Clear Sky Science · ja
インテリジェント手術のための大規模自己教師ありビデオ基盤モデル
手術室でのより賢い支援
現代の外科医はカメラやコンピュータに頼ることが増えていますが、現在の人工知能は手術中に何が起きているかを完全に理解するのがまだ難しい状況です。本論文では、何千本もの手術ビデオでAIを学習させる新しい方法を提示し、手順の段階を追跡し、器具や組織を認識し、手術の進行が安全で熟練しているかを評価できるようにします。長期的には、この種の技術がリアルタイムで外科医を支援し、トレーニングを改善し、患者にとって手術をより安全にする助けとなる可能性があります。
機械に手術を教えるのが難しい理由
コンピュータに手術を理解させることは、いくつかのラベル付き画像を与えるだけで済むほど簡単ではありません。あらゆる処置ではカメラが動き、視点が変わり、煙や血液、互いに遮る手や器具が発生します。さらに、何千種類もの手術があり、多くはまれです。動画データをフレームごとに丁寧にラベル付けするには専門家の時間が必要で、すぐにコストがかさみます。以前のAIシステムはラベル無し画像から学ぶ工夫でこの負担を軽減しようとしましたが、多くは静止フレームを中心に扱い、時間の感覚を後から付け加えようとしていました。その結果、手術の前後関係や今起きていること、次に起こりうることといった進行の流れを見落とすことが多くありました。
手術映像から直接学ぶ
著者らは、手術を支援するAIは静止画像ではなくビデオで訓練されるべきだと主張します。そのために彼らはこれまでで最大級の内視鏡手術ビデオコレクションの一つを集めました:公的研究データセットと広範なオンライン手術映像から集めた3,650本の記録、合計355万フレームです。これらのビデオは20種類以上の手術と10以上の解剖領域にまたがり、胆嚢摘出から肝臓手術、婦人科手術まで含みます。この多様性により、AIは異なる病院、器具、カメラのスタイルを含む現実の手術のさまざまな見え方を学ぶことができます。
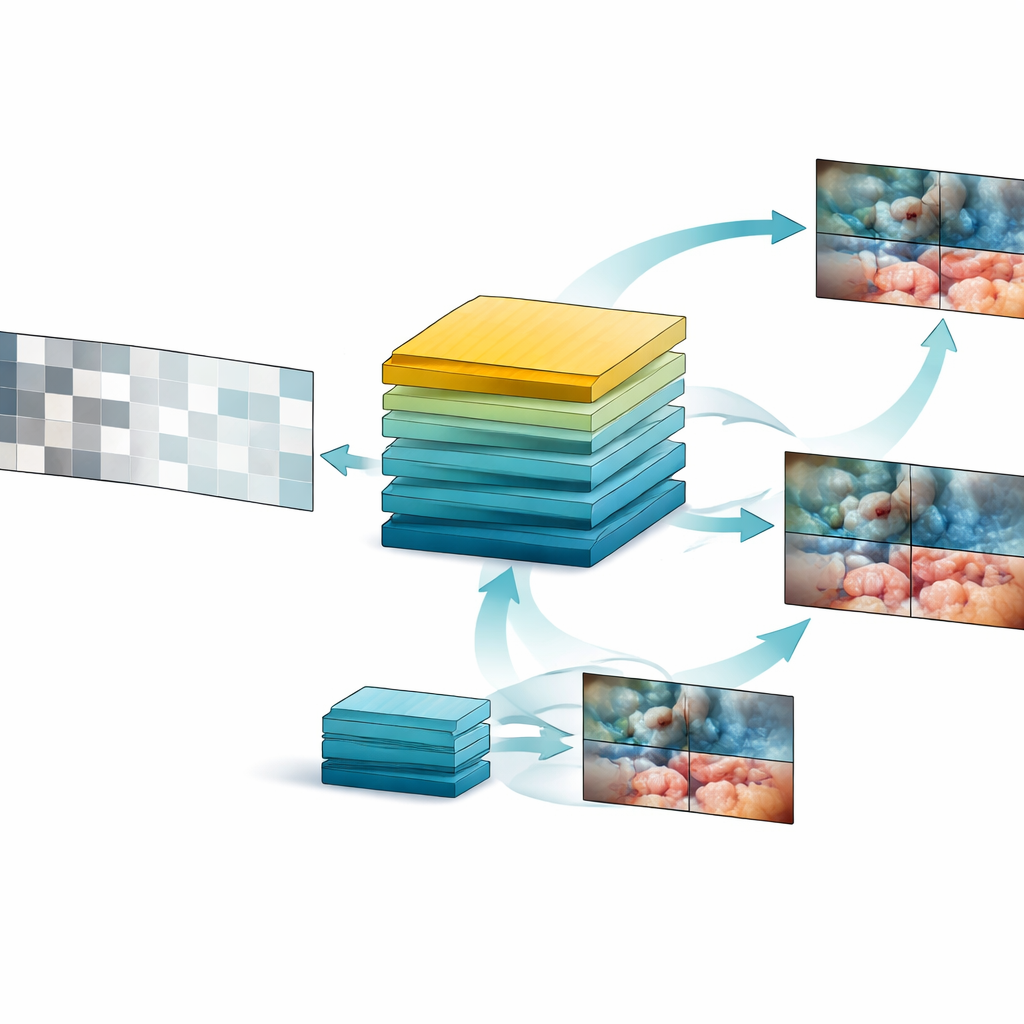
ビデオに特化した新しい学習設計
このデータの宝庫を基に、チームはSurgVISTAという手術ビデオに特化した「基盤モデル」を設計しました。各フレームにラベルを付けようとする代わりに、SurgVISTAは欠けている部分を埋めることで学びます。訓練中、各ビデオクリップの一部が隠され、モデルは欠損領域を再構築しなければなりません。これにより、組織、器具、動きが時間とともにどのように変化するかに注意を払うことが強制されます。同時に、システムの別の枝は、手術シーンに関して既に多くを知っている強力な画像ベースのエキスパートモデルが捉える詳細な視覚手がかりと一致させるように訓練されます。この組み合わせにより、SurgVISTAは各フレーム内の細部と手術全体の大きな流れの両方を、単一の統一されたネットワーク内で把握できます。
モデルの実地検証
このアプローチが本当に効果を上げるかどうかを確かめるために、著者らは6種類の手術と4つの実用的タスクを含む13の異なるデータセットでSurgVISTAを評価しました。タスクには、手術のどの段階が進行中かの認識、特定の外科的行為の識別、器具・行為・標的組織の三者関係の把握、主要ステップがどれだけ安全に実行されたかの判断が含まれます。総じてSurgVISTAは、日常動画で訓練された先行モデルや主に静止画像に基づく既存の手術特化システムを上回りました。訓練で一度も見たことのない手術に対しても高い性能を示し、学んだパターンが単一の臓器、器具セット、病院に限定されないことを示しました。
より多く、より豊かなビデオデータが重要な理由
研究はまた、訓練データを増やすと性能がどのように変わるかを調べました。著者らがビデオプールの規模と多様性を徐々に拡大するにつれて、SurgVISTAの結果はほとんどの場面で改善しました。訓練セットにまったく含まれない手技に対しても改善が見られました。興味深いことに、モデルは同じ手術の例が増えることで恩恵を受けただけでなく、異なる種類の手術からも利益を得ました:多様な手術の「物語」に触れることで、専門領域を超えて転移する一般的な視覚パターンや動作パターンを見つけられるようになったのです。追加の実験では、画像ベースのエキスパートからの補助が、重要な解剖学的細部を保持するモデルの能力をさらに鋭くしたことが示されました。これは例えば重要構造と周辺組織を区別するうえで重要です。
将来の手術にとっての意味
平たく言えば、この研究は空間と時間の両方を考慮して大量の実際の手術ビデオで訓練されたAIが、手術室で何が起きているかについてはるかに深い理解を構築できることを示しています。SurgVISTAはまだ独自に意思決定を行うツールではありませんが、手術の進行を追跡したり、危険な瞬間を検出したり、訓練を支援したり、病院間で技術を比較したりするために他のアプリケーションが組み込める強力な基盤を提供します。著者らはより広範なデータと臨床試験が引き続き必要であると述べていますが、彼らの結果は、ビデオベースの基盤モデルが将来のインテリジェントな外科システムにおける重要な要素となり、手技をより安全に、より一貫して、各患者により適切に適応させる助けとなる可能性を示唆しています。
引用: Yang, S., Zhou, F., Mayer, L. et al. Large-scale self-supervised video foundation model for intelligent surgery. npj Digit. Med. 9, 220 (2026). https://doi.org/10.1038/s41746-026-02403-0
キーワード: 手術ビデオAI, 自己教師あり学習, 手術ワークフロー, コンピュータ支援手術, 時空間モデリング