te voegen.
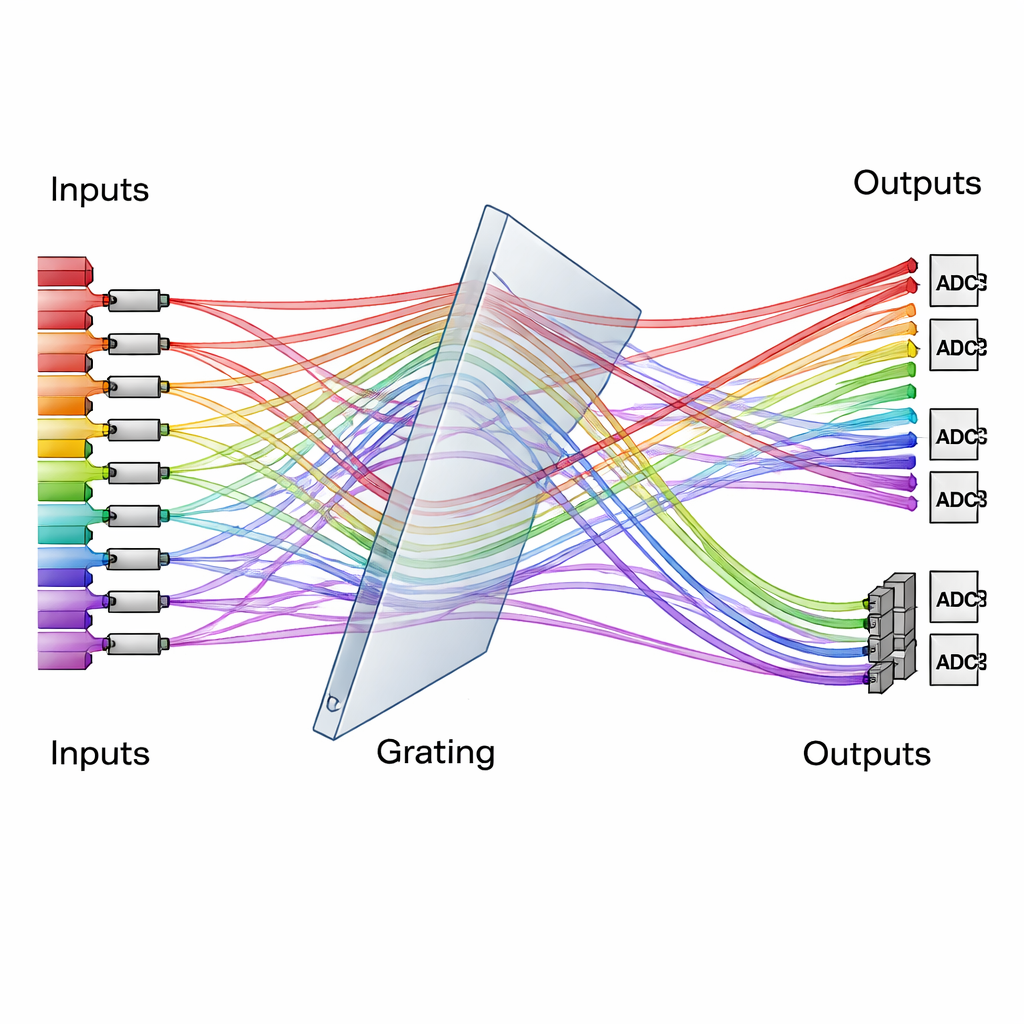
Van labsysteem naar echte AI-taken
De auteurs demonstreren een 16-by-16-by-16-by-16 optische tensorprocessor, wat betekent dat hij een 16×16-matrix met een andere 16×16-matrix kan vermenigvuldigen in één optische "shot", en daarmee 4096 basisbewerkingen tegelijk uitvoert. Het systeem werkt op multi-gigahertz kloksnelheden en bereikt een effectieve rekennauwkeurigheid van meer dan acht bits, vergelijkbaar met veel praktische AI-versnellende hardware. Om te laten zien dat dit geen loutere fysica-demonstratie is, gebruiken ze de processor om onderdelen van een kleine beeldherkenningspipeline uit te voeren: een convolutioneel neurale netwerk dat kenmerken uit cijferbeelden haalt, gevolgd door een volledig verbonden netwerk dat deze classificeert. Zelfs met optische ruis en hardware-onvolkomenheden herkent de opstelling handgeschreven cijfers met ongeveer 96% nauwkeurigheid, dicht bij een volledig digitale uitvoering van hetzelfde model.
Energieverbruik, gevoeligheid en schaalbaarheid
Omdat de architectuur dezelfde optische componenten hergebruikt over veel parallelle kanalen en signalen efficiënt accumuleert, kan elke basishandeling met extreem weinig energie worden uitgevoerd — tot enkele tientallen attojoule optische energie per vermenigvuldiging. De auteurs schatten dat de algehele energie-efficiëntie sommige state-of-the-art elektronische AI-versnellers al overtreft, en betogen dat bescheiden verbeteringen in modulatoren en digitale-naar-analoogconverters dit kunnen brengen naar honderden biljoenen bewerkingen per seconde per watt. Belangrijk is dat het ontwerp enkele schaalbeperkingen vermijdt die andere optische schema’s treffen, waardoor grotere versies met veel meer kanalen (bijvoorbeeld 30×30 of zelfs 60×60 arrays) met vergelijkbare componenten haalbaar lijken.
Wat dit betekent voor dagelijkse technologie
Simpel gezegd toont dit onderzoek aan dat een relatief eenvoudige optische opstelling — een slimme manier om gekleurde lichtbundels door een diffractierooster te leiden — kan fungeren als een krachtige, energiezuinige motor voor AI-achtige berekeningen. Hoewel dit nog een laboratoriumprototype is, wijst het op toekomstige datacenters en edge-apparaten waar lichtgebaseerde processors de zwaarste neurale-netwerkwerkbelastingen afhandelen, energiekosten verlagen en grotere, snellere modellen mogelijk maken. Als dergelijke fotonische tensorprocessors geïntegreerd en op grote schaal geproduceerd kunnen worden, zouden ze wel eens een sleutelcomponent kunnen worden in de volgende generatie van high-performance, energiezuinige kunstmatige-intelligentiehardware.
Bronvermelding: Luan, C., Davis III, R., Chen, Z. et al. Single-shot matrix-matrix photonic processor based on spatial-spectral hypermultiplexed parallel diffraction. Nat Commun 17, 484 (2026). https://doi.org/10.1038/s41467-026-68452-x
Trefwoorden: optische neurale netwerken, fotonische rekenkracht, matrixvermenigvuldiging, energiezuinige AI-hardware, diffractierooster