Clear Sky Science · ja
3Dマジックミラー:因果的視点から見た単一画像からの衣服再構築
試着室なしで服を試す
スマートフォンで全身の写真を一枚撮るだけで、瞬時に自分を3Dで表示し、回転させたり視点を変えたり、友人と服を入れ替えたりできると想像してみてください。本論文はその「3Dマジックミラー」を支える技術的核心、つまり普通の2D写真一枚から被写体の衣服の詳細な3Dモデルを作成する問題に取り組んでいます。高価な3Dスキャンや制御されたスタジオ撮影に頼らずに実現することを目指しています。
2D写真を3Dにするのが難しい理由
平面画像を3Dオブジェクトに変換するのは古典的な難題です。既存のシステムは多くの場合、固定のデジタル身体テンプレートを出発点とし、それを画像に合わせて変形させます。腕や脚のような剛体に近い部位ではこれが比較的うまくいきますが、流れるようなドレスや垂れ下がるコート、髪やハンドバッグのように単純で標準的な形に従わないものには適用が難しくなります。もう一つの障害はデータです。ウェブ上にあるファッション写真は何百万枚もありますが、学習に使える精密に計測された3D衣服の大規模コレクションはほとんど存在しません。最後に、単一の写真は重要な情報を隠しています。カメラに近い小さなコートは、遠くにある大きなコートと同じように見えることがあり、照明や布地の柄も学習アルゴリズムを混乱させます。こうした曖昧さが、ニューラルネットワークが正しい3D構造を“推測”するのを困難にします。
因果関係を学ばせて原因と結果を分ける
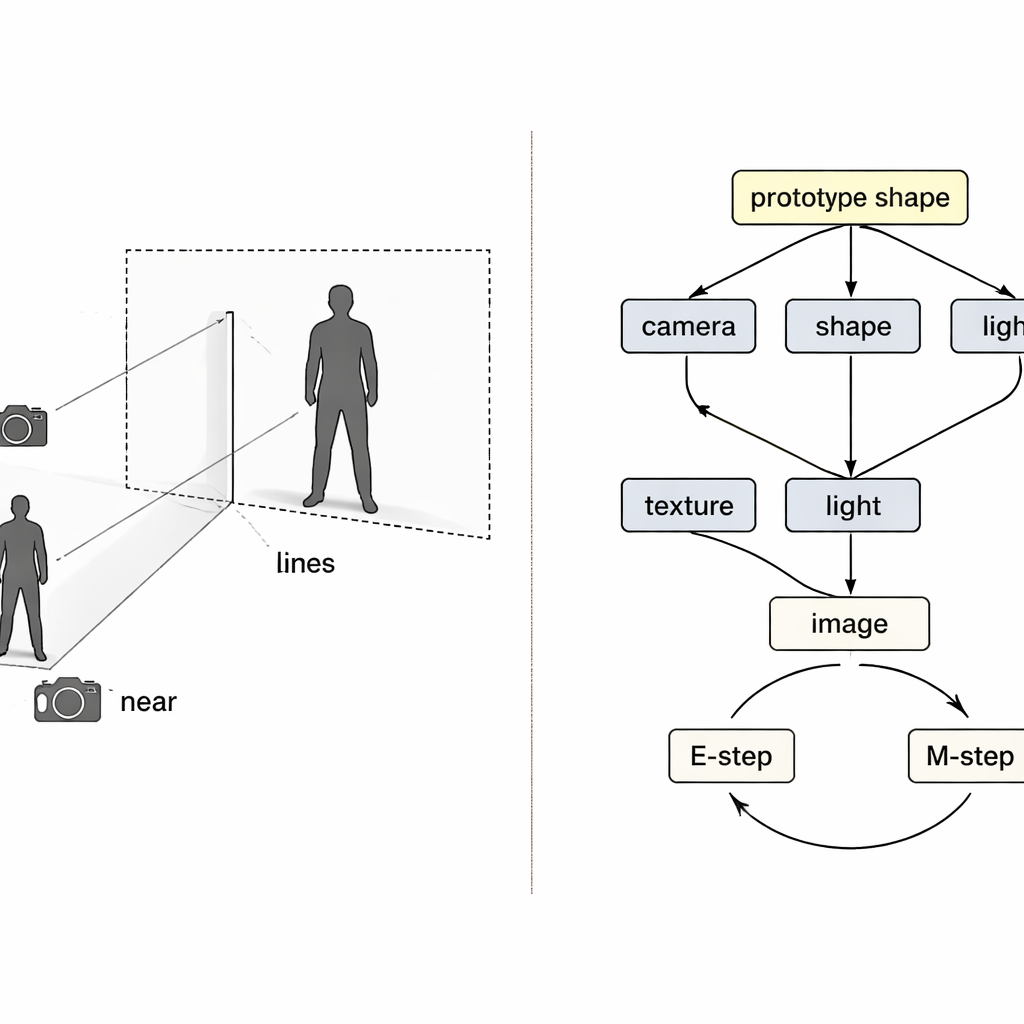
ピクセルから3Dへのブラックボックス的な写像として扱う代わりに、著者らは因果推論—原因と結果の数学—の考えを借りています。最終的な画像を、カメラの配置、衣服の形状、テクスチャ(色や柄)、照明という四つの隠れた原因の結果と見なします。特別な「構造的因果マップ」がこれらの要因がどのように組み合わさって観測画像を生むかを示します。この地図に導かれて、システムは各要因を担当する四つの個別ニューラルエンコーダを使います。物理に触発された3Dレンダラとともに、画像と前景マスクを入力として、色付きの3Dメッシュを出力し、それを再び画像に投影して元の画像と比較するループを形成します。
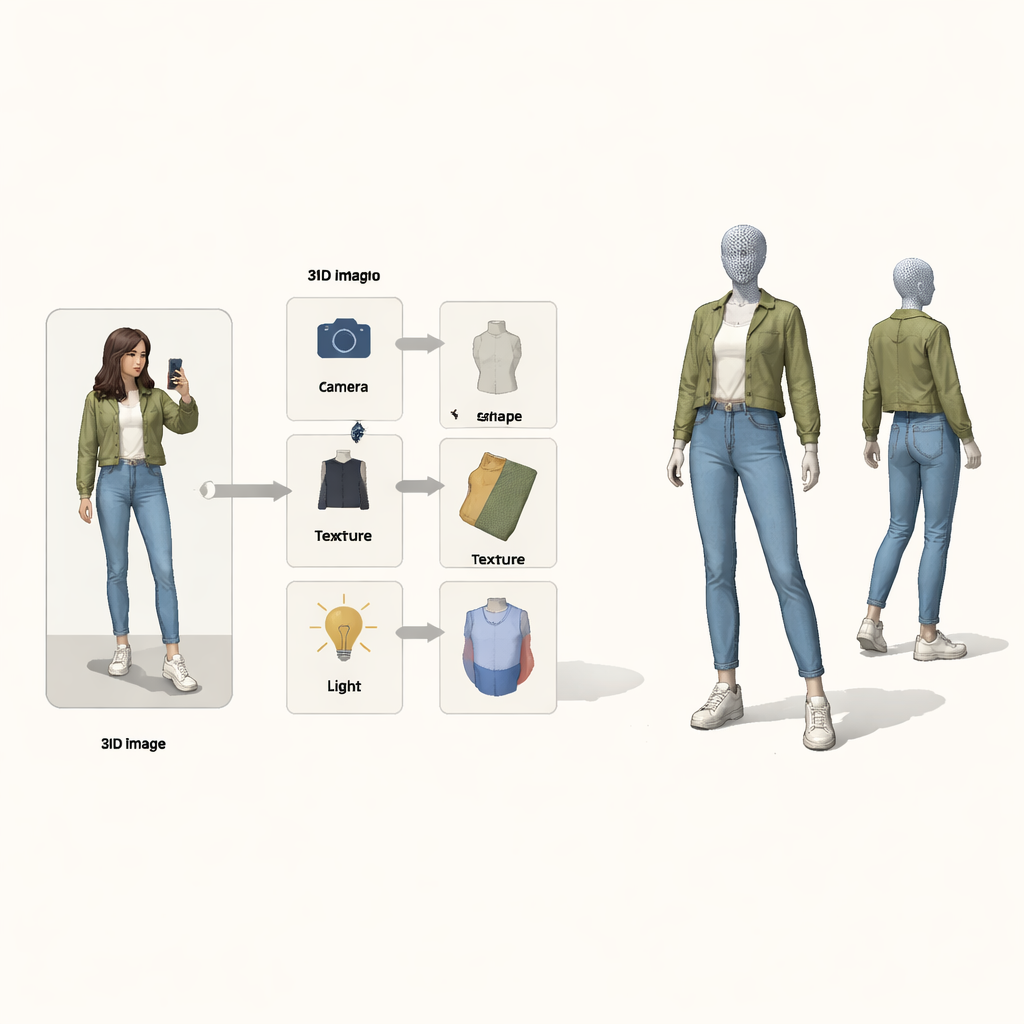
一度に一つずつ直す学習ループ
個別のエンコーダがあっても、学習は誤った方向に進むことがあります。再構築が不完全な場合、どのエンコーダが原因か不明瞭で、通常の学習ではすべてを同時に調整してしまいがちです。著者らはこれを因果関係における典型的な「コライダー」問題とみなし、異なる原因が互いに不適切に補償し合うことを指摘します。その解決策として、学習に二つの期待値最大化ループを織り交ぜます。第一のループでは三つのエンコーダを一時的に固定し、残る一つだけを更新して誤差を明確に帰属させ、その構成要素がより明瞭な役割を学びます。第二のループでは、共有の「原型」3D形状(最初は単純な球体として開始)を徐々に更新して、データ中の平均的な人間や鳥の形に近づけます。個々の例はこの原型からの小さな偏差だけを学び、カメラムジュールが物体の大きさや距離の見かけ上の違いに対するすべての責任を担うことで、サイズと距離の混同に直接取り組みます。
ファッション写真から鳥まで、そしてその先へ
手法を評価するために、研究者たちは通常のストリート写真を含む二つの大規模ファッションデータセットと、標準的な鳥画像コレクションで学習を行います。重要なのは、彼らが使用するのは3Dの正解メッシュではなく2Dの前景マスクだけだという点です。人間の衣服に関して、彼らのシステムは衣服の実際の輪郭の一致で人気のある身体テンプレート法を上回り、髪やハンドバッグといった非剛体要素をより忠実に扱います。鳥では、単一画像からの3D再構築の主要手法と同等かそれ以上の品質に達し、より現実的な新視点を生成します。生成される3Dモデルは柔軟で、人同士で服のテクスチャを入れ替えたり、監視研究で使われる人物再識別システムを強化するための合成学習データを生成したりするなど、遊び心のある応用にも対応します。
日常のデジタル世界にとっての意味
専門家でない人向けの要点は、説得力のある3Dアバターやバーチャルトライオンツールがもはや高価な3Dスキャナや剛直なテンプレートを必要としないということです。カメラ、形状、テクスチャ、光を明示的にモデル化し、共有の原型に紐づけることで、単一の写真を3Dシーンとして「説明」できるシステムが可能になることを著者らは示しました。手法は前方からのみ撮影された人物の背中のような未観測視点ではまだ苦戦しますが、実際に私たちが日常で撮る雑多な画像で動作する実用的な3Dマジックミラーに向けた重要な一歩を示しています。
引用: Zheng, Z., Zhu, J., Ji, W. et al. 3D Magic Mirror: clothing reconstruction from a single image via a causal perspective. npj Artif. Intell. 2, 29 (2026). https://doi.org/10.1038/s44387-026-00082-6
キーワード: バーチャルトライオン, 3D再構築, 因果学習, コンピュータビジョン, ファッションAI