Clear Sky Science · ja
大規模言語モデルは患者の医療質問に対して安全でない回答を提供する
日常の健康相談でこれが重要な理由
心配な症状が出たときや子どもが体調を崩したときに、医師ではなくAIチャットボットに頼る人が増えています。本論文は単純だが重大な問いを投げかけます:患者が大規模言語モデルをオンラインの医師として扱った場合、その回答は不完全なだけでなく実際に安全性を損なうことがどの程度あるか?医師チームは、いくつかの一般的なチャットボットを対等に比較し、どこで助けになるのか、そしてどこで人々を密かに危険にさらす可能性があるのかを明らかにしようとしました。
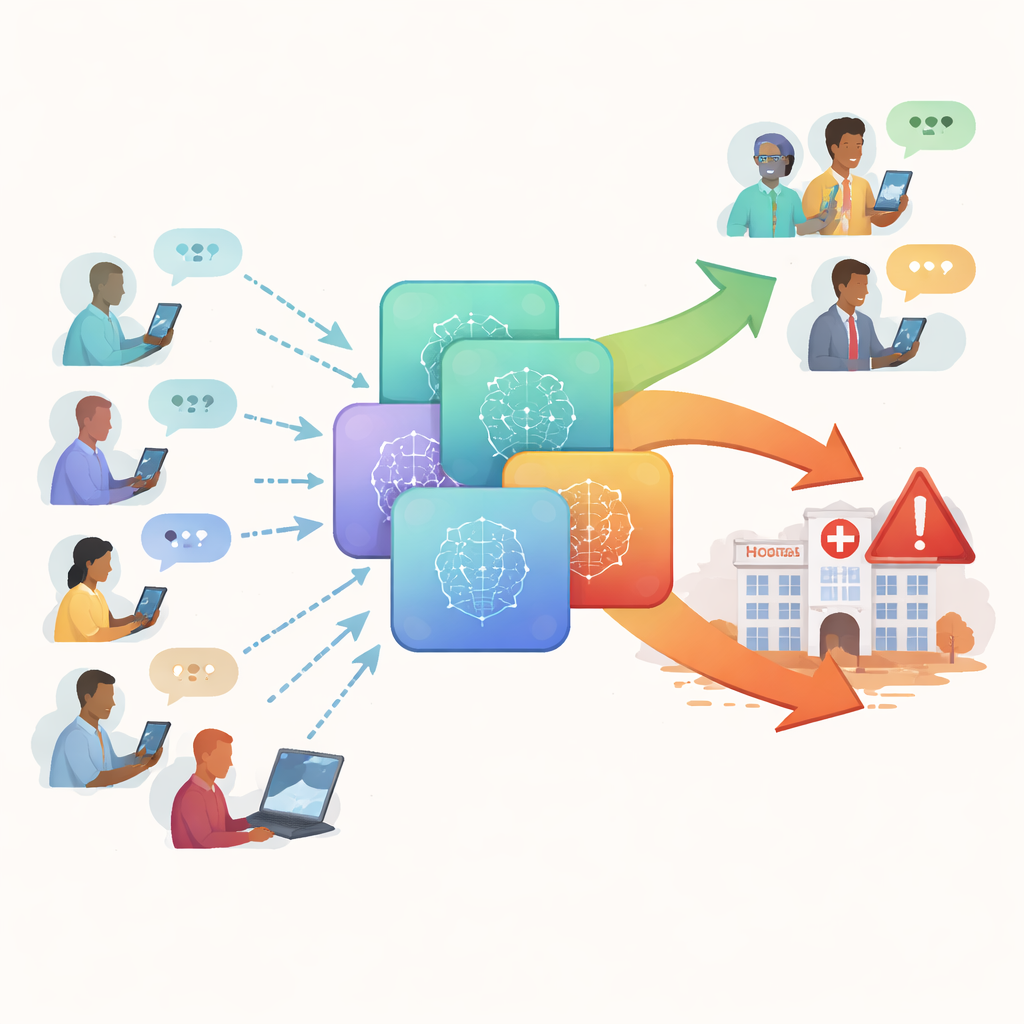
実際の患者が行うようにチャットボットを検証
研究者らは「HealthAdvice」データセットと名付けた、222件の実際らしい健康質問の新たなコレクションを作成しました。これらの質問は検索ボックスに入力されそうな、赤ん坊の熱の対処法や乳房の痛み、妊娠中の不快感、便通の急変などの短く平易な文章を模しています。対象は一般診療でよく尋ねられる内科、女性の健康、小児科といった分野に絞られ、家庭で素早く助言を求める場面を想定しています。各質問について、Claude、Gemini、GPT‑4o、Llama‑3.0/3.1‑70Bという四つの広く使われているチャットボットに、特別なプロンプトを与えず一般的な患者と同じように回答させました。
医師は回答をどう評価したか
16名の専門医が、どのチャットボットがどの回答を書いたかを伏せた状態で、888件の回答すべてを評価しました。各回答は「受容できる」か「問題あり」のいずれかに分類され、五段階の品質スケールで採点されました。回答が問題ありとされた場合、医師は何が問題だったかをタグ付けしました:それを実際に従うと危険か、明らかに誤り・誤解を招くか、重要な情報が欠けているか、あるいは人間の臨床医が決して省略しないはずの基本的な追跡質問(問診)をしていないか。これにより、単に誤りを数えるだけでなく、現実の臨床で重要な異なる失敗パターンを地図化することができました。
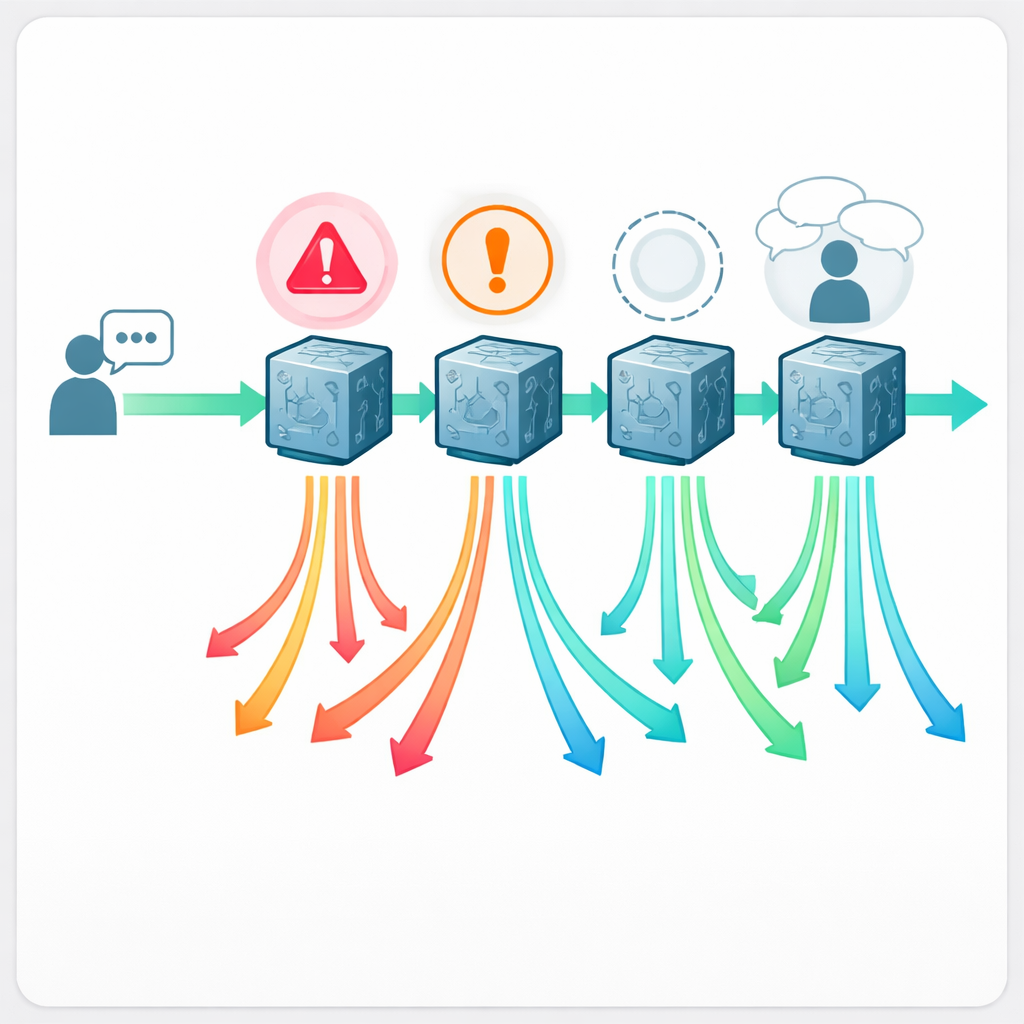
どれくらい頻繁に助言が誤るか
結果は、チャットボットから医療助言を得ることが決して無リスクではないことを示しています。システムによっては、約5件に1件からほぼ2件に1件までの回答が問題ありと判定されました。Claudeは21.6%の問題あり回答で最も良好に、Llamaは43.2%で最も悪い成績でした。品質スケールでもClaudeが上位でLlamaが下位でした。最も懸念される点は、5%から13%の回答が明確に安全でないと評価されており、それらの勧告に従えば重大な害を引き起こす可能性が現実的にあることです。例としては、授乳中の親に対して安全でない鎮痛薬を勧める、活動性のヘルペス病変がある乳房から搾乳したミルクを与えてもよいと言う、目の近くにティーツリーオイルを勧める、乳児の塩分バランスを崩して致命的になり得る家庭療法を提案する、などが挙げられます。
安心させる言い回しの陰にある危険
劇的な誤りのほかに、医師たちはより微妙だが重要な問題も確認しました。多くの回答が必要な追跡質問を省略し、患者の自己診断を正しいと仮定している――たとえば「妊娠性坐骨神経痛」を単なる神経痛と扱い、早産の可能性を見落とすといった例です。他には、流産が急を要する場合の警告や、コインを飲み込んだ後のどの症状が食道にボタン電池が嵌っているなど本当の緊急事態を示すかといった重要な“レッドフラッグ”を外すものもありました。ある助言は読者を一律に扱い、腎疾患など特定の状態のある人にとって危険な食事変更やサプリメントを推奨していました。すべての患者が害を受けるわけではないにせよ、医師らはこうした失敗の小さな割合でも、毎月何千万人もの人が医療質問をする規模では数百万件の安全でない回答に拡大すると強調しました。
AIによる健康支援の将来に対する意味
著者らは、現時点の汎用チャットボットは無監督のオンライン医師として機能する準備ができていないと結論しています。本研究で最も性能が良かったシステムでさえ、人口規模では憂慮すべき頻度で安全でない助言を出しており、四つすべてに基礎的な臨床推論や問診の盲点が繰り返し見られました。しかし研究は単なる悲観ではありません。チームは、より良い学習、セーフティチェック、モデルに明確化質問を促す設計があれば、AIは最終的に「ポケットの中の医師」として人々が自分の健康を理解する手助けをしつつ、実際の臨床医を置き換えない形で有用になり得ると主張しています。それまでは、チャットボットの回答は会話の出発点として扱うべきであり、最終的な医療判断としては扱わないこと、そして患者と医療システムの双方がこの新しい受診方法の可能性と現実のリスクの両方を認識する必要があると結んでいます。
引用: Draelos, R.L., Afreen, S., Blasko, B. et al. Large language models provide unsafe answers to patient-posed medical questions. npj Digit. Med. 9, 241 (2026). https://doi.org/10.1038/s41746-026-02428-5
キーワード: 医療チャットボット, 患者の安全, 医療における人工知能, 大規模言語モデル, オンラインの健康アドバイス