Clear Sky Science · nl
Hoge-resolutie 3D-reconstructie van cultureel erfgoed via superresolutie en progressieve Gaussian splatting
Waarom scherpere digitale relieken ertoe doen
Musea en archeologen wereldwijd haasten zich om getrouwe 3D-kopieën te maken van kwetsbare artefacten, van porseleinen vazen tot tempelpoorten. Deze digitale vervangers stellen ons in staat om cultureel erfgoed te bestuderen, te delen en te beschermen zonder de originelen aan te raken. In de praktijk zijn foto’s van erfgoedobjecten echter vaak donker, wazig of vanuit ongunstige hoeken genomen, waardoor hedendaagse 3D-reconstructiemethoden vervormde of onvolledige modellen kunnen opleveren. Dit artikel introduceert een nieuwe aanpak die dit probleem rechtstreeks aanpakt, door zowel de invoerfoto’s te verbeteren als het 3D-modelleringsproces te stabiliseren.
Wanneer slechte foto’s 3D-modellen breken
Huidige 3D-opnamestrata volgen doorgaans een eenvoudig idee: neem vele foto’s, schat waar elke camera stond, leid de vorm van het object af en render tenslotte een 3D-model. In de praktijk bieden erfgoedsites zelden studiokwaliteit. Weinig licht, versleten of onregelmatige oppervlakken, reflecties van vitrines en beperkingen in camera‑plaatsing degraderen de beelden. De auteurs tonen hoe deze gebreken door de hele pijplijn doorwerken. Wazige of lage-resolutie foto’s bemoeilijken het vinden van overeenkomstige kenmerken tussen beelden, wat leidt tot fouten in cameraposities en onbetrouwbare diepte‑schattingen. Wanneer deze onbetrouwbare metingen worden gevoed aan moderne "Gaussian splatting" renderers — systemen die scènes opbouwen uit duizenden kleine gekleurde blobs — kan dat resulteren in instabiele optimalisatie, redundante blobs en zichtbaar vervormde geometrie.
Foto’s verscherpen met slimmere beeldverbetering
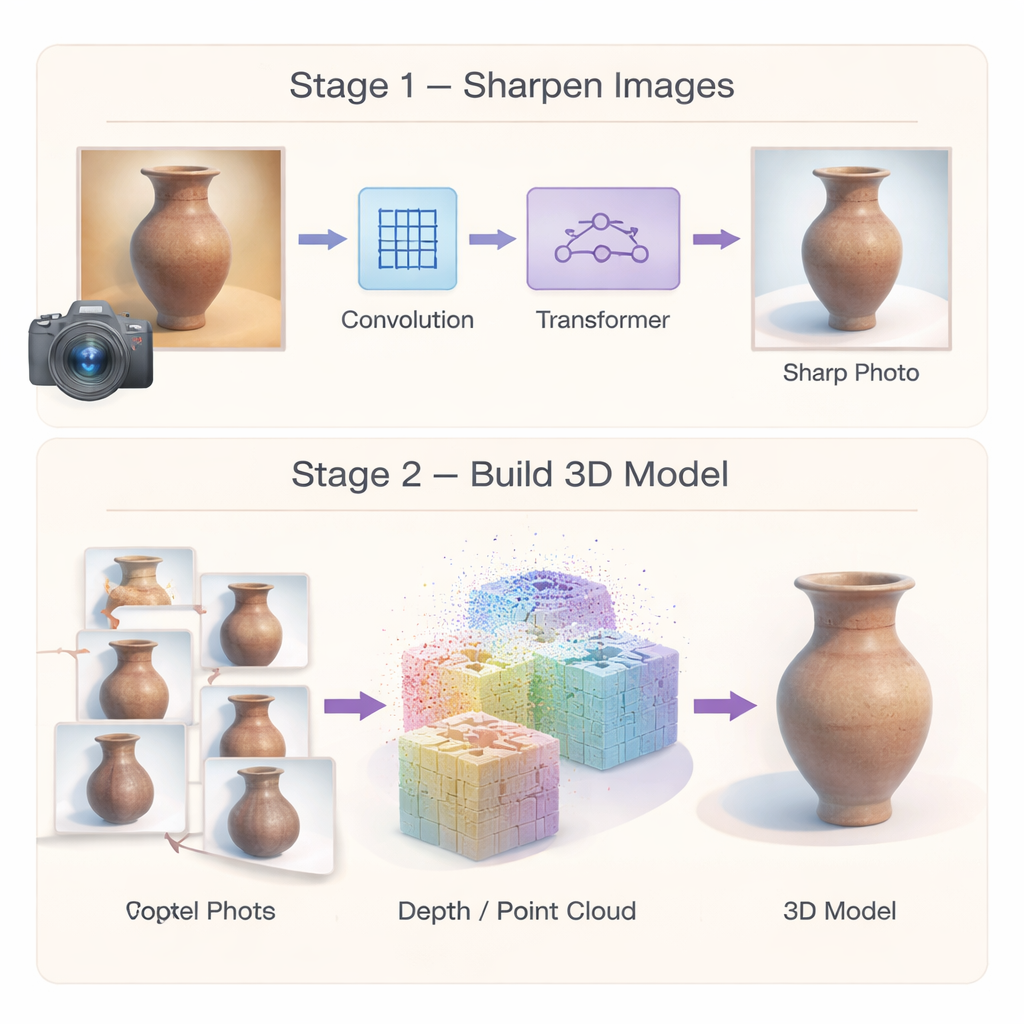
Om fouten bij de bron te stoppen bouwen de auteurs eerst een gespecialiseerd beeld-superresolutie netwerk dat foto’s van laagstaande kwaliteit omzet in scherpere, meer gedetailleerde beelden. In plaats van te vertrouwen op één type verwerking combineert het netwerk twee sterktes. Een multi-schaals convolutiemodule richt zich op lokale details — zoals barstjes, penseelstreken of gesneden lijnen — door het beeld gelijktijdig op meerdere buurtgroottes te bekijken. Een efficiënte Transformer-module pikt vervolgens bredere patronen op, zoals herhalende motieven of lange krommen die over een object lopen. Een derde component versterkt selectief echt vergelijkbare regio’s in het beeld terwijl ruis wordt onderdrukt, zodat zwakke texturen worden opgehelderd in plaats van uitgesmeerd. Samen leveren deze elementen hoge-resolutie beelden op die zowel fijne versiering als de algemene structuur behouden, waardoor de volgende 3D-stadia een veel betere uitgangspositie krijgen.
Steviger 3D-vormen bouwen uit veel gezichten
Verbeterde beelden alleen zijn niet genoeg; de 3D-reconstructie zelf moet ook robuust zijn. Het tweede deel van het raamwerk heroverweegt hoe het 3D-model wordt geïnitialiseerd en geoptimaliseerd. In plaats van te vertrouwen op een spaarzame set overeenkomende punten gebruiken de auteurs een "dichte" matchmethode die vanaf het begin rijke puntenwolken en betrouwbaardere cameraposes produceert. Deze dichte punten fungeren als een sterk geometrisch skelet voor de scène. Daarboven introduceren ze een hybride representatie: de ruimte rond het artefact wordt verdeeld in grove 3D-cellen, en een gedeelde decoder voorspelt de gedetailleerde kleur en vorm van vele kleine blobs binnen elke cel. Omdat parameters grotendeels gedeeld en niet gedupliceerd worden, vermindert de methode geheugenverbruik en bevordert ze gladde, coherente oppervlakken, waardoor het eindmodel minder gevoelig is voor willekeurige bulten en gaten.
Train in zachte stappen in plaats van alles in één keer
De auteurs veranderen ook hoe het systeem getraind wordt. In plaats van het model vanaf het begin te dwingen zowel uiterlijk als geometrie te matchen — een recept om vast te lopen in slechte oplossingen — hanteren ze een driedelige strategie. Eerst leert het systeem alleen de kleuren van de invoerfoto’s te reproduceren, waarmee globale visuele consistentie wordt verzekerd. Vervolgens voegt het geleidelijk diepte-informatie toe, afgeleid van de dichte puntenwolken, die het model naar plausibele oppervlakken begeleidt. In de laatste fase verfijnt het kleine‑schaal details door consistentie af te dwingen over overlappende beeldpatches uit verschillende aanzichten. Getest op een nieuwe Cultural‑Relics dataset van porselein, meubelen, handwerken en textielen, evenals op een standaard benchmark van complexe buitenscènes, verbetert deze gefaseerde aanpak niet alleen de visuele kwaliteit maar verkort ook de trainingstijd en het geheugenverbruik vergeleken met toonaangevende alternatieven.
Wat dit betekent voor het bewaren van het verleden
Voor niet‑specialisten is de kernboodschap eenvoudig: dit raamwerk helpt om onvolmaakte museum- of veldfoto’s om te zetten in schonere, nauwkeurigere 3D-replica’s van cultureel erfgoed, zonder fysiek contact. Door laagwaardige beelden te verscherpen, te beginnen vanaf een steviger geometrisch geraamte en het 3D-model in zorgvuldig gecontroleerde fasen te trainen, produceert de methode digitale artefacten die zowel fijne versiering als de algemene vorm beter vastleggen terwijl minder rekenmiddelen worden gebruikt. In praktische zin maakt dit het makkelijker voor musea, conservatoren en onderzoekers om betrouwbare virtuele collecties te bouwen van gewone fotosessies, waardoor delicate objecten beter beschermd en breed gedeeld kunnen worden met wetenschappers en het publiek.
Bronvermelding: Jia, Q., He, J. High-fidelity 3D reconstruction of cultural heritage via super-resolution and progressive Gaussian splatting. npj Herit. Sci. 14, 84 (2026). https://doi.org/10.1038/s40494-026-02355-4
Trefwoorden: digitalisering van cultureel erfgoed, 3D-reconstructie, beeldsuperresolutie, Gaussian splatting, digitale bewaring