Clear Sky Science · nl
Multimodale beeldherkenning voor cultureel erfgoed op basis van een quantum-klassiek multimodaal fusienetwerk
Waarom het belangrijk is computers over oude schatten te leren
Culturele schatten in musea en archieven worden steeds vaker gefotografeerd en online gezet, maar de meeste van deze afbeeldingen zijn slecht of helemaal niet gelabeld. Dat maakt het moeilijk voor bezoekers, leraren en onderzoekers om te vinden wat ze zoeken en beperkt hoe diep het publiek het gedeelde erfgoed van de mensheid kan verkennen. Dit artikel onderzoekt een nieuwe manier om dergelijke beelden automatisch te herkennen en te ordenen door twee zelden gecombineerde ideeën samen te brengen: museumcollecties en quantumcomputing.
Van stoffige depots naar digitale collecties
Musea herbergen tegenwoordig miljoenen objecten, van brons en lakwerk tot geborduurde gewaden. Veel instellingen haasten zich om deze bezittingen te digitaliseren zodat iedereen met een internetverbinding ze kan bekijken. Zodra beelden echter online staan, moeten ze in de juiste categorieën worden geplaatst—zoals emaille, jade, zijde of brokaat—om echt nuttig te zijn. Conventionele AI-tools kijken meestal alleen naar de pixels in elke afbeelding. Ze negeren de rijke tekstuele beschrijvingen die conservatoren en historici aan objecten toevoegen, terwijl die bijschriften vaak materialen, kleuren en motieven noemen die niet direct zichtbaar zijn. Naarmate collecties groter worden, hebben klassieke algoritmen ook moeite met snelheid, energiegebruik en complexiteit.
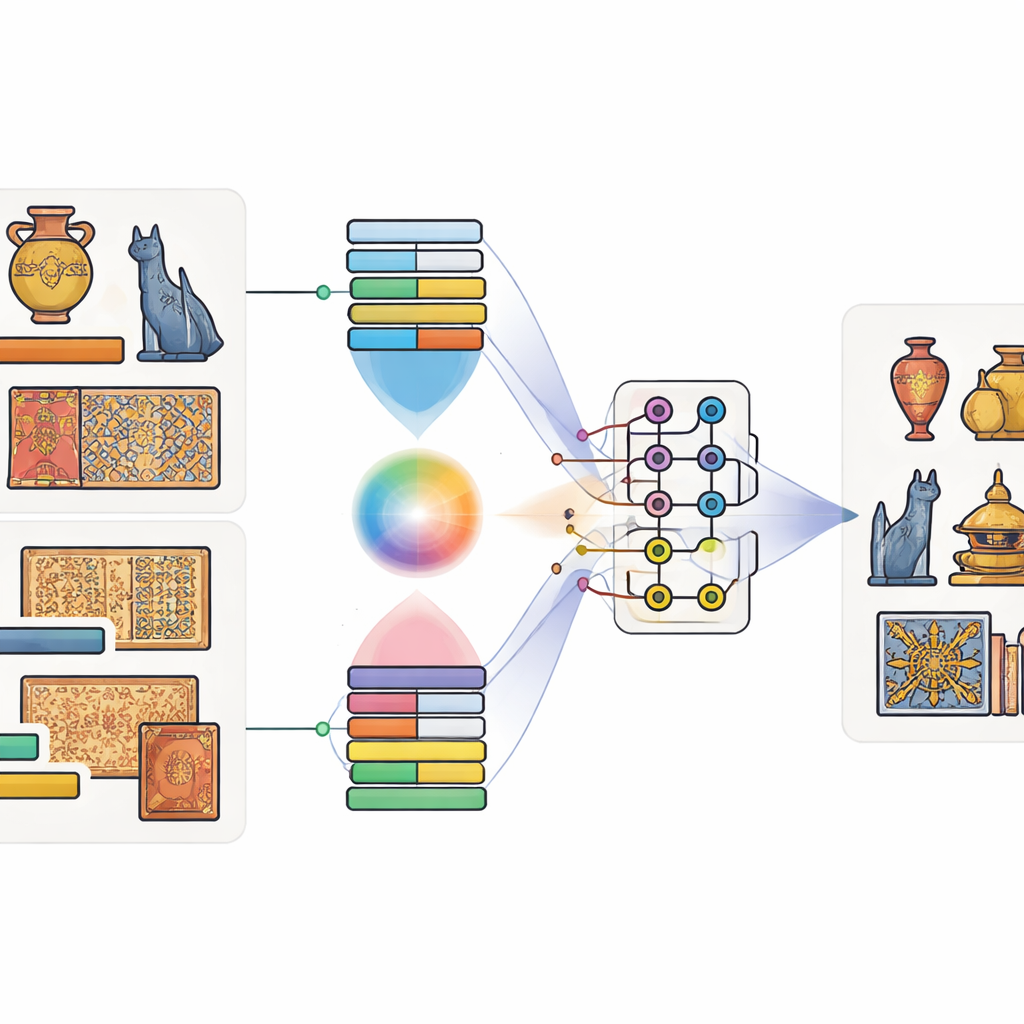
Beelden koppelen aan woorden, en bits aan qubits
De auteurs stellen een model voor dat zij het Quantum-Classical Multimodal Fusion Model noemen. "Multimodaal" betekent simpelweg dat het tegelijk naar meer dan één soort informatie kijkt—in dit geval zowel de afbeelding van een artefact als de bijbehorende bijschrifttekst. Eerst worden gevestigde hulpmiddelen die op enorme datasets zijn getraind gebruikt: een diep beeldnetwerk om vormen en texturen vast te leggen, en een taalmodel om de betekenis van het bijschrift te vatten. Een speciaal attentie-mechanisme leert vervolgens welke regio’s van de afbeelding doorgaans bij welke woorden horen. Bijvoorbeeld, wanneer een bijschrift "gouden draak" vermeldt, leert het model zich te richten op goudkleurige gebieden met draakachtige vormen. Dit levert een gezamenlijke beschrijving op die zicht en taal vermengt.
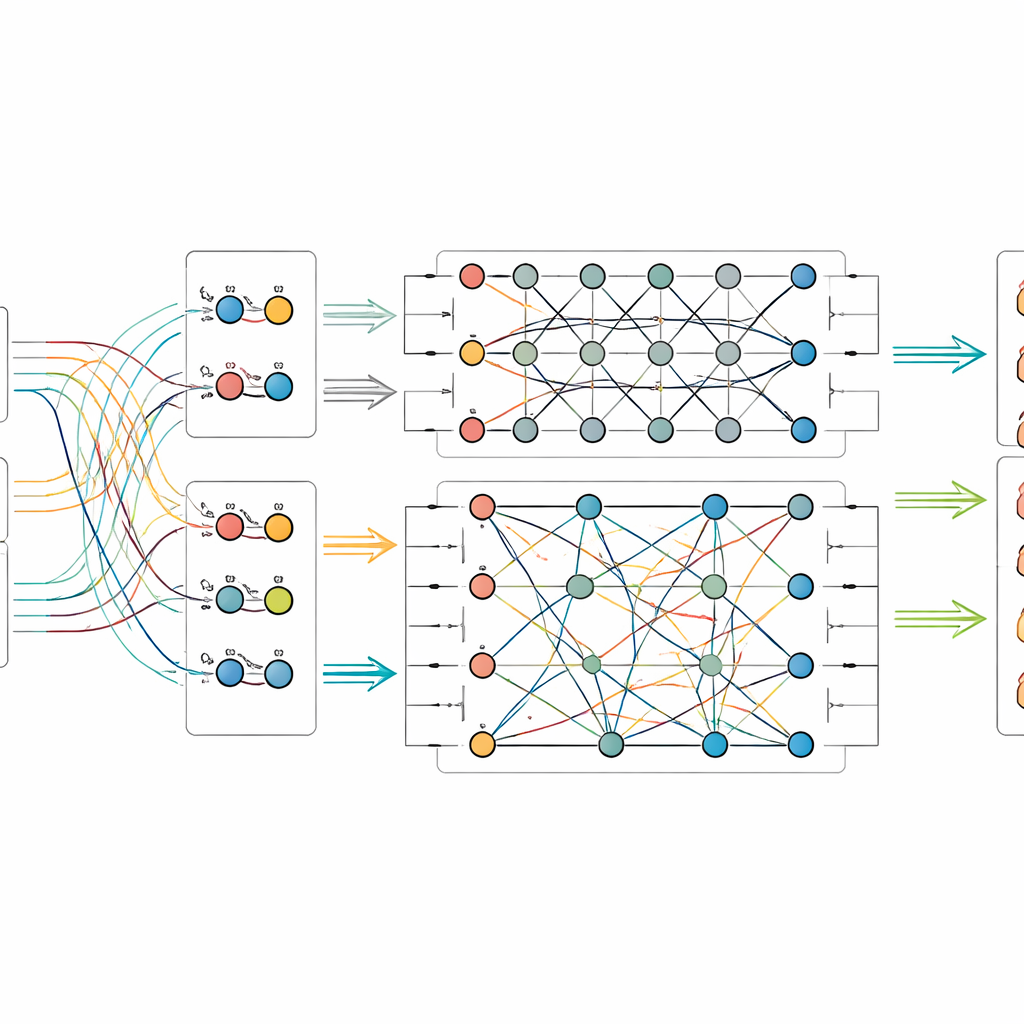
Quantumcircuits laten signalen mengen
Zodra de beeld- en tekstkenmerken zijn geëxtraheerd, voert het model ze in een klein gesimuleerd quantumcircuit. Omdat hedendaagse quantumhardware slechts over een bescheiden aantal qubits beschikt, comprimeren de auteurs de informatie met een methode die veel klassieke waarden inpakt in de amplitudes van een paar qubits. Binnen het quantumdeel ontwerpen ze een tweefasig circuit dat herhaaldelijk rotaties op individuele qubits toepast en deze vervolgens verstrikt—waardoor hun toestanden onderling afhankelijk worden. Deze structuur is bedoeld om subtiele relaties tussen visuele patronen en bijschrift-signalen bloot te leggen die anders over het hoofd gezien zouden kunnen worden. Na deze quantumverwerking wordt de toestand van de qubits gemeten en omgezet in gewone getallen, die vervolgens aan een laatste classifier worden doorgegeven die de categorie van het object voorspelt.
De nieuwe aanpak op de proef gesteld
Om te onderzoeken of hun methode echte voordelen biedt, stelden de onderzoekers twee nieuwe datasets samen uit het Palace Museum: één van fysieke artefacten zoals emaille, goud- en zilverwerk, lakwerk, brons en jade, en een andere gericht op textiel zoals zijde, satijn, brokaat en de ingewikkelde weefstijl bekend als kesi. Elke afbeelding wordt geleverd met een officieel bijschrift en een betrouwbare label uit de museumadministratie. Ze vergeleken hun quantum–klassieke fusionmodel met een reeks sterke tegenhangers, waaronder zuivere beelssystemen, zuivere tekstsystemen en andere technieken die beide combineren. In beide datasets behaalde het nieuwe model de hoogste scores voor nauwkeurigheid en verwante maatstaven, en overtrof het zelfs geavanceerde multimodale en quantum-geïnspireerde baselines. Verdere experimenten toonden aan hoe de prestaties afhangen van het aantal qubits en de diepte van het circuit, en dat het robuust blijft zelfs wanneer veelvoorkomende typen quantumruis in de simulatie worden geïntroduceerd.
Wat dit kan betekenen voor toekomstige museumbezoekers
Voor niet-specialisten is de kernboodschap dat het mengen van beelden, woorden en quantum-geïnspireerde verwerking computers kan helpen beter verschillende soorten culturele objecten uit elkaar te houden. Hoewel de quantumonderdelen momenteel op simulatoren draaien in plaats van op volwaardige quantummachines, suggereert de studie een pad naar efficiëntere en expressievere hulpmiddelen naarmate de hardware rijpt. In praktische termen zouden dergelijke systemen musea en archieven kunnen helpen nieuwe uploads automatisch te ordenen, oude dossiers op te schonen en het eenvoudiger maken voor mensen om te zoeken naar "jade rituele vaten" of "geborduurde draakenganzen" en ze daadwerkelijk te vinden. Het werk suggereert dat quantumcomputing een nuttige nieuwe route kan worden voor het begrijpen en bewaren van cultureel erfgoed in het digitale tijdperk.
Bronvermelding: Fan, T., Wang, H., Zhao, Y. et al. Multimodal cultural heritage image recognition based on quantum and classical multimodal fusion network. npj Herit. Sci. 14, 160 (2026). https://doi.org/10.1038/s40494-026-02419-5
Trefwoorden: cultureel-erfgoedafbeeldingen, quantum machine learning, multimodale fusie, museumd digitalisering, beeldherkenning