Clear Sky Science · nl
Toepassing van machine learning en genoomkunde voor verbetering van verwaarloosde gewassen
Verborgen gewassen met groot potentieel
In heel Afrika, Azië en Latijns‑Amerika zijn miljoenen mensen afhankelijk van zogenaamde “verwaarloosde gewassen” zoals sorghum, teff, cassave en pindakaasnoot (groundnut). Deze planten halen zelden de krantenkoppen, maar ze verdragen vaak hitte, droogte, plagen en slechte bodems beter dan wereldwijde basisgewassen zoals tarwe of rijst. Dit overzichtsartikel onderzoekt hoe twee krachtige hulpmiddelen — genoomkunde en machine learning — het potentieel van deze over het hoofd geziene gewassen kunnen ontsluiten, de lokale voedselzekerheid kunnen vergroten en daarnaast waardevolle genen kunnen opleveren die belangrijke gewassen wereldwijd kunnen versterken.
Waarom verwaarloosde gewassen ertoe doen
Verwaarloosde gewassen worden soms “neglected” of “underutilized” genoemd omdat ze veel minder wetenschappelijke en commerciële aandacht hebben gekregen dan grote exportgewassen. Toch vormen ze voedingsgrondslagen voor veel gemeenschappen en worden ze vaak geteeld in barre, marginale omstandigheden waar andere gewassen falen. In tegenstelling tot tarwe of rijst hebben de meeste verwaarloosde gewassen de verbeteringen van de Groene Revolutie en moderne hulpmiddelen zoals marker‑assisted breeding en genoombewerking gemist. Genomische projecten zoals het African Orphan Crops Consortium beginnen hun DNA te sequencen en te catalogiseren, maar ruwe genetische gegevens omzetten in praktische verbeteringen blijft een grote uitdaging.
Computers leren planten ‘lezen’
Machine learning — computermethoden die patronen leren uit grote datasets — transformeert al het veredelen van belangrijke gewassen. Door genoomsequenties te combineren met weer‑ en bodemrecords, sensorwaarden en beelden van drones of smartphones, kunnen algoritmen complexe eigenschappen voorspellen zoals opbrengst, ziektebestendigheid of graankwaliteit. Verschillende modeltypen, van beslisbomen tot diepe neurale netwerken, presteren in verschillende situaties goed. Soms kunnen traditionele statistische hulpmiddelen nog steeds even goed of beter presteren dan deep learning, maar in het algemeen levert het combineren van meerdere gegevensbronnen en modellen veredelaars nauwkeurigere en consistenterere voorspellingen dan één enkele aanpak.
Het beste halen uit schaarse data
Voor verwaarloosde gewassen is het belangrijkste obstakel niet rekenkracht maar gebrek aan data. Er bestaan slechts een handvol publieke genomische en beeldcollecties, en weinig daarvan zijn groot genoeg voor conventionele machine learning‑workflows. Toch zijn de eerste demonstraties veelbelovend. Bij sorghum bijvoorbeeld gebruikten deep learning‑modellen eenvoudige foto’s van granen om eiwit‑ en antioxidantenniveaus met hoge nauwkeurigheid te voorspellen, wat een goedkopere alternatief voor labtests biedt. In een ander geval werden nabij‑infraroodmetingen en deep learning gebruikt om voedingskundige eigenschappen in het kruid Perilla te schatten. Het overzicht betoogt dat het opbouwen van gedeelde databanken met genomen, beelden en chemische profielen voor verwaarloosde gewassen de impact van dergelijke hulpmiddelen snel zou vergroten.
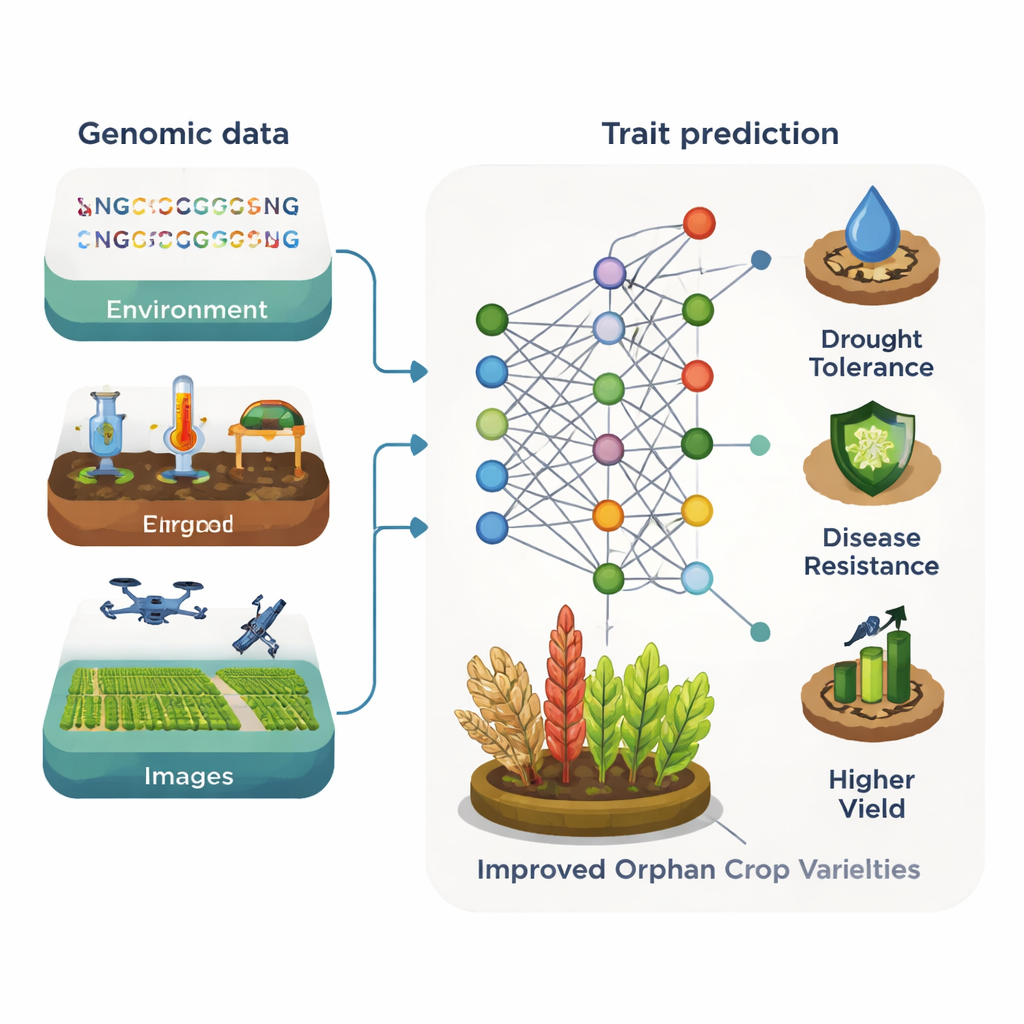
Kennis lenen van grotere gewassen
Een centraal idee in het artikel is “kennisoverdracht” tussen soorten. Veel verwaarloosde gewassen zijn nauw verwant aan belangrijke gewassen en delen grote gedeelten van DNA en vergelijkbare genen. Machine learning‑modellen kunnen deze verwantschap benutten. Hulpmiddelen die eerst zijn getraind op goed bestudeerde planten zoals Arabidopsis of mais kunnen helpen genen te identificeren voor eigenschappen zoals plantlengte, zadenkwaliteit of stresstolerantie in een minder bekende verwant. Grote taalmodellen die oorspronkelijk zijn ontwikkeld voor menselijke of plantaardige genomen kunnen DNA ook behandelen als een soort tekst en patronen leren die regulatorische regio’s of belangrijke genen markeren. Eenmaal getraind op rijke datasets, kunnen deze modellen worden verfijnd met beperkte data van verwaarloosde gewassen om genfunctie te voorspellen, doelwitten voor genoombewerking te benadrukken en efficiëntere veredeling te sturen.
Van algoritmen naar velden en boeren
De auteurs benadrukken dat technologie op zichzelf verwaarloosde gewassen niet zal transformeren. Vooruitgang hangt af van investeringen in lokale wetenschappers, partnerschappen met kleinschalige boeren en beleid dat ervoor zorgt dat gemeenschappen profiteren van nieuwe rassen. Citizen‑science‑benaderingen, waarbij boeren variëteiten direct op hun eigen land testen, kunnen waardevolle data voor machine learning genereren en tegelijk onderzoek afstemmen op lokale behoeften en voorkeuren. Omdat financiering beperkt is, beveelt het artikel een evenwichtige strategie aan: combineer goedkope traditionele veredeling en agronomie met zorgvuldig gerichte genomische en machine learning‑projecten, en deel hulpmiddelen en data tussen landen en tussen verwaarloosde en belangrijke gewassen.
Wat dit betekent voor onze voedseltoekomst
Kort gezegd concludeert het artikel dat slimmere computers plus betere genetische informatie kunnen helpen om van de huidige “vergeten” gewassen de klimaatrobuuste basisvoedselgewassen van morgen te maken. Door te leren van grote gewassen en die lessen toe te passen op kleinere — en vervolgens de ontdekkingen weer terug te voeren — kunnen machine learning en genoomkunde de zoektocht naar robuuste, voedzame variëteiten versnellen. Als dit wordt ondersteund door doordacht beleid en echte samenwerking met landbouwgemeenschappen, kan deze aanpak diëten verbeteren, veerkracht tegen klimaatverandering versterken en het agrarische instrumentarium van de wereld verbreden voorbij een smalle set basisgewassen.
Bronvermelding: MacNish, T.R., Danilevicz, M.F., Bayer, P.E. et al. Application of machine learning and genomics for orphan crop improvement. Nat Commun 16, 982 (2025). https://doi.org/10.1038/s41467-025-56330-x
Trefwoorden: verwaarloosde gewassen, machine learning, genoomkunde, gewaskweek, voedselzekerheid