Clear Sky Science · nl
Neurale schatting en bewerking van verlichting vanuit één gezichtspunt voor dynamische lichtvelddisplays
Waarom je virtuele wereld bij je woonkamer moet passen
Iemand die ooit een virtual- of mixed-reality-headset heeft gedragen, kent het: een digitaal object dat er vreemd misplaatst uitziet, met verlichting en schaduwen die niet helemaal overeenkomen met de kamer waar je je bevindt. Dit artikel pakt dat probleem aan. De auteurs presenteren een methode waarmee headsets de verlichting in je echte omgeving kunnen “begrijpen” aan de hand van slechts één camerazicht, en die kennis gebruiken om virtuele objecten eruit te laten zien alsof ze écht in jouw wereld thuishoren—zonder speciale light probes, uitgebreide captures of zware herkalibratie.
Het lichtveld in de ruimte makkelijker hanteerbaar maken
In de natuurkunde en computergraphics bepaalt het volledige “lichtveld” van een scène hoe deze eruitziet: alle lichtstralen die door de ruimte in alle richtingen stromen. Dit veld exact reconstrueren vereist normaal veel data, met veel beelden en nauwkeurige metingen. Moderne 3D-technieken zoals neurale radiance fields kunnen scènes in neurale netwerken opslaan, maar ze “bakken” doorgaans de verlichting die tijdens de opname aanwezig was in. Dat betekent dat de virtuele scène alleen goed uitziet onder die oorspronkelijke omstandigheden en instabiel wordt wanneer de verlichting in de echte kamer verandert. De auteurs willen deze beperking doorbreken door een compacte beschrijving van echte wereldverlichting te vinden uit minimale data en die te gebruiken om een neurale 3D-scène flexibel te herbelichten.
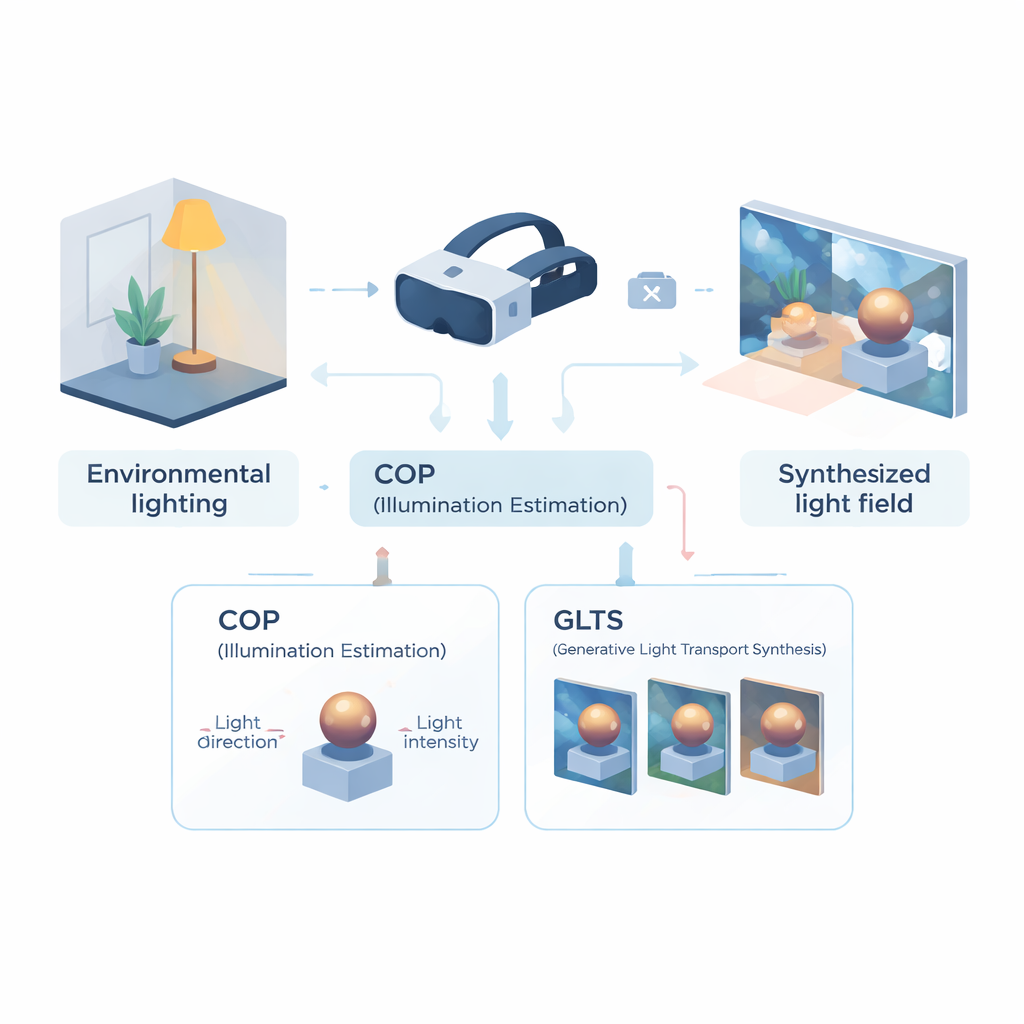
Een headset leren de kamer te lezen
Het eerste deel van het raamwerk is een computational optical perception (COP)-module, ontworpen om verlichting uit één camerazicht te lezen. In plaats van het gehele lichtveld te reconstrueren, richt COP zich op de dominante lichtbron: richting en sterkte. Een multi-schaals neuraal netwerk doorzoekt de invoerafbeelding op fysische aanwijzingen—heldere reflecties, schaduwverlopen en slagschaduwen—terwijl een speciale interpolatiestap corrigeert voor de niet-lineaire manier waarop camera’s helderheid comprimeren. Dit levert numerieke schattingen van lichtintensiteit en -richting op die sterker overeenkomen met de echte energie in de scène. Een tweede fase, de semantische interpreter, verfijnt deze getallen en genereert een korte tekstachtige beschrijving van de verlichting (bijvoorbeeld dat het licht van boven en rechts komt). Deze combinatie van cijfers en woorden maakt de schatting stabieler en makkelijker toepasbaar in de volgende stappen.
Objecten opnieuw schilderen met nieuw licht
Gewapend met deze compacte beschrijving van de verlichting neemt de tweede module—generative light transport synthesis (GLTS)—het over. GLTS begint vanuit een bestaande neurale 3D-representatie van een object of scène, eenmaal gerenderd onder de oude, ingebakken verlichting. Geleid door de afgeleide lightrichting, intensiteit en de tekstuele beschrijving, “herschildert” een generatief netwerk deze weergave zodat highlights en schaduwen overeenkomen met de nieuwe omgeving. Om het resultaat zowel realistisch als object-specifiek te houden, combineert GLTS twee vormen van sturing: globale controle vanuit de verlichtingsparameters en fijne details rechtstreeks uit de waargenomen afbeelding. Via een gespecialiseerde trainingsprocedure die zich uitsluitend richt op hoe een enkel object reageert op verschillende verlichtingstoestanden, leert het model reflecties te verplaatsen en schaduwranden te verzachten op fysiek plausibele manieren in plaats van simpelweg een generieke stijlfilter toe te passen.
Een consistent 3D-lichtveld opbouwen uit vele gezichtspunten
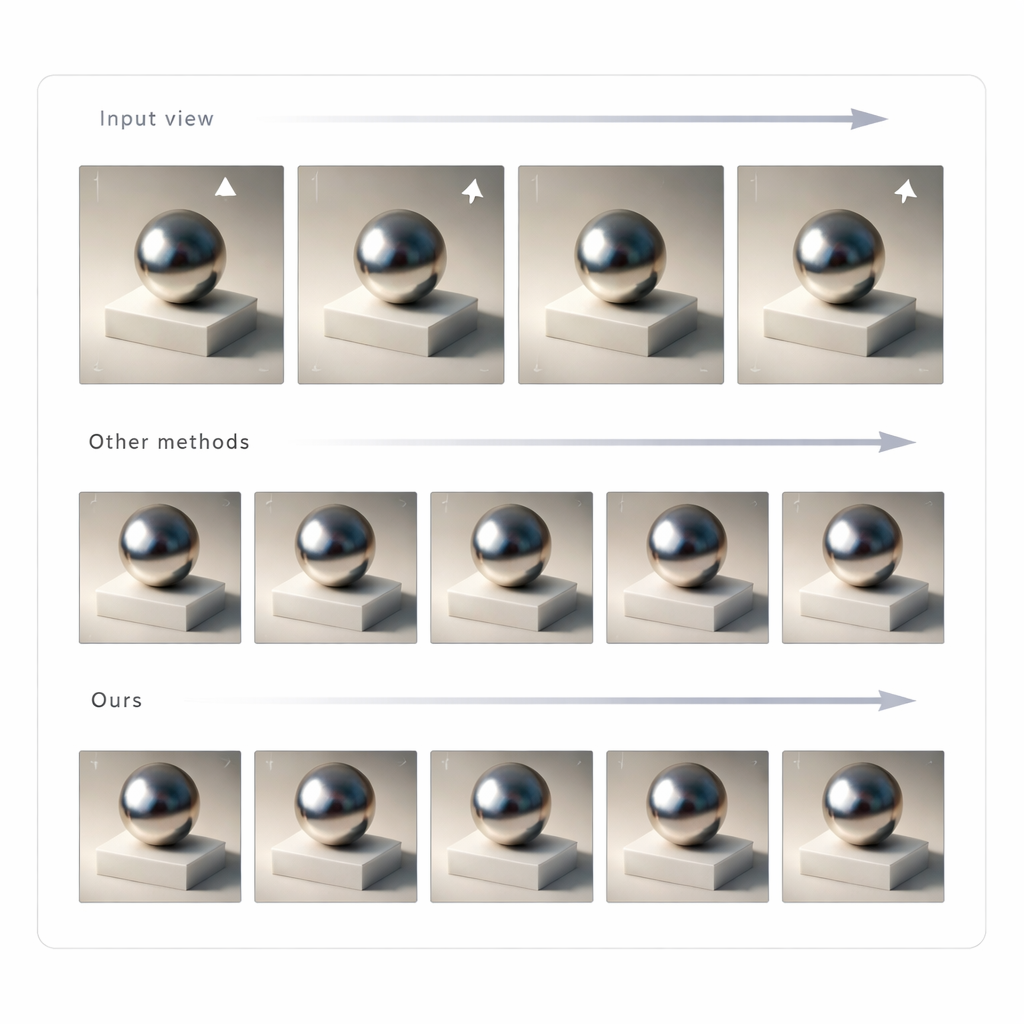
Het aanpassen van een enkele afbeelding is niet genoeg voor overtuigende mixed reality; de verlichting moet consistent blijven terwijl je je hoofd beweegt. Om dit te bereiken gebruikt het team GLTS om een set herbelichte afbeeldingen vanuit vele gezichtspunten te genereren en behandelt deze vervolgens als doelen voor het herbouwen van de 3D-scène. Een gezamenlijke optimalisatie past tegelijkertijd de neurale 3D-representatie en de virtuele camerapositities aan zodat het renderen van het nieuwe model alle gesynthetiseerde weergaven reproduceert. Deze stap corrigeert subtiele vervormingen die door het generatieve netwerk zijn geïntroduceerd en produceert een coherent 3D-object waarvan het uiterlijk stabiel en geloofwaardig blijft vanuit elke hoek. Het team testte hun methode tegen meerdere state-of-the-art herbelichtingsaanpakken en vond dat het scherpere overeenstemming met ground-truth-beelden en natuurlijker ogende schaduwen en reflecties opleverde, gemeten via zowel pixelgebaseerde als perceptiegerichte metriek.
Wat dit betekent voor toekomstige headsets
Voor niet-specialisten is de belangrijkste conclusie dat dit werk laat zien hoe toekomstige VR-, AR- en mixed-reality-apparaten virtuele inhoud zouden kunnen aanpassen aan reële verlichting met slechts een korte blik door de camera van de headset. In plaats van tijdrovende opnameopstellingen of het hertrainen van op maat gemaakte modellen voor elke nieuwe scène, schat het systeem de belangrijkste verlichtingscondities, genereert opnieuw hoe de scène onder die condities zou moeten verschijnen en bouwt een consistente 3D-representatie terug. Het resultaat is dat virtuele objecten in helderheid, glans en schaduwen reageren op je omgeving zoals echte objecten dat doen, wat de weg vrijmaakt voor mixed-reality-ervaringen die minder voelen als opgelegde grafische elementen en meer als echte aanvullingen op de fysieke wereld.
Bronvermelding: Hong, X., Xie, J., Sheng, J. et al. Single-view neural illumination estimation and editing for dynamic light field display. Light Sci Appl 15, 147 (2026). https://doi.org/10.1038/s41377-026-02234-4
Trefwoorden: verlichting voor mixed reality, neurale lichtvelden, herbelichting vanuit één gezichtspunt, virtual reality-displays, computationele beeldvorming