Clear Sky Science · ja
急性精神科ケアにおける攻撃性を予測する機械学習の公平性解析
なぜ現実の人々にとって重要か
病院は、外傷的な抑制に頼らずに害を防ぐため、どの患者が攻撃的になる可能性があるかを人工知能で見分けようとしています。しかし、これらの予測ツールが不公平であれば、「危険」と見なされる対象を既存の不平等でさらに悪化させかねません。本研究は切実な問いを投げかけます:精神科病棟で誰が高リスクかを機械が判断する際、すべての患者を平等に扱っているのでしょうか。
短期リスクを示すための病院データの利用
研究者たちは、2016年から2022年にかけて大規模なカナダの精神医療病院の急性精神科病棟で治療を受けた1万7千人超の患者記録を解析しました。入院中の最大3日分について、現場スタッフはDASA(Dynamic Appraisal of Situational Aggression)という標準のベッドサイドチェックリストを記録しました。DASAは苛立ちや言葉による脅しなど、差し迫った攻撃性を示す行動を評価します。研究チームはこれらのスコアを、診断、年齢、性別、人種・民族、住居状況、来院経路など入院時に収集された情報と組み合わせ、患者が次の24時間以内に攻撃的な事象(抑制や隔離の使用を含む)に関与するかを予測する機械学習モデルを訓練しました。
予測ツールの全体的な性能
最も性能が高かったシステムはランダムフォレストと呼ばれる一般的な機械学習手法を用いていました。ホールドアウトしたテストデータでは高リスクの日を比較的うまく上位にランク付けし、曲線下面積(AUC)は約0.81に達し、精神医療分野の類似ツールと同程度でした。ただし、攻撃事象はまれで—事象のある日1日に対して事象のない日が約33日あった—ため、モデルは多くの真の事象を見逃し、いくつかの誤警報を出しました。重要度の指標は、予測に最も強く寄与しているのは人口統計ではなく、特にDASA項目(苛立ちや直近の事象など)といった瞬時の臨床的要因であることを示しました。これはモデルが臨床的に意味のある警告兆候を捉えていることを意味しますが、性能指標だけではすべての人に対して同じように信頼できるかは明らかになりませんでした。
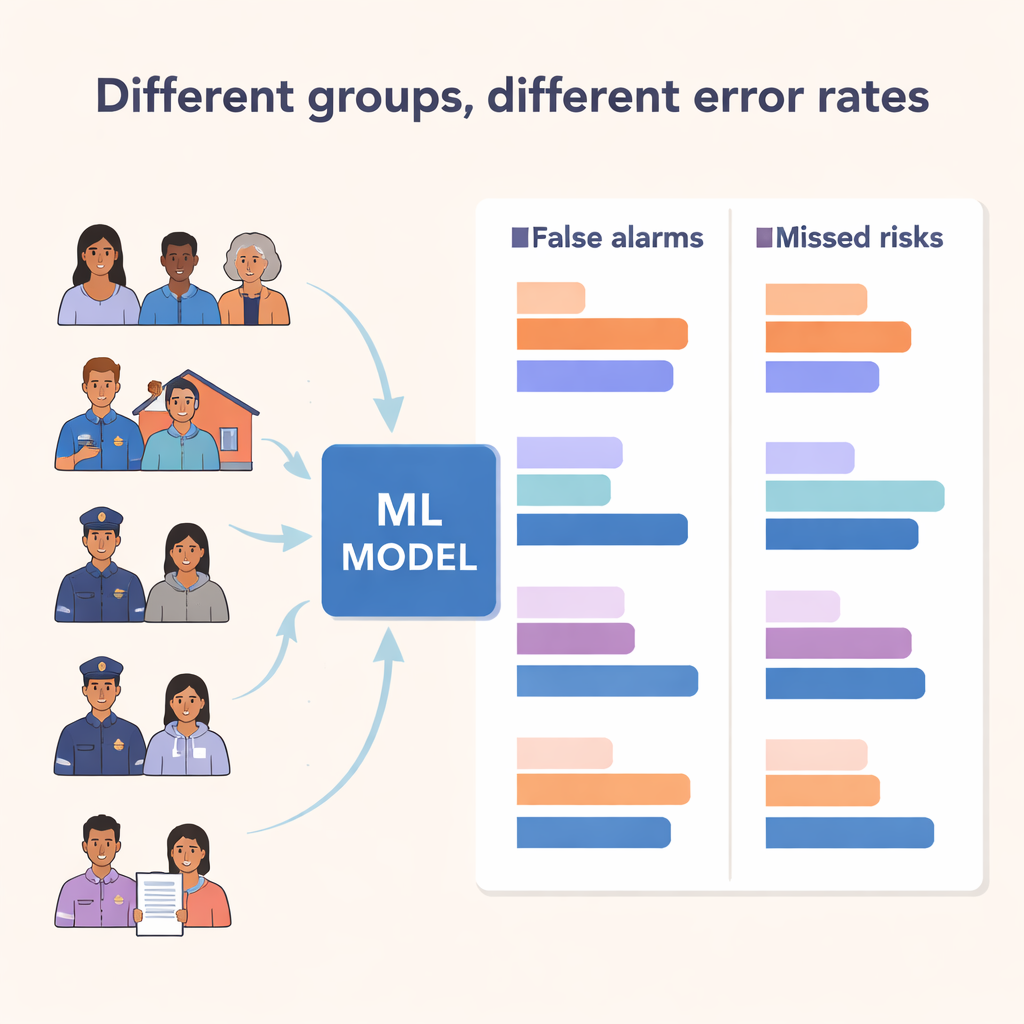
異なる集団間での誤りの不均衡
研究の中心は公平性の検査でした。チームは誤りのうち、誤検知(モデルがリスクを示すが実際には何も起きない場合)と真陽性(モデルが事象を正しく予測する場合)の2種類に注目しました。一般的に用いられる「equalized odds(平等化されたオッズ)」という基準によれば、公平なモデルは集団間で誤検知率と真陽性率が類似しているべきです。しかし研究者たちは大きな差異を見出しました。誤検知は中東出身や黒人の患者、男性、警察に連れて来られた人、住居を持たない人や支援付き住居の人で高くなっていました。ある集団—例えば警察によって連れて来られた患者や不安定な住居にいる人—は検出率も誤警報率も高く、モデルが彼らに対して特に敏感に調整されていることを示唆しました。他方で、黒人患者のように、誤警報が多く真のリスクを正しく識別する能力が低いという憂慮すべき組み合わせを経験する集団もありました。
属性が重なると格差は拡大する
人々の経験は複数の特徴が同時に作用して形づくられるため、研究者たちは人種・民族と性別の組み合わせといった交差するアイデンティティも調べました。ここで最大の警告サインは中東出身の男性に現れ、彼らは全グループ中で最も高い誤検知率を示しましたが、中東出身の女性では同様の傾向は見られませんでした。黒人や先住民の男性も同背景の女性に比べて誤検知が高い傾向がありました。これらのパターンは、特定の人種化された集団や男性に対する警察関与の頻度の高さ、強制的入院、誤診など、精神医療におけるよく記録された不平等を反映しています。機械学習システムはそれらの不平等を作り出したわけではありませんが、不平等が染み込んだデータから学習し、臨床判断においてそれらを増幅する危険がありました。
精神医療における将来のAIの意味
著者らは、公平性解析を予測ツールを実運用に移す前の必須の安全チェックと見なすべきだと主張しています。訓練データの調整や集団別の警告閾値設定といった技術的な「バイアス除去」手法は役立ち得ますが、基礎となる記録が既に不平等な扱いや強制的な慣行を反映している場合には限界があります。結局のところ、何が「公平な」モデルと見なされるかを決めることは単なる数学の問題ではなく、患者、臨床医、コミュニティの意見を要する社会的・倫理的な問題です。本研究は、機械学習が短期の攻撃リスクを識別する助けになり得る一方で、公平性が厳密に測定され、議論され、対処されない限り、構造的な人種差別、性差別、住居に関する不平等を静かに再生産するリスクがあることを示しています。
引用: Wang, Y., Sikstrom, L., Xiao, R. et al. Fairness analysis of machine learning predictions of aggression in acute psychiatric care. npj Mental Health Res 5, 16 (2026). https://doi.org/10.1038/s44184-026-00194-6
キーワード: アルゴリズムの公平性, 精神科における攻撃行為, 医療における機械学習, 健康格差, リスク予測モデル