Clear Sky Science · nl
Computationale voorspellers van varianten voor farmacogenomica: van evaluatie van individuele allelen tot beoordeling van bijwerkingen van antidepressiva
Waarom uw genen ertoe doen voor de veiligheid van antidepressiva
Wanneer twee mensen hetzelfde antidepressivum gebruiken, voelt de één zich misschien beter met weinig bijwerkingen, terwijl de ander te maken krijgt met ernstige problemen, waaronder medicijntoxiciteit. Deze studie onderzoekt of computerprogramma’s kleine verschillen in ons DNA kunnen lezen om te voorspellen wie antidepressiva veilig kan verwerken en wie een hoger risico heeft op schadelijke reacties, wat voorschrijven in de dagelijkse praktijk veiliger en preciezer zou kunnen maken.

Van starre labels naar flexibele genetische scores
Vandaag de dag vertrouwen veel klinieken op een systeem genaamd “star-allelen”, dat bekende DNA-varianten in genen die medicijnen verwerken groepeert in enkele brede functiecategorieën, zoals normale of verminderde activiteit. Deze benadering heeft de behandeling geholpen sturen, maar faalt wanneer iemand zeldzame of nog niet eerder geziene varianten draagt, of complexe combinaties van veranderingen die niet op de officiële lijsten staan. De auteurs stellen dat dit een groot blinde vlek is: de meeste farmacogenetische varianten zijn zeldzaam en een aanzienlijk deel van de variatie in hoe mensen medicijnen verwerken blijft onverklaard door de huidige labels.
Slimmere tools testen op bekende en nieuwe varianten
Het team evalueerde tien computationele tools die inschatten hoe schadelijk een DNA-verandering waarschijnlijk is, waaronder twee nieuwe kaders die ze ontwikkelden (PharmGScore en PharmMLScore). Eerst onderzochten ze of deze tools de functiecategorieën konden reproduceren die al waren toegewezen aan 541 gecureerde star-allelen over acht belangrijke medicijnverwerkingsgenen. Door de scores van alle varianten binnen elk haplotype op te tellen, haalden verschillende tools dezelfde prestaties als het star-systeem of deden ze die zelfs overtreffen, met PharmGScore als koploper. Vervolgens daagden ze de tools uit met gegevens uit grootschalige laboratoriumexperimenten voor twee belangrijke enzymen, CYP2C9 en CYP2C19, die veel medicijnen verwerken. Deze experimenten maten hoe duizenden individuele varianten de enzymactiviteit en eiwitniveaus beïnvloedden, waarvan de meeste nooit eerder bij patiënten waren gezien. Ook hier identificeerden de betere tools, met name de ensembles gericht op farmacogenen en CADD, nauwkeurig varianten die de enzymfunctie ernstig aantasten.
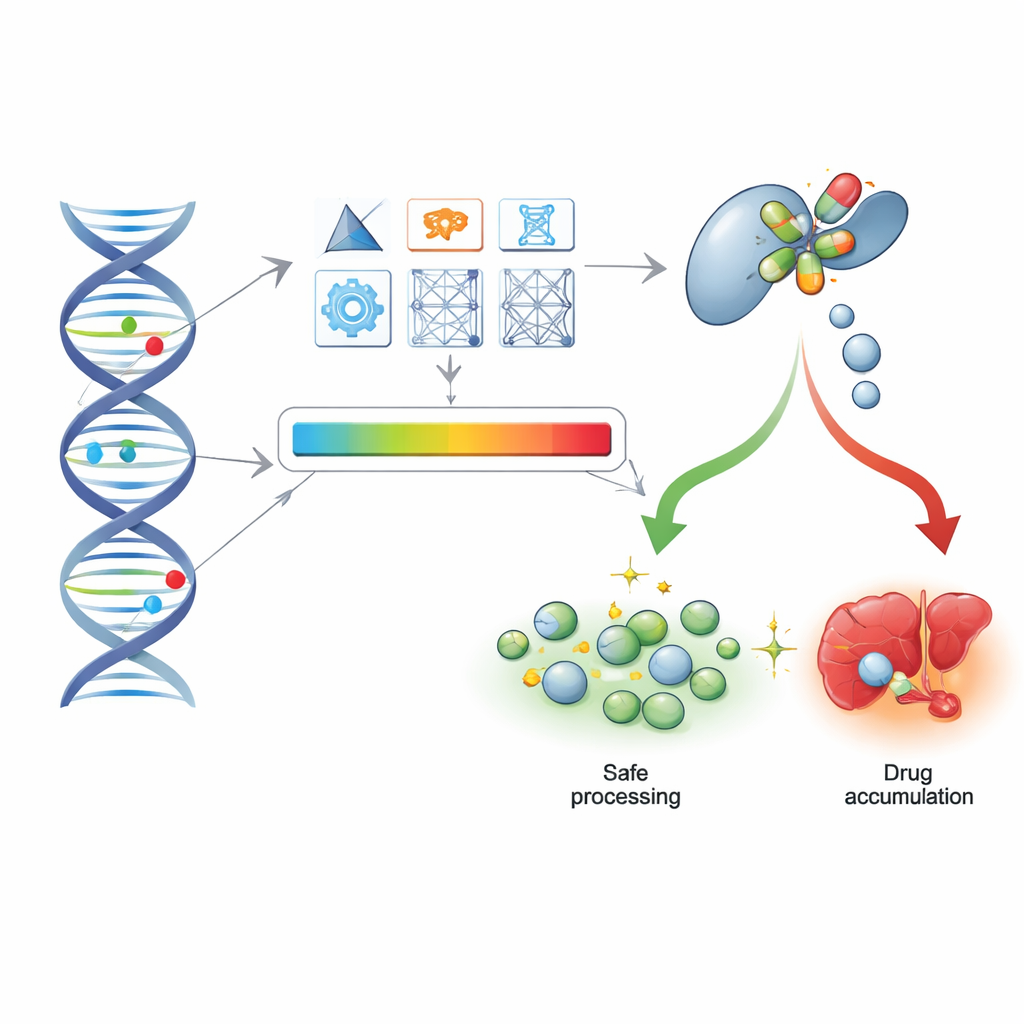
Van DNA-sequenties naar patiëntendossiers in de praktijk
Om te bekijken of deze computationele scores standhouden in de dagelijkse geneeskunde, gebruikten de onderzoekers exoomsequencinggegevens van meer dan 200.000 deelnemers uit de UK Biobank, samen met hun medicatiegeschiedenis en ziekenhuisgegevens. Ze vergeleken voorspellingen van de tools met star-allel-calls voor vijf belangrijke medicijnverwerkingsgenen en vonden dat de best scorende methoden grotendeels dezelfde functionele indelingen konden reproduceren, ondanks het feit dat exoomgegevens sommige niet-coderende en structurele veranderingen missen. Belangrijk is dat de additieve benadering — het optellen van de impact van alle varianten in een gen — goed genoeg werkte om mensen met genotypes zonder functie te onderscheiden van degenen met normale activiteit.
Mensen opsporen die risico lopen op ernstige antidepressivareacties
De auteurs richtten zich vervolgens op het gebruik en de veiligheid van antidepressiva, met speciale aandacht voor het enzym CYP2C19, dat helpt bij het afbreken van meerdere veelvoorkomende antidepressiva. Onder meer dan 75.000 antidepressivagebruikers bekeken ze twee uitkomsten: frequent wisselen van medicatie, als ruwe maat voor slechte respons, en ziekenhuis- of overlijdensgegevens met codes voor vergiftiging door antidepressiva. Hoewel noch star-allelen noch de meeste scores een sterk of duidelijk signaal voor medicatiewisseling lieten zien, onthulden ze wel een betekenisvol patroon voor ernstige bijwerkingen. Draagsters en dragers van schadelijke CYP2C19-varianten hadden ongeveer 20–35% hogere odds op ernstige vergiftigingscodes door antidepressiva in hun dossiers, zowel wanneer geclassificeerd door star-allelen als door de best presterende computationele tools zoals PharmGScore, PharmMLScore en CADD. Deze relatie bleef vergelijkbaar toen analyses werden beperkt tot gevallen zonder gedocumenteerde zelfbeschadiging.
Wat dit kan betekenen voor toekomstige voorschriften
Samenvattend laat de studie zien dat doordacht ontworpen computationele voorspellers hetzelfde nauwkeurigheidsniveau kunnen bereiken als het traditionele star-allel-systeem, terwijl ze het grootste zwakpunt daarvan overwinnen: de onmogelijkheid om nieuwe, zeldzame of complexe genetische varianten te verwerken. Door ruwe DNA-sequenties te vertalen naar continue risicoscores die over het hele genoom werken, zouden deze tools clinici uiteindelijk in staat kunnen stellen verder te kijken dan een korte lijst bekende genotypen en beter te voorspellen wie een hoger risico heeft op ernstige bijwerkingen van antidepressiva. Voordat ze routinematig in de zorg worden gebruikt, is meer validatie en integratie met andere klinische factoren nodig, maar dit werk vormt een sterke basis voor veiliger en meer gepersonaliseerd voorschrijven op basis van uitgebreide genetische informatie.
Bronvermelding: Hajto, J., Piechota, M., Krätschmer, I. et al. Computational variant predictors for pharmacogenomics: from evaluation of single alleles to assessment of adverse drug reactions to antidepressants. Pharmacogenomics J 26, 8 (2026). https://doi.org/10.1038/s41397-026-00399-0
Trefwoorden: farmacogenomica, antidepressiva, genetische varianten, bijwerkingen van geneesmiddelen, computationale voorspelling