Clear Sky Science · nl
Constructie van het deelwoordgetagde corpus van de Vierentwintig Historische Werken (oud-modern)
Waarom oude kronieken ertoe doen in het tijdperk van AI
Al meer dan twee millennia legden Chinese historici oorlogen, hoven, hongersnoden en het dagelijks leven vast in de omvangrijke reeks die bekendstaat als de Vierentwintig Historische Werken. Tegenwoordig worden deze klassiekers niet alleen door geleerden herontdekt, maar ook door computers. Deze studie beschrijft hoe onderzoekers deze oude kronieken en hun moderne Chinese vertalingen omgezet hebben in een zorgvuldig gelabelde taaldatabase. Die bron kan kunstmatige intelligentie helpen historische teksten nauwkeuriger te lezen, te vertalen en te analyseren — en het verre verleden veel toegankelijker maken voor het grote publiek.
Van stoffige banden naar digitale tekst
Het project begint met een eenvoudige maar ontmoedigende taak: miljoenen gedrukte tekens omzetten naar schone, nauwkeurige digitale tekst. Het team gebruikte twee bronnen — een gezaghebbende moderne editie van de Vierentwintig Historische Werken en een grote online collectie — om een optische tekenherkenningssysteem te voeden. Vervolgens verwijderden ze zorgvuldig foutieve passages, corrigeerden verkeerd gelezen tekens en haalden ruis weg zoals paginakoppen en voetteksten. Het resultaat was een parallelle set bestanden, één in oud-Chinees en één in modern Chinees, die trouw waren aan de oorspronkelijke boeken maar gereed voor computationele analyse. 
Oud- en modern-zinnen aan elkaar koppelen
Aangezien het doel was te vergelijken hoe taal door de tijd is veranderd, was het essentieel om de oude en nieuwe versies zin voor zin op elkaar af te stemmen. De onderzoekers gebruikten gespecialiseerde alignatiesoftware om eerst alinea’s te matchen en die vervolgens in overeenkomstige zinnen op te splitsen. Geautomatiseerde hulpmiddelen deden het zware werk, maar menselijke experts moesten elk voorgesteld paar controleren, omdat de grammatica van het oud-Chinees sterk kan verschillen van het moderne Chinees. Waar de software struikelde — een gedachte op de verkeerde plek splitsen of een teken verkeerd lezen — controleerden annotatoren de originele gescande pagina’s en corrigeerden ze de digitale tekst zodat elke oude zin netjes aansloot op zijn moderne tegenhanger.
Computers leren grammatica te zien
Meer dan eenvoudige transcriptie is de kern van het project grammaticale labeling. Elk woord in zowel de oude als de moderne teksten werd voorzien van een deelwoordtag, die aangeeft of het bijvoorbeeld een zelfstandig naamwoord, werkwoord of tijdswoord is. Omdat er geen eenduidige standaard bestaat voor oud-Chinees, verankerde het team hun systeem in de moderne nationale richtlijnen en paste die vervolgens aan op ouder gebruik. Ze ontwikkelden een schema met 22 tags dat een speciale label bevat voor uniek oude werkwoordstoepassingen zoals “doen leven” of “sterven voor het land.” Een aangepast neuraal netwerk — gebouwd op een taalmodeel voor oude teksten en lagen voor sequentie-labeling — leverde initiële tags, die vervolgens werden gecontroleerd en gecorrigeerd door een groot team goed opgeleide promovendi. Strenge overeenstemmingstests tussen annotatoren toonden zeer hoge consistentie, wat bevestigt dat het uiteindelijke getagde corpus zowel omvangrijk als betrouwbaar is.
Wat de nieuwe lens onthult
Met het getagde corpus op zijn plaats onderzochten de auteurs enkele patronen die het zichtbaar maakt. In het oud-Chinees domineren eentekenswoorden, wat een berucht compact schrijftype weerspiegelt, terwijl het modern Chinees de voorkeur geeft aan twee-tekenwoorden. De meest voorkomende oude elementen zijn kleine grammaticale partikels zoals “之” en “以”, terwijl werkwoorden en gewone zelfstandige naamwoorden samen ongeveer de helft van alle woorden in beide tijdperken vormen. De gegevens laten ook zien welke woorden vaak samen voorkomen — bijvoorbeeld structuren die ambtenaren, legers of diplomatieke missies beschrijven. Door tags te vergelijken over de oud‑modern-paren traceerde het team hoe functies in de loop van de tijd verschoof: sommige oude voorzetsels en bijwoorden komen nu overeen met volledige moderne werkwoorden, en sommige werkwoorden zijn verhard tot vaste titels of juridische termen. In één casestudy werden alle plaatsnamen geselecteerd en in kaart gebracht waar ze zich concentreren in verschillende dynastieën, wat onthult hoe politieke en economische centra verschoof van het noordwesten naar de benedenloop van de Yangtze en daarbuiten. 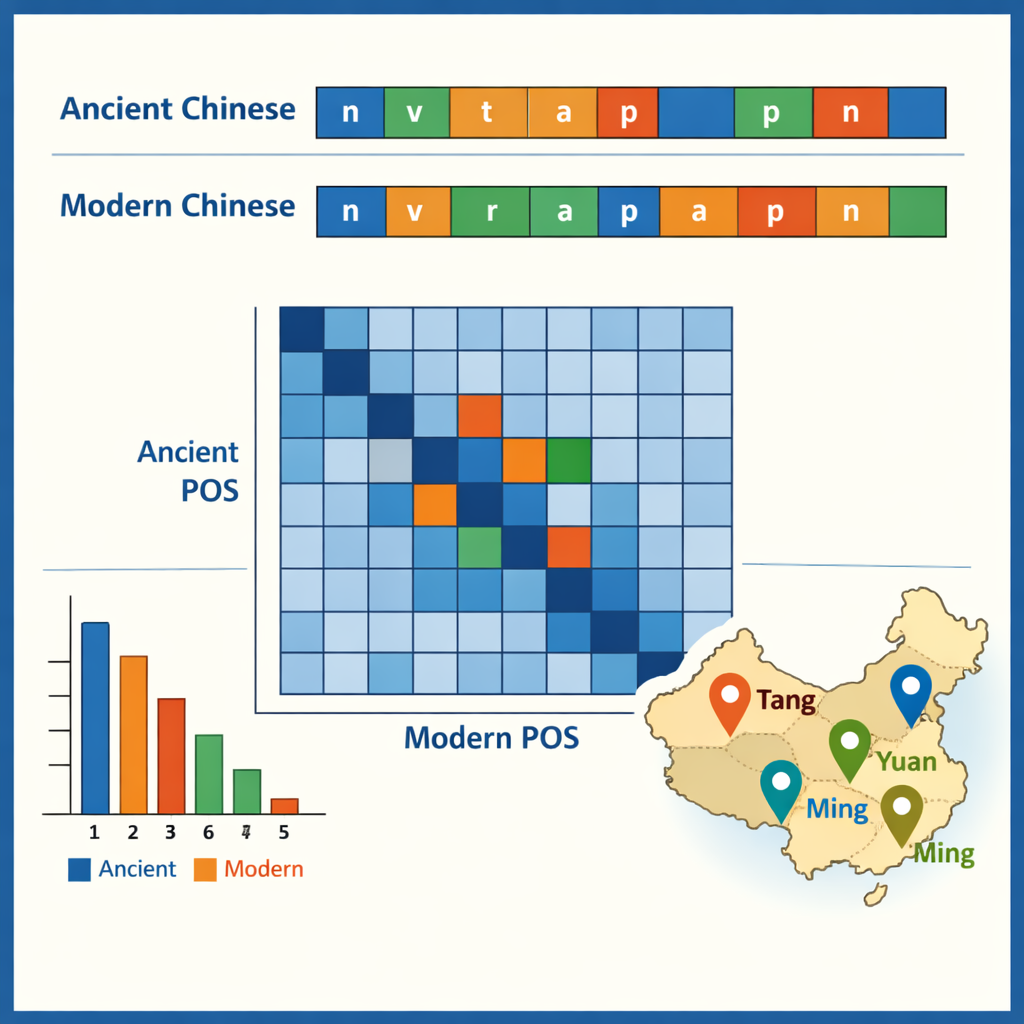
Het verleden naar de digitale toekomst brengen
Eenvoudig gezegd zet dit project een torenmuur van klassieke proza om in gestructureerde data die zowel mensen als machines kunnen doorzoeken. Voor historici en taalkundigen biedt het een krachtig instrument om te volgen hoe woorden, grammatica en zelfs staatsgrenzen zich over eeuwen ontwikkelden. Voor AI‑ontwikkelaars levert het hoogwaardig trainingsmateriaal om taalmodellen te bouwen die klassiek Chinees daadwerkelijk aankunnen in plaats van het als een warboel tekens te behandelen. En voor studenten en algemene lezers verlaagt de zin-voor-zin-koppeling van oud en modern de drempel om de klassiekers te lezen. Door de Vierentwintig Historische Werken zorgvuldig te labelen en uit te lijnen, hebben de auteurs een brug geslagen tussen de handgeschreven rollen van het verleden en de intelligente systemen van heden en toekomst.
Bronvermelding: Ye, W., Xu, Q., Zhao, X. et al. Construction of the twenty-four histories ancient-modern part-of-speech tagged corpus. npj Herit. Sci. 14, 97 (2026). https://doi.org/10.1038/s40494-026-02309-w
Trefwoorden: oud-Chinees corpus, deelwoord-tagging, digitale geesteswetenschappen, parallelle teksten, historische taalverandering