Clear Sky Science · nl
Semantische segmentatie van Boeddha-gezichtspuntenwolkjes met kennis-gestuurde regio-groei
Het gezicht van de geschiedenis lezen
In rotsen en tempelwanden uitgehouwen Boeddhabeelden zijn meer dan fraaie kunstwerken — het zijn driedimensionale archieven van religieus geloof, artistieke smaak en culturele uitwisseling door de eeuwen heen. Deze studie laat zien hoe computerwetenschappers en erfgoedspecialisten deze stenen gezichten in detail kunnen “lezen” door automatisch ogen, neus, mond en andere kenmerken van dichtbezette 3D-metingen te scheiden, zelfs wanneer er geen voorbeeldlabels zijn om van te leren. Het doel is om zwijgende steen om te zetten in meetbare gegevens die historici helpen stijlen te vergelijken, veranderingen in de tijd te volgen en zorgvuldige conservering te plannen.
Waarom digitale gezichten ertoe doen
Op beroemde locaties zoals Dunhuang, Yungang en Longmen verschillen Boeddhagezichten subtiel per dynastie en regio — sommige voller, sommige slanker, met zachtere ogen of meer prominente neuzen. Kunsthistorici beschrijven deze verschillen traditioneel met het blote oog; nu leggen hoogprecisie 3D-scans het oppervlak van beelden vast als miljoenen punten in de ruimte. Deze “puntenwolken” zijn echter rommelig: ze bevatten geen kleur of textuur en geven geen ingebouwde aanwijzing waar de ogen ophouden en de wangen beginnen. Bestaande automatische methoden vereisen vaak veel handgelabelde trainingsvoorbeelden, die voor erfgoedbeelden simpelweg niet bestaan, of ze splitsen oppervlakken uitsluitend op basis van geometrie en negeren de beeldhouwkundige regels die kunstenaars in werkelijkheid volgden.

Algoritmen de regels van het gezicht leren
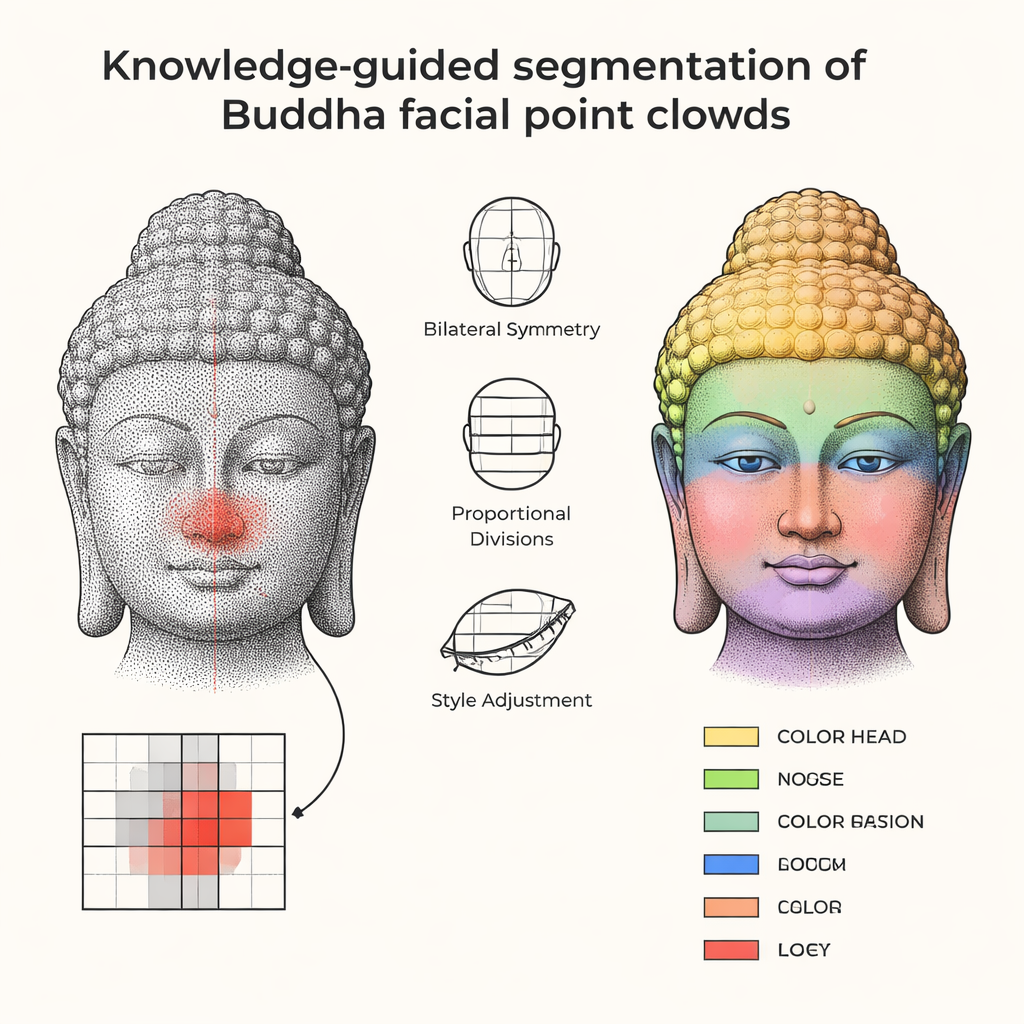
In plaats van te proberen te leren van schaarse data, beginnen de auteurs bij de kennis die beeldhouwers zelf gebruikten. Traditionele boeddhistische handboeken beschrijven standaardgezichtsproporties, zoals het verdelen van het gezicht in gelijke derden voor voorhoofd, neus en kin, en het behouden van symmetrie rond een centrale as. De onderzoekers vertalen deze culturele en anatomische knowhow naar eenvoudige geometrische regels: een symmetrievlak in het midden; een verticale lijn die door het midden van de neus loopt; en verhoudingen die de posities en afmetingen van ogen, neus, mond, oren en kin relateren. Deze regels zijn geen starre sjablonen: ze bevatten aanpasbare parameters zodat vollere Tang-stijl gezichten en slankere Song-stijl gezichten beide binnen een flexibel maar herkenbaar kader passen.
Regio’s laten groeien vanaf zaden
Vertrekkend van een gereinigde 3D-scan brengt de methode eerst het Boeddhagezicht in positie zodat het recht vooruit kijkt, en projecteert vervolgens het oppervlak op een vierkant raster, waardoor de 3D-vorm iets wordt als een geschaduwd hoogtekaart. Binnen dit raster kiest het algoritme startposities of “zaden” voor elk gelaatskenmerk, geholpen door de eerdere regels: het neuszaad ligt nabij de centrale verticale lijn en een lokale hoogtepunt, de ogen worden geplaatst als symmetrische pieken aan weerszijden, de mond bevindt zich onder de neus in een ondiepe holte, enzovoort. Vanuit elk zaad “groeit” de computer een regio naar buiten toe en voegt naburige cellen alleen toe wanneer hun hoogte en helling passen bij wat je voor bijvoorbeeld een neuskam zou verwachten in plaats van een wang. Extra stappen ruimen het resultaat op: losse stukjes worden bijgesneden, kleine gaten gevuld en omtrekken voorzichtig gladgemaakt zodat de gesegmenteerde ogen, lippen en kin continu en plausibel ogen voor zowel de computer als een menselijke expert.
De methode op de proef gesteld
Het team testte hun aanpak op vijftien Boeddhagezichten — negen synthetische modellen met gecontroleerde vormen en zes echte scans van bekende Chinese erfgoedlocaties. Ze beoordeelden de kwaliteit door te meten hoe goed de automatisch gesegmenteerde regio’s overlappen met zorgvuldige handgetekende contouren van specialisten en hoe nauw de berekende grenzen overeenkomen met de contouren van experts. Voor ogen, wenkbrauwen, oren, neus, mond en kin behaalde de methode hoge scores, wat betekent dat de meeste punten correct aan het juiste kenmerk werden toegewezen. Belangrijk is dat de resultaten stabiel waren over verschillende beeldhouwstijlen en niveaus van oppervlakteslijtage. Toen de auteurs hun aanpak vergeleken met een populair deep-learningmodel dat met slechts enkele gelabelde voorbeelden was getraind, worstelde het datahongerige netwerk aanzienlijk, terwijl de kennis-gestuurde methode accuraat bleef zonder grote trainingssets.
Wat dit betekent voor erfgoed
Door traditionele meetregels van beeldhouwers te coderen in een modern algoritme toont deze studie dat computers Boeddhagezichten in 3D kunnen segmenteren met weinig of geen handmatige labeling, terwijl ze toch de culturele logica van het oorspronkelijke kunstwerk respecteren. Voor historici opent dit de deur naar systematische, kwantitatieve vergelijkingen van gelaatsstijlen tussen locaties en perioden; voor conservatoren biedt het een nauwkeurige manier om schade te monitoren of digitale restauratie te begeleiden. In wezen verandert de methode eeuwenoude conventies over het ideale Boeddhagezicht in een praktisch instrument om de stenen gezichten te lezen, te behouden en te begrijpen die al meer dan duizend jaar over tempels en grotten waken.
Bronvermelding: Wei, S., Hou, M., Yang, S. et al. Semantic segmentation of Buddha facial point clouds through knowledge-guided region growing. npj Herit. Sci. 14, 109 (2026). https://doi.org/10.1038/s40494-026-02377-y
Trefwoorden: 3D-scanning van Boeddhabeelden, digitalisering van cultureel erfgoed, segmentatie van puntenwolken, gezichtsproporties in de kunst, kennis-gestuurde algoritmen