Clear Sky Science · nl
Geo-TCAM: een Thangka-onderschriftmethode die topicmodellering integreert met geometrie-gestuurde ruimtelijke aandacht
Oude kunst ontmoet slimme technologie
Thangka-schilderingen – de felgekleurde rollen die in veel Tibetaanse tempels te zien zijn – zitten vol kleine details en lagen religieuze betekenis. Voor museumbezoekers of online kijkers zonder gespecialiseerde kennis is veel van die symboliek moeilijk te doorgronden. Deze studie introduceert Geo‑TCAM, een systeem voor kunstmatige intelligentie (AI) dat automatisch rijke, nauwkeurige beschrijvingen van Thangka-afbeeldingen genereert, en zo mensen wereldwijd helpt dit unieke culturele erfgoed beter te begrijpen en te behouden.
Waarom Thangka‑afbeeldingen moeilijk zijn voor computers
In tegenstelling tot alledaagse foto’s zijn Thangka-werken opzettelijk dicht en symbolisch. Een enkele schildering kan een centrale godheid bevatten, tientallen kleinere figuren, patroonranden en specifieke handgebaren, objecten, kleuren en houdingen die elk religieuze betekenis dragen. Standaard beeldonderschriftprogramma’s werken vaak goed bij eenvoudige scènes zoals “een hond op een strand”, maar ze hebben hier moeite: ze kunnen de hoofdbuddha noemen maar missen of hij een schaal of een zwaard vasthoudt, zijn houding verkeerd lezen, of hem verwarren met een andere, gelijkende godheid. Zulke fouten zijn niet triviaal – ze kunnen het verhaal en de doctrine die de schildering bedoelt te communiceren omkeren, en daarmee de educatieve en culturele waarde ondermijnen.
Een nieuw ontwerp voor het beschrijven van heilige beelden
Geo‑TCAM pakt deze problemen aan door drie ideeën te combineren: visuele kenmerken op meerdere niveaus, themakennis over Thangka‑kunst, en geometrie‑gestuurde aandacht voor sleutelgebieden zoals gezichten. Ten eerste gebruikt het een diep netwerk (ResNet50) om elk beeld gelijktijdig op meerdere niveaus te bekijken: middenlagen vangen randen, texturen en eenvoudige vormen, terwijl diepere lagen de algehele compositie samenvatten. Door deze niveaus te combineren kan het model zowel fijne details zoals versieringen als de brede indeling van achtergrond en figuren opmerken, wat een rijker visueel begrip oplevert dan eerdere systemen die op één laag focusten. 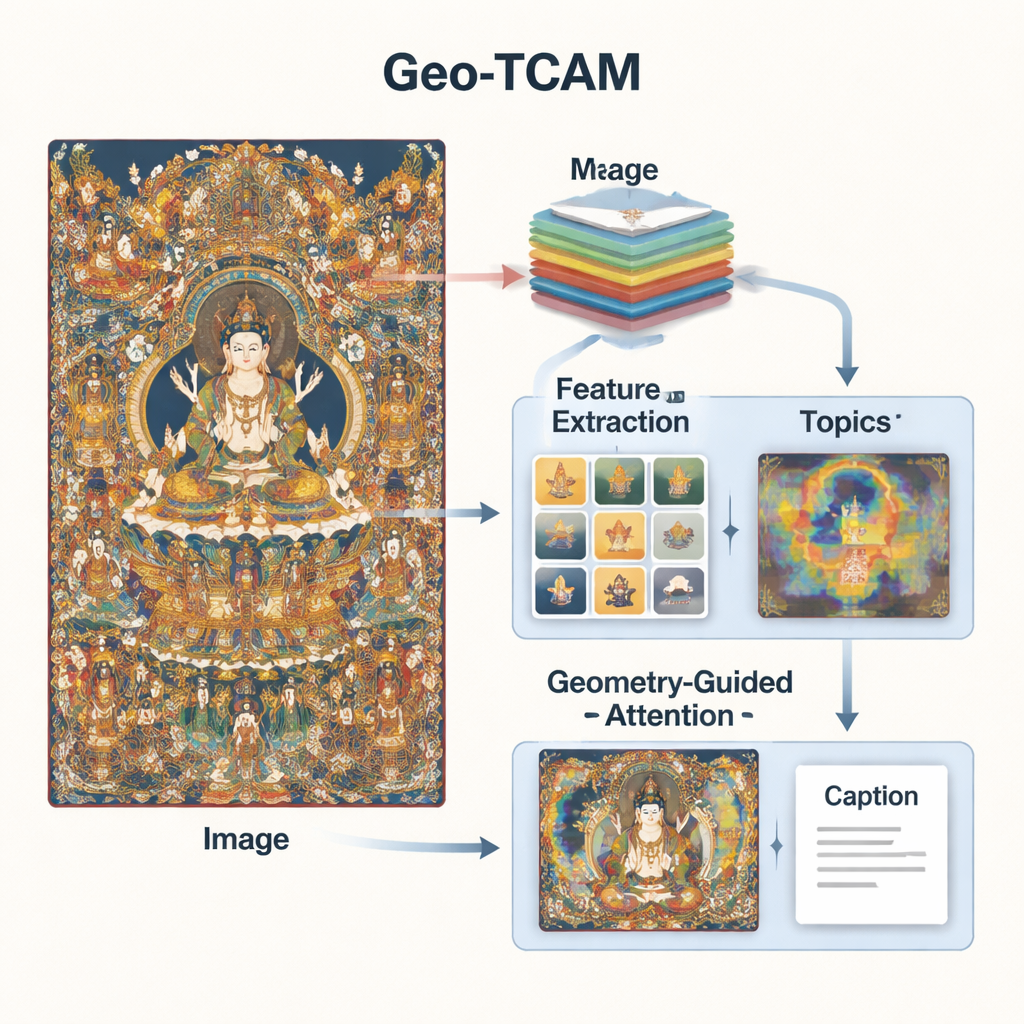
Het model Thangka-“onderwerpen” leren
Visie alleen is niet genoeg; het systeem heeft ook enig begrip van Thangka‑taal en thema’s nodig. Daartoe trainden de onderzoekers een topicmodel op duizenden door experts geschreven Thangka‑beschrijvingen. Dit model groepeert woorden in een aantal veelvoorkomende thema’s – bijvoorbeeld gerelateerd aan Boeddha’s, Bodhisattva’s, lotustabureaus, rituele attributen of beschermende godheden. Voor elk nieuw beeld schat Geo‑TCAM in welke thema’s het meest relevant zijn en mengt die informatie met de visuele kenmerken. Een aandachtmechanisme markeert vervolgens de afbeeldingsregio’s die het best overeenkomen met de waarschijnlijke thema’s. In feite stuurt voorkennis over welke objecten en symbolen vaak samen voorkomen de AI naar meer betekenisvolle, cultureel bewuste beschrijvingen.
De AI “laten kijken” waar het het meest telt
De derde innovatie is een geometrie‑gestuurde gezichts‑ruimtelijke aandachtmodule (GFSA). Thangka‑composities plaatsen het gezicht van de hoofdfiguur doorgaans in globaal voorspelbare delen van het schilderij. Geo‑TCAM gebruikt eenvoudige randdetectietools om dit gebied en de omliggende handen en houding te lokaliseren, en past vervolgens een speciaal aandachtmechanisme toe dat de invloed van deze pixels versterkt bij het vormen van een onderschrift. Deze “eerst lokaliseren, later sturen”-strategie helpt vroege misidentificatie van de centrale godheid te voorkomen, wat anders zou kunnen uitmonden in lange ketens van tekstuele fouten over gebaren, attributen en status. Visuele heatmaps tonen dat met GFSA het model zich helderder concentreert op het gezicht van de hoofdfiguur en sleutelobjecten, terwijl het belangrijke achtergrondmotieven in de gaten blijft houden. 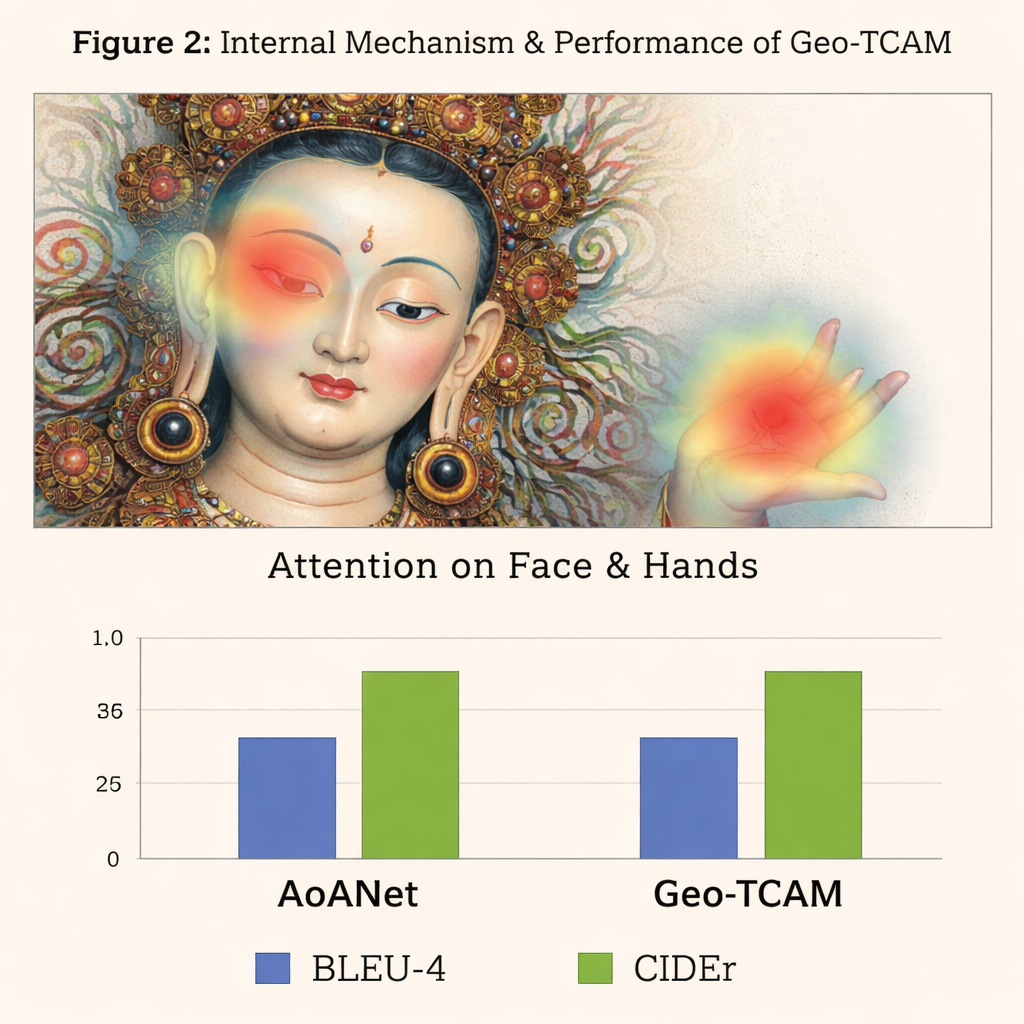
Hoe goed werkt Geo‑TCAM?
Om hun benadering te testen bouwden de auteurs een gespecialiseerde D‑Thangka‑dataset van bijna 4.000 zorgvuldig geannoteerde afbeeldingen, elk met gedetailleerde expertaantekeningen. Op deze dataset presteerde Geo‑TCAM duidelijk beter dan meerdere sterke onderschrijfsystemen, waaronder het populaire AoANet en grote visie‑taalmodellen. Afhankelijk van de maatstaf verbeterden de scores met maximaal ongeveer 120% ten opzichte van de basislijn, en menselijke beoordelaars gaven overweldigend de voorkeur aan zijn bijschriften wat betreft nauwkeurigheid, vloeiendheid en rijkdom aan details. Belangrijk is dat toen hetzelfde model werd geëvalueerd op een standaard verzameling alledaagse foto’s (de COCO‑dataset), het competitief bleef met toonaangevende methoden, wat aantoont dat het ontwerp krachtig maar toch algemeen inzetbaar is.
Wat dit betekent voor erfgoed en verder
Voor niet‑experts is de belangrijkste conclusie dat Geo‑TCAM visueel complexe Thangka‑schilderingen kan omzetten in duidelijke, informatieve verhalingen die benadrukken wie is afgebeeld, wat ze doen en waarom die details ertoe doen. Door gelaagde visuele analyse, geleerde thema’s uit expertteksten en speciale aandacht voor gezichten en gebaren te combineren, brengt het systeem zijn bijschriften veel meer in lijn met hoe menselijke specialisten deze kunstwerken lezen. Op de lange termijn zouden dergelijke hulpmiddelen digitale archieven, museumgidsen en educatieve platforms kunnen ondersteunen, waardoor esoterische religieuze kunst toegankelijker wordt en conservatoren en wetenschappers geholpen worden bij het documenteren en beschermen van kwetsbare culturele schatten.
Bronvermelding: Zhong, P., Hu, W., Zhao, Y. et al. Geo-TCAM: a Thangka captioning method integrating topic modeling with geometry-guided spatial attention. npj Herit. Sci. 14, 87 (2026). https://doi.org/10.1038/s40494-026-02343-8
Trefwoorden: Thangka-beeldonderschrift, AI voor cultureel erfgoed, visuele aandacht, topicmodellering, kunstbehoud