Clear Sky Science · ja
LDPCを用いたメモリ内乗算蓄積(MAC)演算誤りの補正
なぜメモリ内計算の誤りを修正することが重要か
現代の人工知能チップは、データをプロセッサとメモリの間で頻繁に往復させる代わりに、メモリ内で直接計算を行うことでハードウェアの速度と効率を高めています。この「メモリ内演算」アプローチはエネルギーを節約しますが、微小な電気的不完全性が保存ビットの反転やアナログ信号の歪みを引き起こし、画像認識のようなタスクの精度を静かに低下させるという重大な問題を生みます。本論文は、こうした誤りをリアルタイムで自動検出・補正する新しい方法を示し、将来のAIハードウェアが高速かつ信頼できるままでいられるようにする手法を提案します。
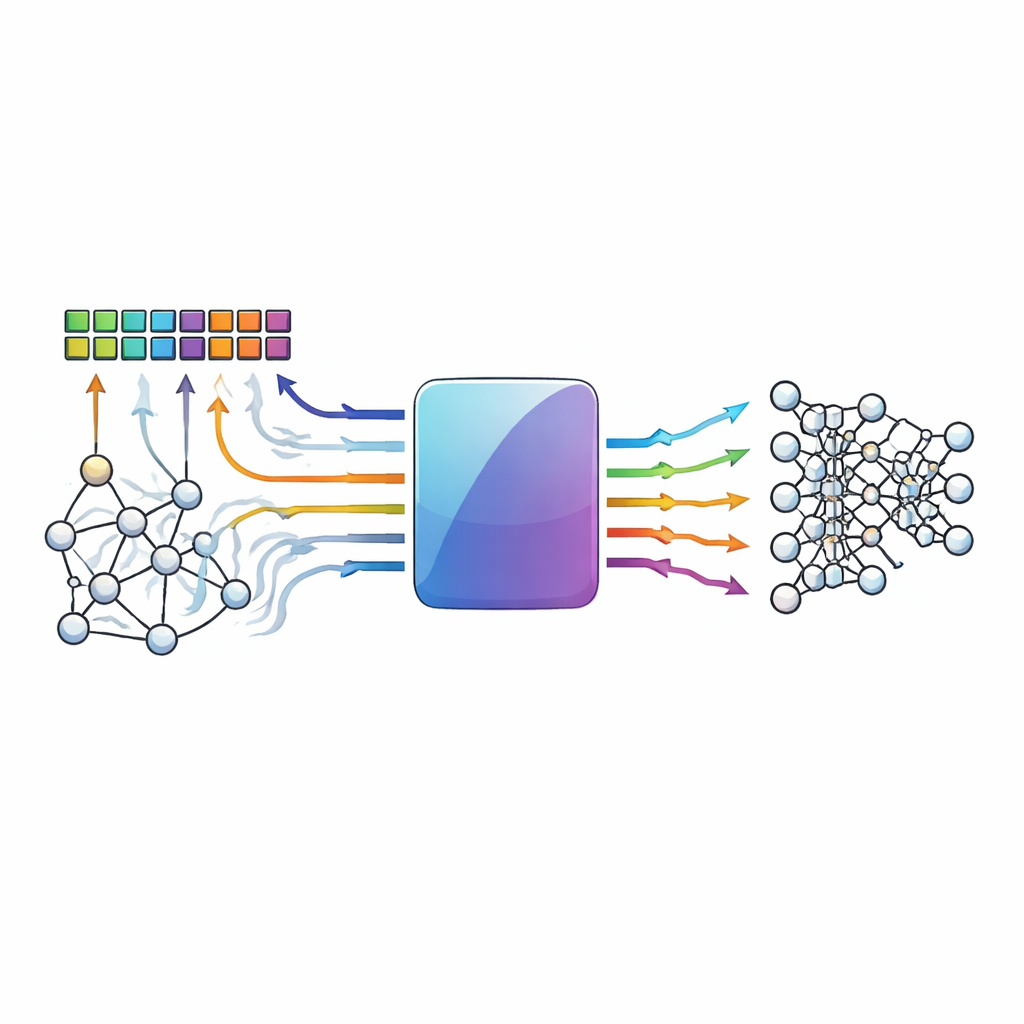
データが存在する場所で計算する
従来のコンピュータは、メモリとプロセッサ間でデータを移動する必要により処理速度が制約されます。メモリ内演算の設計は、このボトルネックを回避し、ニューラルネットワークの基礎である乗算・加算(マルチプライ・アンド・アキュムレート)操作を密集したメモリセルアレイ内で行います。抵抗性RAMなどの新興デバイスや他のメムリスタ要素は、多くの値を格納しアナログ風の演算を高効率で実行できるため特に魅力的です。しかし、アナログ的な性質とデバイスごとのばらつきは強力である一方でノイズも生みます:熱雑音、デバイス不一致、電圧降下などにより、保存された値や計算結果が本来あるべき値からずれてしまうことがあります。
微小な誤差が累積するとき
こうしたメモリ内配列では、多くの行のセルが同時にアクティブ化され、それらの寄与が共有配線に沿って合算されます。参加する行が増えるほど、個々の不完全性が加算され、頻繁かつ複雑な誤りパターンを生み出します。単一の誤ったビットではなく、設計者はしばしば同じ行列の列に複数の誤りが集中したり、従来の誤り訂正手法では対処できない複数列にわたる広がりを伴う誤りを観測します。標準的な符号は通常、単純な誤りパターンと短い語長を想定しているため、複数ビットの誤りを見落としたり、まれだが致命的な組み合わせのためのルックアップ表エントリを欠くことがあります。その結果、基盤となるハードウェアがわずかに信頼性を失うだけで深層ニューラルネットワークのモデル精度が急落することがあります。
新しい種類のデジタル安全網
著者らは、メモリ内演算ハードウェア向けに特化した非二元(非バイナリ)低密度パリティ検査(NB-LDPC)符号を導入します。0と1だけで扱うのではなく、彼らの方式は小さなビット群を素数(本研究では3)に基づく有限体の元として扱う記号(シンボル)単位で動作します。これにより、通常の二進ストレージとアナログアクセラレータで一般的な多レベルや差分エンコーディングの両方を同じ符号で保護できます。システムは各データブロックに少数の追加シンボル(チェックシンボル)を付加します。通常のメモリ読み出しとメモリ内の乗算・加算操作の両方で、ハードウェアはデータとチェックシンボルの結果を同時に計算するため、誤り検出が計算処理に自然に組み込まれます。
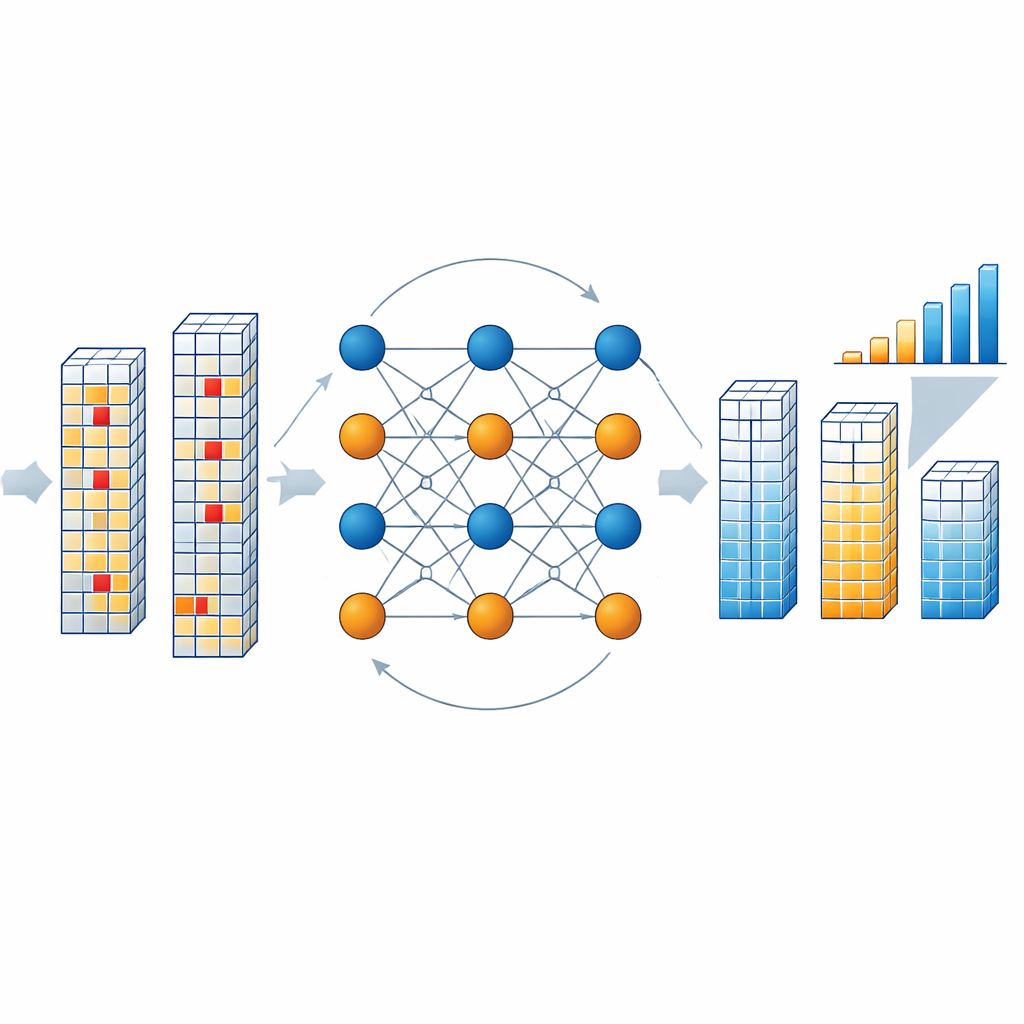
チップ内部で補正エンジンはどう動くか
チップが結果のブロックを読み出すと、専用のデコーダがデータとチェックシンボルの結合が符号で定義されたパリティ関係を満たしているかを調べます。満たしていればブロックは正常とみなされます。満たしていなければ、デコーダは反復プロセスを開始します。この過程では、それぞれのシンボルを表す抽象的な「可変ノード」とパリティ条件を表す「チェックノード」が確率メッセージを交換します。これらのメッセージは、観測された出力とメモリの想定ビット反転率に基づいて、各シンボルが許される各値を取る確率を推定します。著者らはこの数学的に重い推論をマンハッタン距離の近似で単純化し、ハードウェアコストを大幅に削減しつつ性能を高く保っています。数ラウンド(典型的には三回)後、デコーダはメモリを再読出したり計算を停止したりすることなく、最も妥当な補正後の結果ベクトルへ収束します。
シリコンによる実証とAI精度への影響
実際に検証するため、チームは40ナノメートルプロセスでプロトタイプチップを製作しました。これは抵抗性RAMアレイ、軽量のアナログ→デジタル変換器、および新しいNB-LDPCデコーダを組み合わせたものです。256個の情報シンボルを32個のチェックシンボルで保護する構成では、デコーダは高い符号率(約0.8)を達成し、測定で最高約88テラビット修正データ毎秒/ワットの電力効率を示し、面積オーバーヘッドは控えめで、複数のメモリマクロ間で一つのデコーダを共有することでさらに削減可能です。様々な符号サイズに対するシミュレーションでは、1024個のデータシンボルを128個のチェックシンボルで保護する場合、ビット誤り率がほぼ60倍改善されることが示されました。ResNet-34画像分類モデルをメモリ内演算ハードウェア上で実行した場合、本補正を適用することで、厳しい誤り条件下で失われた精度の20パーセントポイント以上を回復しました。
将来のAIチップにとっての意義
平易に言えば、この研究はメモリ内演算ハードウェアに対して堅牢な「スペルチェッカー」を提供します。より豊かなシンボル集合と複雑な誤りパターンを理解しつつ、データストリームを遅延させません。保存データとオンザフライ計算の両方を統一的に保護し、効率的なシリコン実装を示したことで、高密度かつ低消費電力のメモリ内アクセラレータが信頼性を犠牲にする必要はないことを示しています。こうした用途特化の誤り訂正は、モバイル機器から大規模データセンターまで、実世界の応用に対して省エネルギーで信頼性の高いニューロモーフィックやAIアクセラレータを実現する鍵となる可能性があります。
引用: Shi, D., Fu, Y., Zhu, Y. et al. Correcting processing-in-memory multiply-accumulate arithmetic errors with LDPC. npj Unconv. Comput. 3, 14 (2026). https://doi.org/10.1038/s44335-026-00061-9
キーワード: メモリ内演算, 誤り訂正, LDPC符号, 抵抗性RAM, ニューラルネットワークハードウェア