Clear Sky Science · ja
深層モデルのための前処理付き不正確確率的ADMM
より賢いAIのための賢い学習
チャットボットから画像生成まで、現代の人工知能システムは膨大なニューラルネットワークによって支えられており、これらの訓練は非常に困難でコストがかかります。企業や研究者がデータを多数のデバイスやサーバーに分散させるにつれて、従来の標準的な訓練手法は速度低下や不安定化、あるいは実世界データの雑さに対処できなくなることがしばしばあります。本稿はPISAと呼ばれる手法を中心に据えた新しい訓練アルゴリズム群を紹介し、より少ない数学的仮定でより速く、より信頼性の高い学習を幅広い深層モデルにもたらす可能性を示します。
なぜ現行の訓練法は苦戦するのか
ほとんどの深層学習モデルは確率的勾配降下法(SGD)の変種で訓練されます。これは誤差を減らす方向に何度もパラメータを微調整するアプローチです。AdamやRMSPropなど、多くの改良はステップサイズの適応やモーメントの導入によってこれらの更新を賢くしようとしてきました。しかし、これらの手法は通常、訓練データがきちんとシャッフルされ、複数の計算機間で統計的に類似していること、ある種の数学的量が有界であることを前提としています。特に、各スマートフォンやエッジデバイスが極めて異なるデータを持つフェデレーテッドラーニングのような環境では、これらの仮定が破られることが多く、その結果、収束が遅くなったり性能が低下したりします。
多数の学習者を調整する新しい方法
著者らは、問題を多数の小さな部分に分割して並列に解けることで知られる交互方向乗数法(ADMM)という別の最適化フレームワークを土台としています。主な貢献であるPISA(preconditioned inexact stochastic ADMM)は、全データに対する完全な勾配計算や高価な行列反転を必要とするなどの従来の欠点を避けつつ、ADMMの長所を維持します。代わりにPISAでは、各クライアントやワーカーノードがミニバッチのデータだけを使って自身のモデルコピーを更新し、これらの更新を中央の変数を通じて調整します。慎重に設計された「前処理」行列が更新方向を整え、学習がより滑らかかつ効率的に進むようにします。 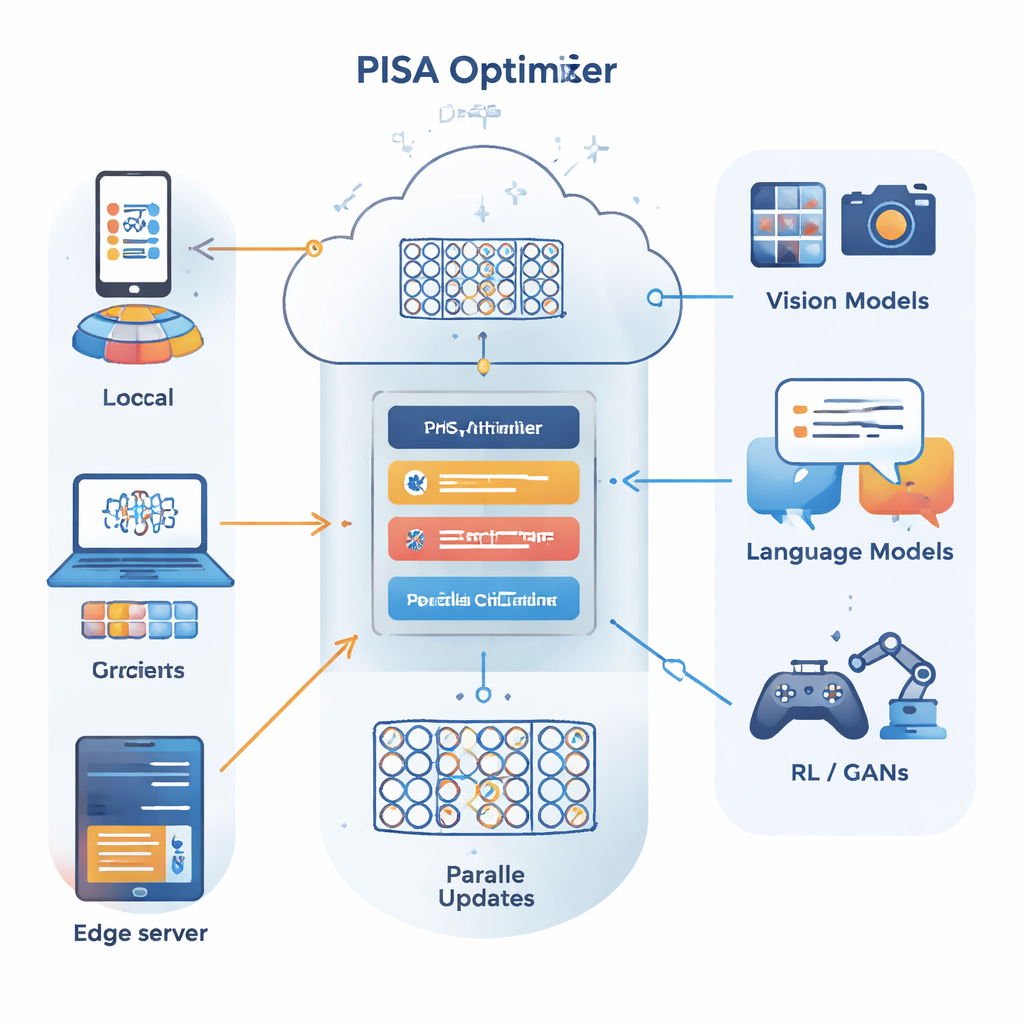
より緩い仮定で得られる強い保証
PISAの特徴のひとつはその理論的基盤です。著者らは、損失関数の勾配が有界領域内でリプシッツ連続であるという、比較的穏やかな一つの仮定の下でアルゴリズムが収束することを証明しています。この条件は多くの標準的なニューラルネットワークの損失で満たされます。一般的な確率的手法とは異なり、PISAは勾配が不偏であること、分散が有界であること、あるいはデータが完全に混合されていることを必要としません。この緩和された設定にもかかわらず、関数値とパラメータ更新が安定する速さの点で線形収束率を達成しており、提示された比較表でも上位に位置します。これにより、現実の配備で一般的な異種で非一様なデータ分布に対して特に魅力的な手法となっています。
実用的な大規模ネットワーク向けの変種
大規模なニューラルネットワークに対して実用的にするために、著者らは2つの効率的な変種、SISAとNSISAを導入します。SISAは二次モーメント情報、つまり過去の更新が各パラメータ方向でどの程度大きかったかを追跡することで単純な対角前処理子を構成し、これはAdamやRMSPropの考え方に似ていますがADMM構造の内部に組み込まれています。NSISAはさらに一歩進めて、Muonオプティマイザに触発されたNewton–Schulz直交化という手法を取り入れ、モーメントをパラメータ空間の有益な方向によりよく整列させます。両変種ともPISAの収束保証を維持しつつ、最新のGPUや大規模モデルに対して計算コストを軽く保っています。
ビジョン、言語、生成モデルにおける性能
著者らは幅広い深層学習タスクでSISAとNSISAを評価しました。意図的にラベル分布を歪めたフェデレーテッドラーニングの実験(各クライアントがクラスのサブセットしか見ない厳しい設定)では、SISAはFedAvg、FedProx、FedNova、Scaffoldといった一般的手法を大きく上回り、MNISTやCIFAR-10などのベンチマークではるかに高いテスト精度を達成しました。ResNetやDenseNetのようなモデルを用いたCIFAR-10やImageNetでの標準的な画像分類でも、SISAはモーメント付きSGD、AdaBelief、AdamWなどの強力なオプティマイザと同等かそれ以上の性能を示しました。サイズを増すGPT2言語モデルのファインチューニングでは、NSISAがShampoo、SOAP、Adam-mini、Muonなどの専用オプティマイザよりも短い実時間で低い検証損失を出し、特に大きなモデルほどその利点が顕著になりました。また、生成対向ネットワーク(GAN)の訓練を安定化させ、生成画像の視覚的品質と多様性を測るFréchet inception distance(FID)を低下させました。 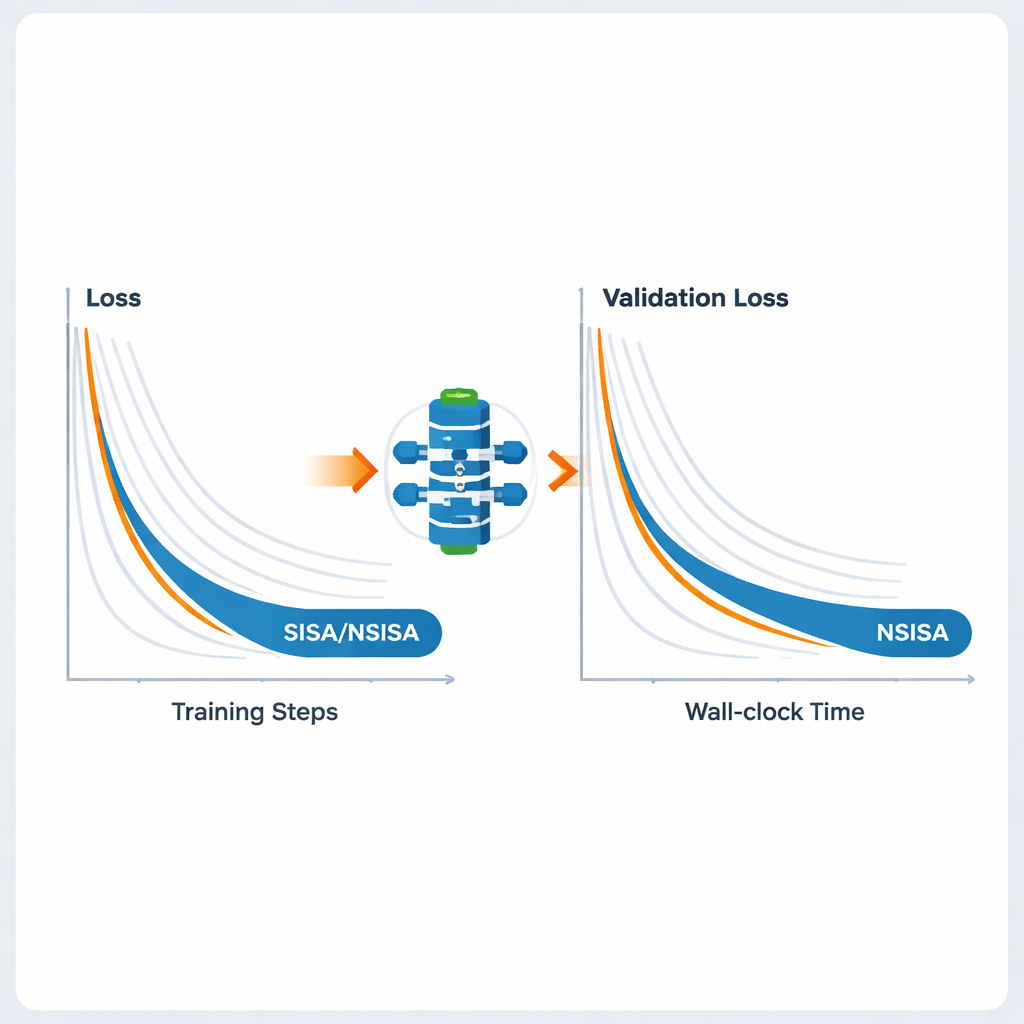
日常のAIにとっての意味
平たく言えば、本研究はデータが雑で不均衡であったり多くのデバイスに分散しているような状況でも、強力なAIモデルをより速く、より確実に訓練できることを示しています。学習率の調整だけにとどまらず、基盤となる最適化プロセスを再設計することで、PISAとその変種はビジョン、言語、強化学習、生成タスクに幅広く適用できる統一的なツールを提供します。エンドユーザーにとっては、スマートフォン上でのより賢いパーソナライゼーション、より高機能な言語・画像モデル、大規模データセンターにおける計算資源のより効率的な利用といった恩恵が期待でき、これらは現代のAIシステムの現実により合った訓練アルゴリズムによって実現されます。
引用: Zhou, S., Wang, O., Luo, Z. et al. Preconditioned inexact stochastic ADMM for deep models. Nat Mach Intell 8, 234–245 (2026). https://doi.org/10.1038/s42256-026-01182-3
キーワード: ディープラーニング最適化, フェデレーテッドラーニング, 確率的ADMM, 大規模言語モデル, 異種データ