Clear Sky Science · nl
Identificatie van visuele informatie en Q&A van erfgoeddragers van immaterieel cultureel erfgoed met behulp van een verbeterd Graph-Retrieval-framework
Verborgen tradities naar het digitale tijdperk brengen
In heel China bewaren meesters van traditionele opera, papiersnijden, schaduwspel en andere levende kunsten vaardigheden die generaties lang zijn doorgegeven. Veel van wat we over deze erfgoeddragers weten, bestaat echter alleen in verspreide bestanden en afbeeldingen online, waardoor het voor het publiek — en zelfs voor onderzoekers — moeilijk is betrouwbare informatie te vinden. Dit artikel introduceert een nieuw computerframework dat automatisch de "visuele visitekaartjes" van dragers van immaterieel cultureel erfgoed (ICE) uitleest en vervolgens geavanceerde taalmodellen gebruikt om vragen te beantwoorden en leesbare rapporten over hen te genereren.
Van beeldkaartjes naar gestructureerde kennis
Veel culturele instellingen publiceren tegenwoordig digitale kaartjes die tekst, lay-out en eenvoudige grafische elementen combineren om elke drager voor te stellen: naam, ambacht, locatie, biografie en meer. Mensen kunnen deze in één oogopslag scannen, maar computers hebben moeite omdat de kaartjes uit verschillende regio’s komen, uiteenlopende ontwerpen gebruiken en vaak ontbrekende of beschadigde tekst bevatten. De auteurs bouwen een grote dataset van 5.237 dergelijke visitekaartjes voor Chinese ICE-dragers, elk zorgvuldig gelabeld met tien sleuteltypen informatie, zoals projectnummer, projectnaam, regio, geslacht, werkunit en een korte beschrijving. Eerst gebruiken ze optische tekenherkenning (OCR) om de tekst te lezen en vast te leggen waar elk fragment op het kaartje voorkomt, daarna zetten ze grote taalmodellen in om labels te standaardiseren voordat menselijke experts ze verifiëren.
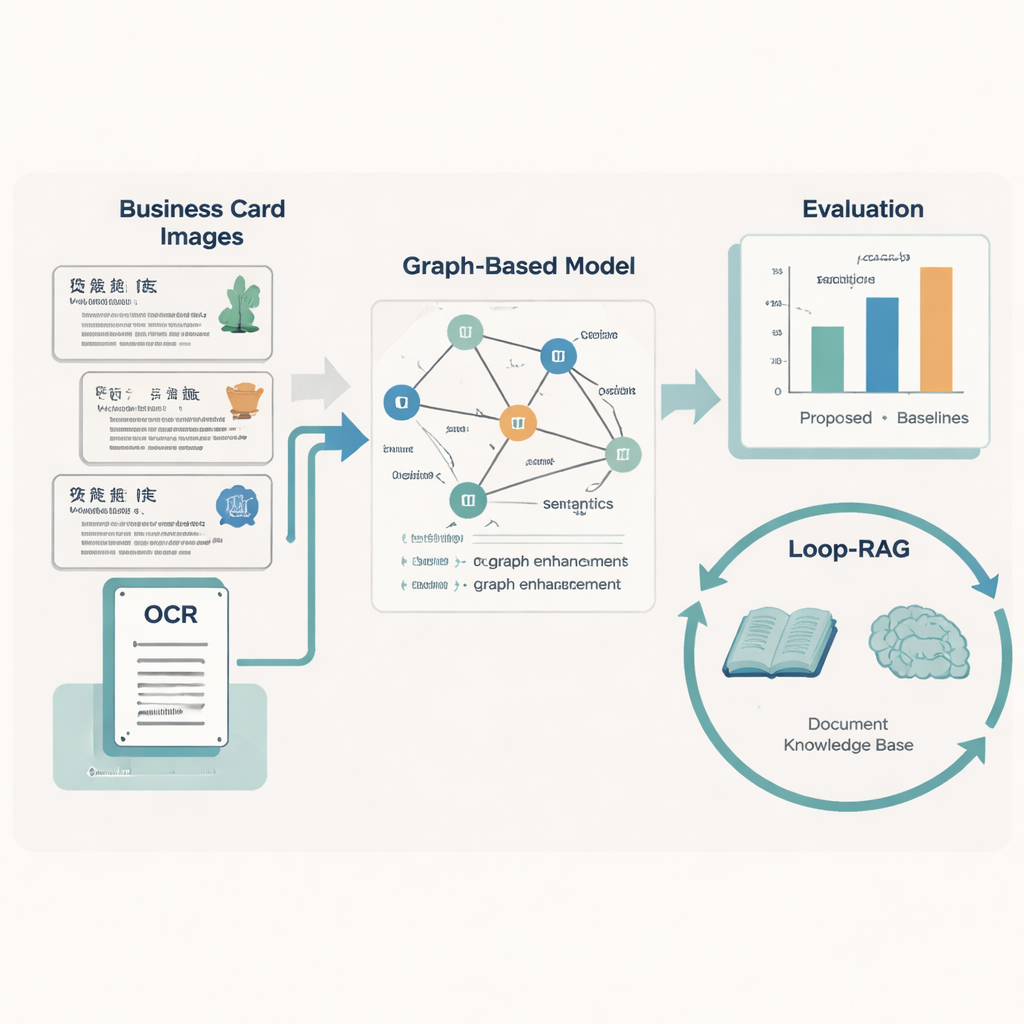
Machines leren lay-out en betekenis te lezen
Om elk kaartje om te zetten in schone, gestructureerde data, ontwerpt het team een "Graph-Retrieval"-model dat nabootst hoe mensen zowel woorden als lay-out gebruiken. Elk tekstfragment op een kaartje wordt een knoop in een graaf, en de ruimtelijke relaties tussen fragmenten — links, rechts, boven, onder — vormen de randen. Een taalkundig onderdeel gebaseerd op RoBERTa en een bidirectionele LSTM leert de betekenis van de tekst, ondersteund door een aangepaste woordenlijst van bijna 5.000 ICE-specifieke termen zodat ongewone ambachtsnamen of lokale uitdrukkingen correct worden behandeld. Bovenop dit alles verspreidt een graph neural network informatie over aangrenzende knopen, wat de voorspellingen over wat elk tekstfragment vertegenwoordigt verbetert (bijvoorbeeld beslissen of een plaatsnaam een regio of een werkunit is).
Het systeem robuust maken tegen rommeligheid uit de praktijk
Authentieke erfgoeddocumenten zijn zelden perfect: kaartjes kunnen versleten, bijgesneden of slecht gescand zijn. Om hiermee om te gaan versterken de auteurs hun graafmodel met drie ideeën uit data-augmentatie. Ze maskeren willekeurig enkele knopen zodat het systeem leert ontbrekende informatie uit de context af te leiden; ze verwijderen willekeurig enkele randen zodat het tegen veranderingen in lay-out kan; en ze voegen een positioneel attentiemechanisme toe dat de algehele "leesvolgorde" van elementen op een kaartje vastlegt. Samen helpen deze technieken het model te generaliseren naar veel stijlen en kwaliteiten van documenten. In tests tegen negen bekende concurrerende methoden behaalt de nieuwe aanpak de hoogste macro-gemiddelde F1-score (0,928) op de ICE-kaartjesdataset en staat ook bovenaan op vijf openbare documentbenchmarks, wat suggereert dat het breed toepasbaar is buiten erfgoedtoepassingen.
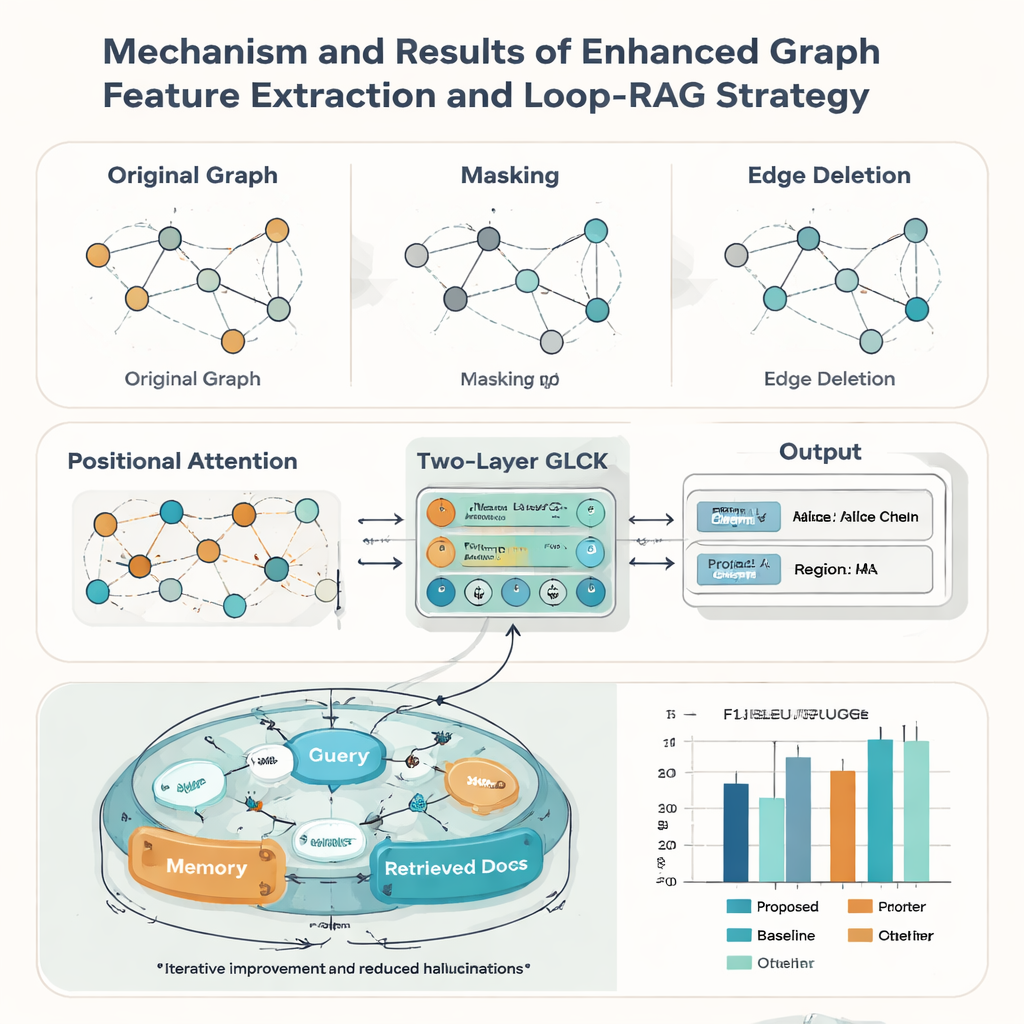
Slimmere vraagbeantwoording met looping retrieval
Tekst herkennen is slechts de helft van het verhaal; de tweede bijdrage van het artikel is een Loop-RAG (Loop Retrieval-Augmented Generation)-strategie die werkt met grote taalmodellen zoals GPT-4, Llama en ChatGLM. Traditionele retrieval-augmented systemen halen achtergronddocumenten één keer op en genereren daarna een antwoord, wat nog steeds onvolledig of onjuist kan zijn. Loop-RAG voegt daarentegen een binnenste lus toe die herhaaldelijk controleert of het taalmodel genoeg informatie heeft voor het huidige antwoord en, zo niet, een gerichte zoekactie in een vectoriseerde ICE-kennisbank activeert. Een buitenste lus bestudeert vervolgens veel eerdere interacties om te leren welke retrievalpaden en promptstijlen het beste werken, waardoor het aantal nutteloze zoekacties en feitelijke fouten geleidelijk afneemt.
Van ruwe dossiers naar betrouwbare culturele verhalen
Met dit gecombineerde framework kan het systeem automatisch korte rapporten over een drager aanmaken — die hun ambacht, regio, representatieve werken en status samenvatten — en duizenden feitelijke vragen over personen en praktijken beantwoorden. Gemeten met standaardtaalkwaliteitsscores zoals BLEU, METEOR en ROUGE, overtreft Loop-RAG met GPT-4 zowel eenvoudige taalmodellen als eenvoudigere retrieval-opstellingen, terwijl het ook de beste nauwkeurigheid behaalt (F1 tot 0,941) in vraagbeantwoording, zelfs wanneer slechts enkele voorbeelden beschikbaar zijn. Voor een lezerspubliek betekent dit dat toekomstige platforms voor cultureel erfgoed interactieve, betrouwbare uitleg van traditionele kunsten op aanvraag kunnen bieden, waarbij verspreide digitale dossiers worden omgezet in rijke, navigeerbare verhalen die helpen levende tradities zichtbaar en gewaardeerd te houden.
Bronvermelding: Wang, R., Zhang, X., Liu, Q. et al. Visual information identification and Q&A of intangible cultural heritage inheritors by using enhanced Graph-Retrieval framework. npj Herit. Sci. 14, 113 (2026). https://doi.org/10.1038/s40494-026-02384-z
Trefwoorden: immaterieel cultureel erfgoed, informatie-extractie, graph neural networks, retrieval-augmented generation, digitale geesteswetenschappen