Clear Sky Science · nl
Uitgebreide kaart van RNA‑modificatiedynamiek en crosstalk via deep learning en nanopore directe RNA‑sequencing
De verborgen leestekens van RNA
De RNA‑moleculen in onze cellen zijn geen simpele reeksen van A, C, G en U. Ze zijn versierd met talloze kleine chemische markeringen die fungeren als leestekens en helpen bepalen welke genen aanstaan, hoe eiwitten worden gemaakt en hoe cellen reageren op stress en ziekte. Tot nu toe konden onderzoekers deze markeringen meestal één voor één bestuderen, waardoor het moeilijk was om te zien hoe ze samen functioneren over het hele genoom. Dit artikel introduceert ORCA, een deep‑learning-systeem dat native RNA‑moleculen rechtstreeks leest en een globale, meerlaagse kaart bouwt van deze chemische markeringen en hun onderlinge interacties.
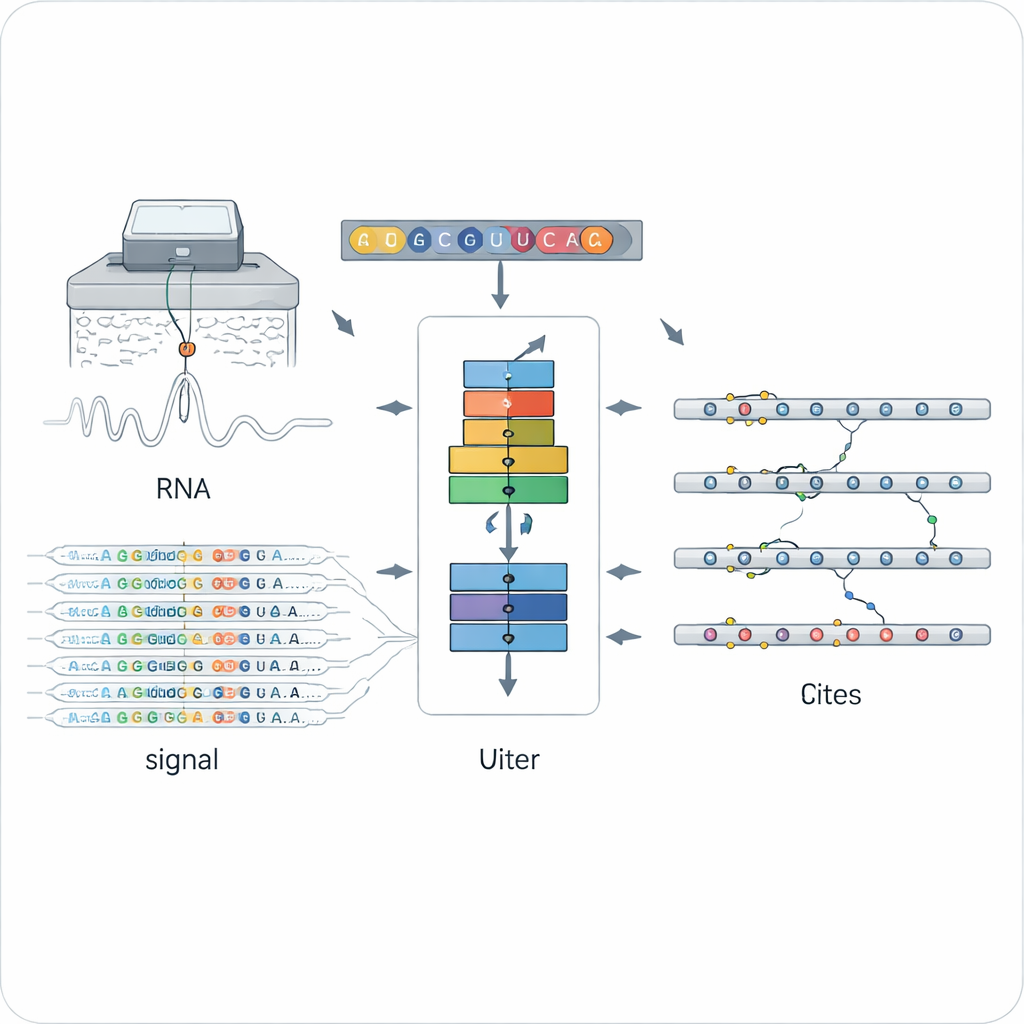
Een nieuwe manier om chemische markeringen op RNA te lezen
Traditionele methoden om RNA‑modificaties te vinden vertrouwen meestal op speciale antilichamen of chemische behandelingen die zijn afgestemd op één type markering, zoals het veelgebruikte N6‑methyladenosine (m6A). Dat maakt ze krachtig maar beperkt: elke methode ziet slechts één soort markering, vaak in één experimentele opzet. Nanopore directe RNA‑sequencing opende een andere deur door individuele RNA‑moleculen door een tiny porie te leiden en veranderingen in elektrische stroom te meten die afhangen van de exacte chemische structuur van elke base. Gewijzigde en ongewijzigde letters vervormen het signaal en de basecalling op subtiele manieren, maar het interpreteren van deze luidruchtige, hoogdimensionale data voor vele modificatietypen is een grote uitdaging geweest.
Een neuraal netwerk leren elke markering te herkennen
ORCA (Omni‑RNA modification Characterization and Annotation) pakt deze uitdaging in twee fasen aan. Eerst concentreert het zich op een klein venster rond elk nucleotide en aggregeert zowel het ruwe elektrische signaal als het patroon van sequencingfouten over vele reads. Omdat slechts een fractie van de RNA‑kopieën een bepaalde markering draagt, vertonen echt gemodificeerde locaties meer scheve signaalverdelingen en frequentere basecalling‑fouten op die positie. ORCA gebruikt een diep recurrent neuraal netwerk dat getraind is met een "adversarial" strategie zodat het algemene patronen leert die gemodificeerde van ongewijzigde locaties onderscheiden, zonder zich vast te pinnen op één bekend chemisch type. Dit stelt ORCA in staat om elk site een modificatiescore en een geschat aandeel gemodificeerde moleculen toe te kennen.
De identiteit van elke markering leren
In de tweede fase leert ORCA te labelen welk soort chemische markering aanwezig is. De auteurs voeden het model met een set hoog‑vertrouwenslocaties uit openbare databases, waar conventionele experimenten al m6A, 5‑methylcytosine (m5C), pseudouridine (Ψ), inosine, 2′‑O‑methylatie en verschillende zeldzamere markeringen hebben geïdentificeerd. ORCA comprimeert de signaalpatronen, sequentiecontext en korte sequentie"motieven" rond elke locatie naar een lagerdimensionale kaart en verfijnt zichzelf vervolgens om het modificatietype en de exacte base waarop het zit te voorspellen. Cruciaal is dat ook niet‑gelabelde locaties als "achtergrond"voorbeelden worden gebruikt, wat helpt te voorkomen dat het model onbekende markeringen in de verkeerde categorie forceert. Eenmaal getraind kan ORCA deze aangeleerde labels overdragen naar tienduizenden eerder ongeannoteerde locaties in het transcriptoom.
Meerdere modificaties tegelijk waarnemen
Wanneer ORCA op menselijke en muiscellen wordt toegepast, laten de auteurs zien dat het niet alleen de nauwkeurigheid van toonaangevende tools voor specifieke markeringen zoals m6A, m5C en Ψ evenaart of overtreft, maar ook markeringen kan detecteren waarvoor het nooit expliciet is getraind. Bijvoorbeeld, zelfs wanneer m6A‑data tijdens training werden achtergehouden, herkende ORCA de meeste onafhankelijk gemeten m6A‑locaties en onderscheidde ze correct van vergelijkbare, ongewijzigde sequentiemotieven. Het presteerde hetzelfde voor 2′‑O‑methylgroepen, inosine‑editingsites en een breed scala aan chemische veranderingen op ribosomaal RNA, inclusief vele zeldzame modificaties gemeten met massaspectrometrie. In het algemeen breidt ORCA de bekende catalogus van RNA‑modificatiesites sterk uit, met meervoudige toename in geannoteerde m5C, Ψ, m7G en andere laag‑abundance markeringen vergeleken met bestaande databases.
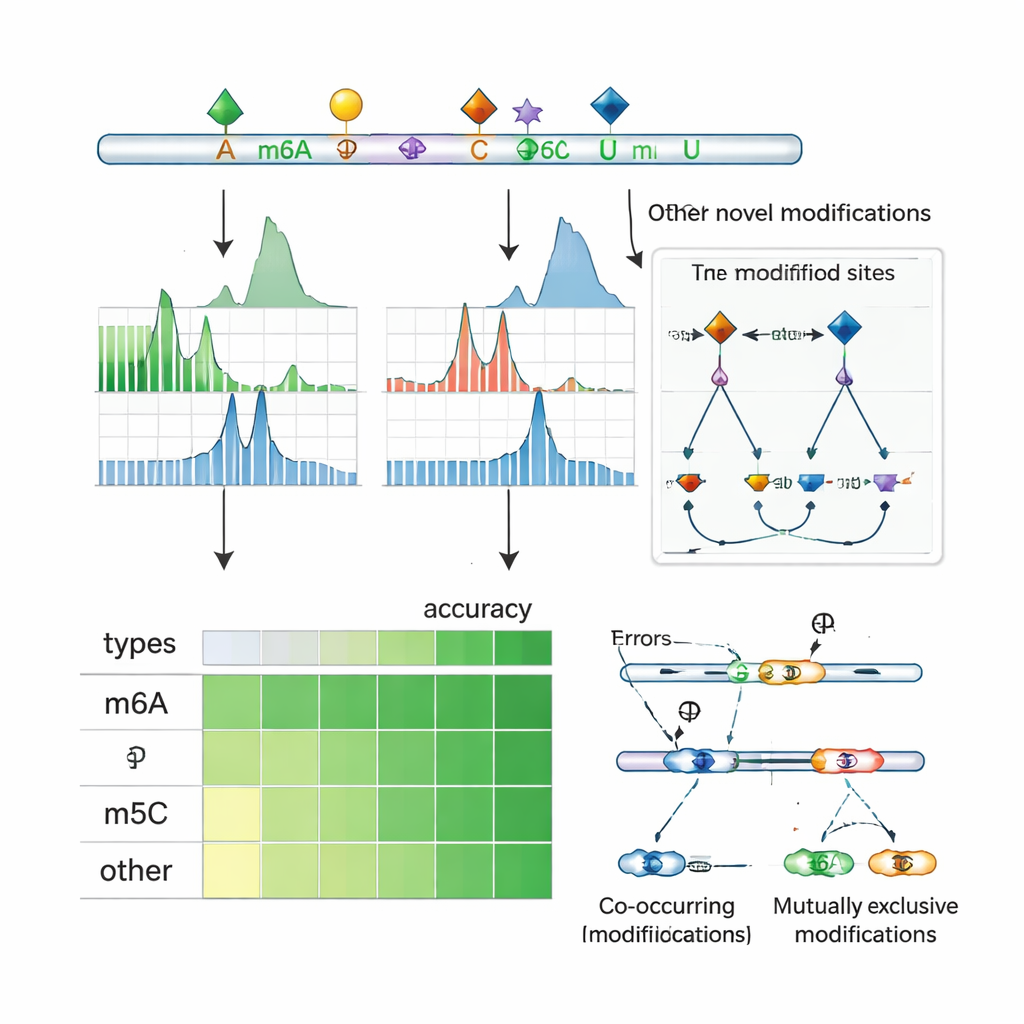
Crosstalk en controle van splicing blootleggen
Aangezien nanopore‑sequencing hele RNA‑moleculen leest, kan ORCA onderzoeken welke markeringen samen op hetzelfde transcript voorkomen en welke elkaar vaak uitsluiten. De auteurs clusteren nabije markeringen langs RNA’s en gebruiken een probabilistisch model om af te leiden of paren van locaties vaak co‑gemodificeerd zijn of elkaar in enkele moleculen wederzijds uitsluiten. Ze vinden frequente co‑voorkomen van m6A met m5C en andere markeringen, evenals vele regio’s waar een site alleen gemodificeerd is als de naburige site dat niet is. In menselijke cellijnnen vallen deze patronen vaak nabij exonen die alternatieve zijn opgenomen of overgeslagen en overlappen ze bindingsplaatsen voor splicing‑regulatoren en "reader"‑eiwitten die gemodificeerd RNA herkennen. In specifieke genen laat ORCA zien dat bepaalde splice‑varianten verrijkt zijn voor één patroon van markeringen, terwijl alternatieve varianten een ander patroon dragen, wat lokale chemische decoratie van RNA koppelt aan hoe boodschappen worden geknipt en geplakt.
Waarom dit belangrijk is voor biologie en geneeskunde
Door directe RNA‑sequencing te combineren met flexibel deep learning verandert ORCA een complexe elektrische signaalbron in een rijke, meerlaagse kaart van chemische markeringen over het transcriptoom. Voor niet‑specialisten is de belangrijkste uitkomst dat wetenschappers nu niet alleen kunnen zien waar individuele RNA‑modificaties voorkomen, maar ook hoeveel verschillende markeringen hetzelfde molecuul sieren en hoe die combinaties samenhangen met genregulatie, vooral RNA‑splicing. Dit kader maakt het mogelijk om RNA‑"epigenetica" in vele celtypen en condities te bestuderen zonder voor elke markering een nieuw experiment te ontwerpen, en effent het pad voor ontdekkingen over hoe deze kleine chemische aanpassingen bijdragen aan ontwikkeling, hersenfunctie en ziekten zoals kanker en neurologische aandoeningen.
Bronvermelding: Dong, H., Gao, Y., Cai, Z. et al. Comprehensive mapping of RNA modification dynamics and crosstalk via deep learning and nanopore direct RNA-sequencing. Nat Commun 17, 1722 (2026). https://doi.org/10.1038/s41467-026-68419-y
Trefwoorden: RNA‑modificaties, nanopore‑sequencing, deep learning, epitranscriptoom, alternatieve splicing