Clear Sky Science · ja
オープンソースの生成AIと機械学習による主題分析:帰納的な質的コードブック作成の新手法
日常的な問いにとってこれはなぜ重要か
人々がアンケートに回答したり面接に答えたりするとき、職場や学校、健康、地域生活についての豊かな物語が残されます。数十件の回答を読むのは簡単ですが、何千件もの回答を整理して意味を見出すのは容易ではありません。本稿は、研究者が大量の自由記述コメントをふるい分けて主要な考えを抽出するのに、オープンソースの人工知能をどのように活用できるかを示します。重要なのは解釈の主導権を人間に残すことであり、目的は通常はビッグデータ統計に用いられるような規模であっても、慎重で微妙な質的研究を可能にすることです。
何千ものコメントを読むための賢い方法
著者らは、研究者がテキストを読んで研究課題に答える反復的なパターン(「テーマ」)を探す、社会科学で広く用いられる主題分析に着目しています。従来は各コメントを手作業で丁寧にコード付けし、テーマとサブテーマの構造化された一覧であるコードブックを作ることが一般的です。このプロセスは数十件のインタビューでは有効ですが、何万件もの自由回答があると手に負えなくなります。本稿は問いかけます:無料で入手できる生成系テキストモデルやその他のオープンソース工具は、初期の反復的な作業を人間の判断を置き換えずに支援できるのか?
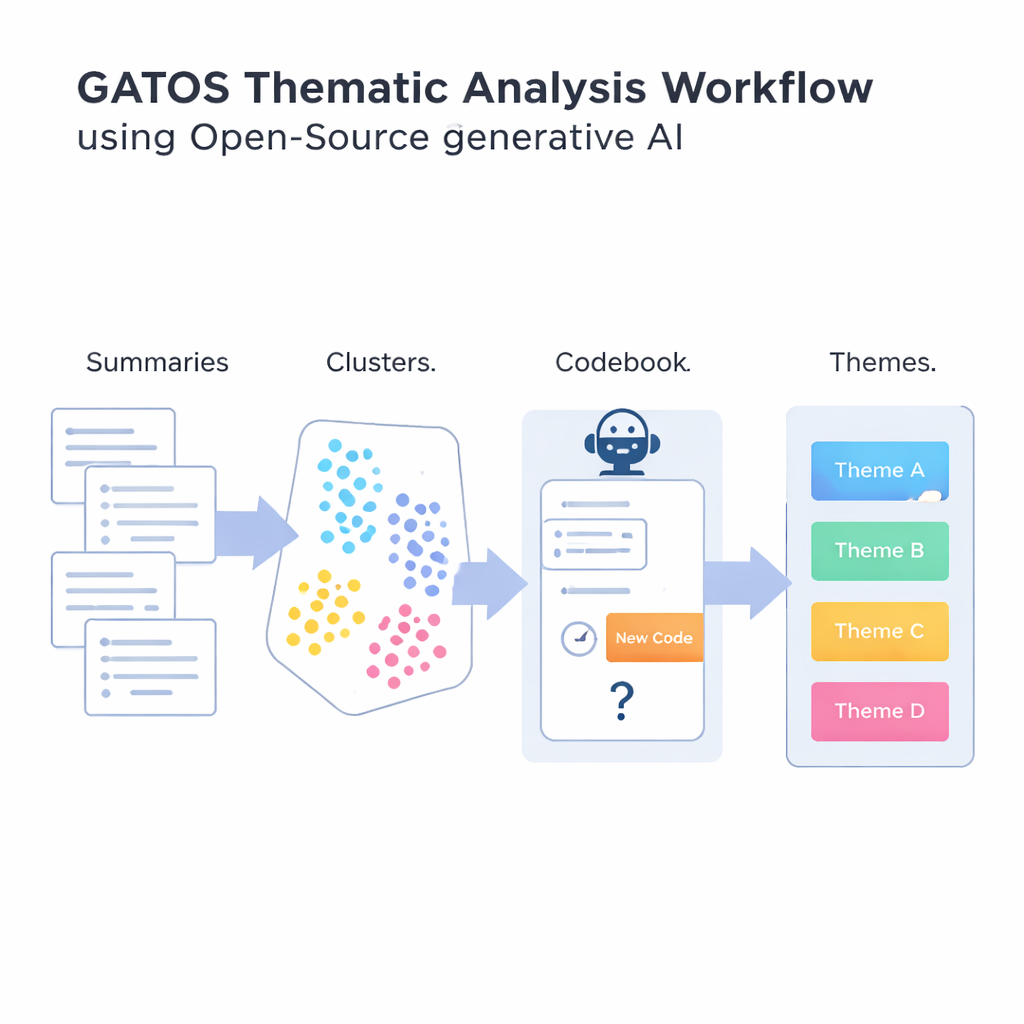
GATOSワークフローの紹介
その問いに答えるために、著者らはGenerative AI-enabled Theme Organization and Structuring(GATOS)ワークフローを提示します。このワークフローはいくつかのステップを連鎖させます。まず、オープンソースの言語モデルが個々の回答を読み、それぞれの発言の要点を短く焦点を絞った要約として書き出します。次に別のツールがこれらの要約を数値表現に変換し、コンピュータが類似した考えを比較・グループ化できるようにします。こうして得られた要約は、ワークライフバランスへの懸念や不明瞭なコミュニケーションへの不満といった共有テーマを反映している可能性が高いクラスターにまとめられます。
AIに提案させるが、アイデアを氾濫させない工夫
最も新しいステップは、システムが草案のコードブックを作り始める段階です。関連する要約の各クラスターに対して、別の生成モデルがそのクラスター内のアイデアとすでにあるコードを参照します。そして、本当に新しいコードが必要か、既存のコードで十分かを検討します。例えば「信頼できるビデオ会議ツール」といった具体的な懸念が新たに現れれば、短いラベルと定義を提案して追加します。そうでなければ既存のコードを再利用する判断をします。最後に、関連するコードをより広いテーマにまとめ、未整理のコメントから体系化された洞察への構造化マップを作成します。全体を通じて、ほぼ重複するコードの氾濫を避けつつ、人々の経験にある微妙な違いを捉えることに重点が置かれています。
現実的な模擬データで手法を検証
実世界の研究には既知の「解答キー」が付いていることは稀なので、チームはGATOSを隠れたテーマが事前に知られている合成(コンピュータ生成)データで検証しました。彼らは大規模で実感のある3つのデータセットを作成しました:チームワークに関する同僚からのフィードバック、職場の倫理文化に関する見解、COVID-19後のオフィス復帰に関する意見です。各データセットについて最初に8つのテーマといくつかのサブテーマを定義し、労働組合員、管理職、学生など異なるペルソナからの数百件のリアルな回答を言語モデルに書かせました。GATOSをこれらのデータセットに適用した後、人間の査読者がAI生成のテーマを元の隠れたサブテーマと照合し、どれほど一致しているかを評価しました。
どの程度うまくいったか、そしてトレードオフは何か
3つのテストケース全体で、ワークフローは元のサブテーマの多くをかなり正確に復元しました:大多数に少なくとも一つの強い対応があり、良い対応が見つからなかったのはごく一部でした。重要なのは、システムがより多くのデータを検討するにつれて新しいコードの提案が減り、無限のバリエーションを生み出すのではなく既存のアイデアを再利用する傾向が示された点です。著者らは、この種のオープンソースでローカルに実行可能な構成がプライバシー上の懸念を和らげ、異なる研究チームが互いの研究を再現しやすくすると主張します。同時に、合成データは多くの実際の状況より単純であり、ワークフローが重複するコードを作る可能性が残ること、そして最終的なコードブックを精緻化・解釈・評価するために人間の研究者が依然として必要であることを強調しています。
非専門家にとっての意味
学術界外の読者への要点は、オープンソースAIが社会科学者や他の研究者がはるかに多くの人々の声に耳を傾けるのを助けられるということです。ただしそれは言葉を粗雑な数値に置き換えるのではありません。GATOSワークフローは人間の分析者を置き換えるのではなく、ごく高速で非常に整理されたアシスタントとして働き、パターンや草案ラベルを提案し、そのパターンが本当に何を意味するかを判断するのは人間に任せます。さらに研究が実世界データでもこれらの結果を裏付ければ、GATOSのようなツールは職場方針、教育プログラム、公共の意思決定を、多肢選択式のアンケート欄だけでなく、人々が実際に語る豊かな内容に基づいて行いやすくする可能性があります。
引用: Katz, A., Fleming, G.C. & Main, J.B. Thematic analysis with open-source generative AI and machine learning: a new method for inductive qualitative codebook development. Humanit Soc Sci Commun 13, 209 (2026). https://doi.org/10.1057/s41599-026-06508-5
キーワード: 質的データ分析, 主題分析, 生成AI, オープンソース言語モデル, 社会科学の研究手法