Clear Sky Science · ja
依存症ケアの臨床記録におけるスティグマ言語の検出:大規模言語モデルの活用
医療記録の言葉がなぜ重要か
患者が自分の医療記録にオンラインでアクセスできるようになると、臨床医が用いる言葉は病院のコンピュータの中だけに隠れているわけではなく、記載されている本人の目にも触れるようになります。依存症を抱える患者にとって、「drug abuser(薬物乱用者)」のような一語は、静かに恥を強化し、信頼を損ない、受ける医療にも影響を及ぼすことがあります。本研究は時宜を得た疑問を投げかけます:現代の人工知能は、臨床メモに含まれるスティグマ的な表現を患者に害が及ぶ前に病院が検出・軽減するのに役立つのか?

日常のメモに隠れた有害なレッテル
医療におけるスティグマは、目線や口調だけで表れるわけではなく、書かれた記録にも組み込まれています。電子カルテには診療所や病院をまたいで患者に付随する何百万ものノートが含まれます。「alcohol abuse(アルコール乱用)」や「drug-seeking behavior(薬物を求める行為)」といった表現は、救急受診や入院の後でも将来の臨床医の患者に対する見方を形づくる可能性があります。研究者たちは、記述が濃密で利害が大きい集中治療室の、薬物使用に関する患者のノートに着目しました。彼らは「addict(中毒者)」ではなく「person with substance use disorder(物質使用障害のある人)」のような敬意を払った個人優先の表現を奨励する国のガイドラインに基づき、スティグマ的かどうかをラベル付けした大規模なデータセットを作成しました。
行間を読むAIを教える
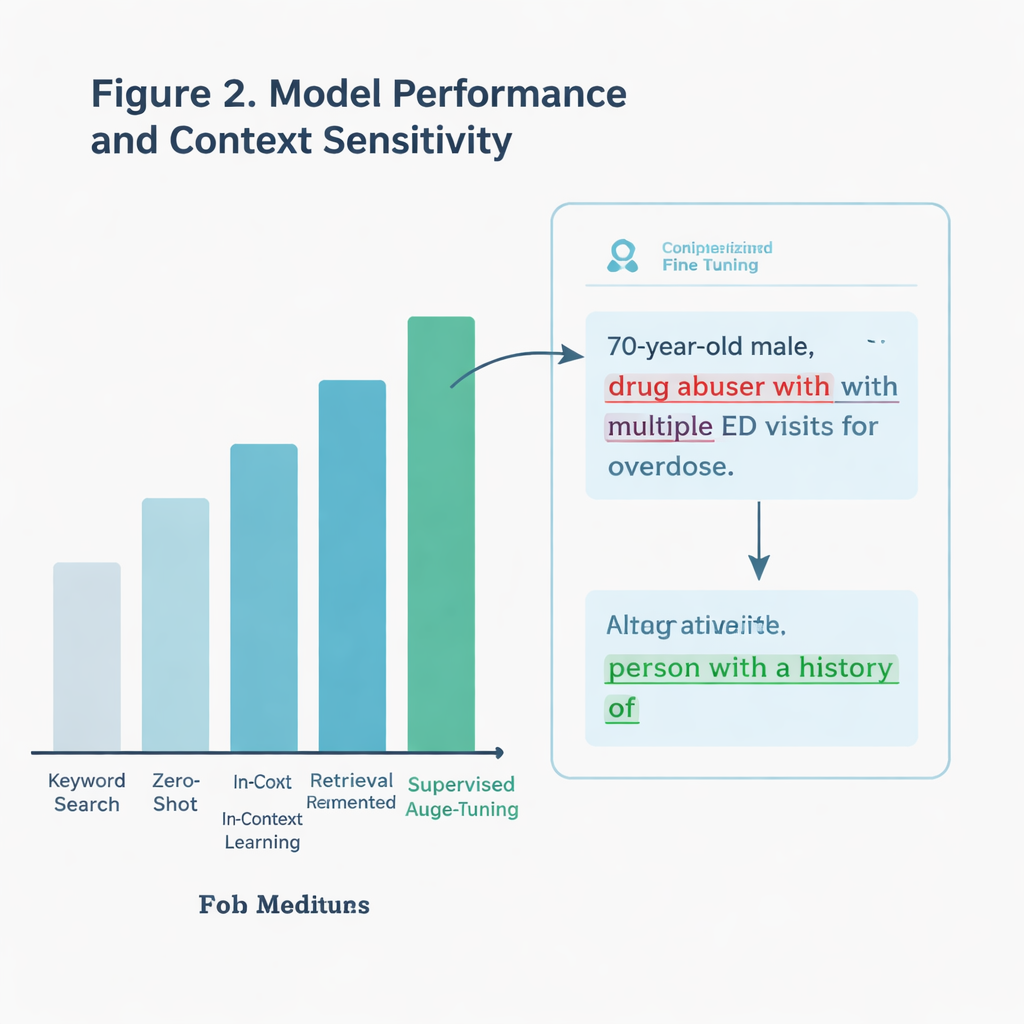
単に不適切な語句をスキャンするだけではなく、研究チームは文脈を理解できるAIシステムを求めました。たとえば、患者が自分を「drunk(酔っている)」と自己申告している引用は、臨床医がそのラベルを付けている場合と同じではありません。著者らは、いずれもテキストを処理・生成するタイプのAIである大規模言語モデルに基づく複数のアプローチを比較しました。基本的な方法はガイドラインから抽出した特定のキーワードのみを探すものでした。より高度な方法は、追加の例を与えないままAIに判断させるもの、コミュニケーションガイドラインからの助言を与えるもの、あるいは何千ものラベル付けされたICUノートで特別に訓練(ファインチューニング)したものなどがありました。
実際の現場で最も効果があったもの
ファインチューニングされたモデルが明確な勝者でした。11,000件を超える保持用テストセットで、このモデルは約97パーセントの確率でスティグマ的な言語を正しく識別し、単純なキーワード検索を大きく上回りました。また、潜在的に刺激的な用語を含むが必ずしも有害に使われているわけではないという、扱いの難しいサブセットに対しても優れた耐性を示しました。モデルは、粗雑な検索が見逃すような、判断的な表現と中立的・引用された用法とを区別できました。さらに、別の州にある別の医療システムのノート——ほぼ30万件のICUノート——でシステムを検証した際にも、スティグマ的表現は実際のサンプルでは稀であったにもかかわらず、キーワード方式より優れていました。
臨床医が見落とした新たな問題表現の発見
研究者たちはさらに一歩進み、AIに特定のノートをフラグした理由を説明させました。その説明を依存症専門医がレビューしたところ、モデルが最初の人手ラベリングで見落とされた実際にスティグマ的な表現を数多く指摘していることが判明しました。既存のガイドラインに挙がっていないフレーズも含まれていました。例としては「drug-seeking behavior(薬物取得行動)」のような記述や、「alcoholic cirrhosis(アルコール性肝硬変)」といった、病気ではなく本人を暗に非難するような日常的な言及が挙げられます。これは、適切に設計されたAIツールが現行のベストプラクティスを強制するだけでなく、臨床記述が変化する中で有害な言葉遣いがどのようなものかの理解を広げるのにも役立つ可能性を示唆しています。
研究ツールから現場支援へ
研究はまた実務的な問題にも目を向けました。キーワード検索は非常に高速ですが表面的です。最も精度の高いAIモデルは、強力なグラフィックスプロセッサで数時間の訓練を要しましたが、一度訓練されれば各ノートを数秒でスクリーニングできました——検索エンジンとしては遅いですが、病院システムのバックグラウンドアシスタントとしては許容範囲です。追加の訓練を必要としない、よく作り込まれたプロンプトに依存する別のあまりカスタマイズされていないアプローチも、そこそこの成績を収め、技術リソースが限られるクリニック向けの軽量な選択肢を示唆しました。これらの発見は、臨床医が入力する際にリアルタイムで問題のある表現をフラグし、より敬意を払った代替表現を提案するようなシステムへの道を示しています。
より敬意あるケアへの一歩
一般の読者にとっての主要なポイントは簡潔です:あなたの診療録に書かれた言葉は単なる専門用語ではなく、あなたがどのように扱われるかを形作ります。本研究は、大規模言語モデルが、問題が微妙な場合でも集中治療のノートにおける依存症関連の多くのスティグマ的表現を確実に検出できることを示しています。どのシステムも完璧ではありませんが、そのようなツールは常時稼働する校正者として機能し、臨床医を診断以上の存在として人を認める言語へと促すことができます。長期的には、責める文化から敬意へと移ることが、薬や医療機器と同じくらい治療にとって重要になるかもしれません。
引用: Sethi, R., Caskey, J., Gao, Y. et al. Detecting stigmatizing language in clinical notes with large language models for addiction care. npj Health Syst. 3, 15 (2026). https://doi.org/10.1038/s44401-026-00069-0
キーワード: 依存症へのスティグマ, 臨床記録, 大規模言語モデル, 電子カルテ, 個人優先の言葉遣い