Clear Sky Science · ja
大規模言語モデルは国やコード体系を越えた電子カルテベースの予測の移転性を向上させる
医療データを賢く共有することが重要な理由
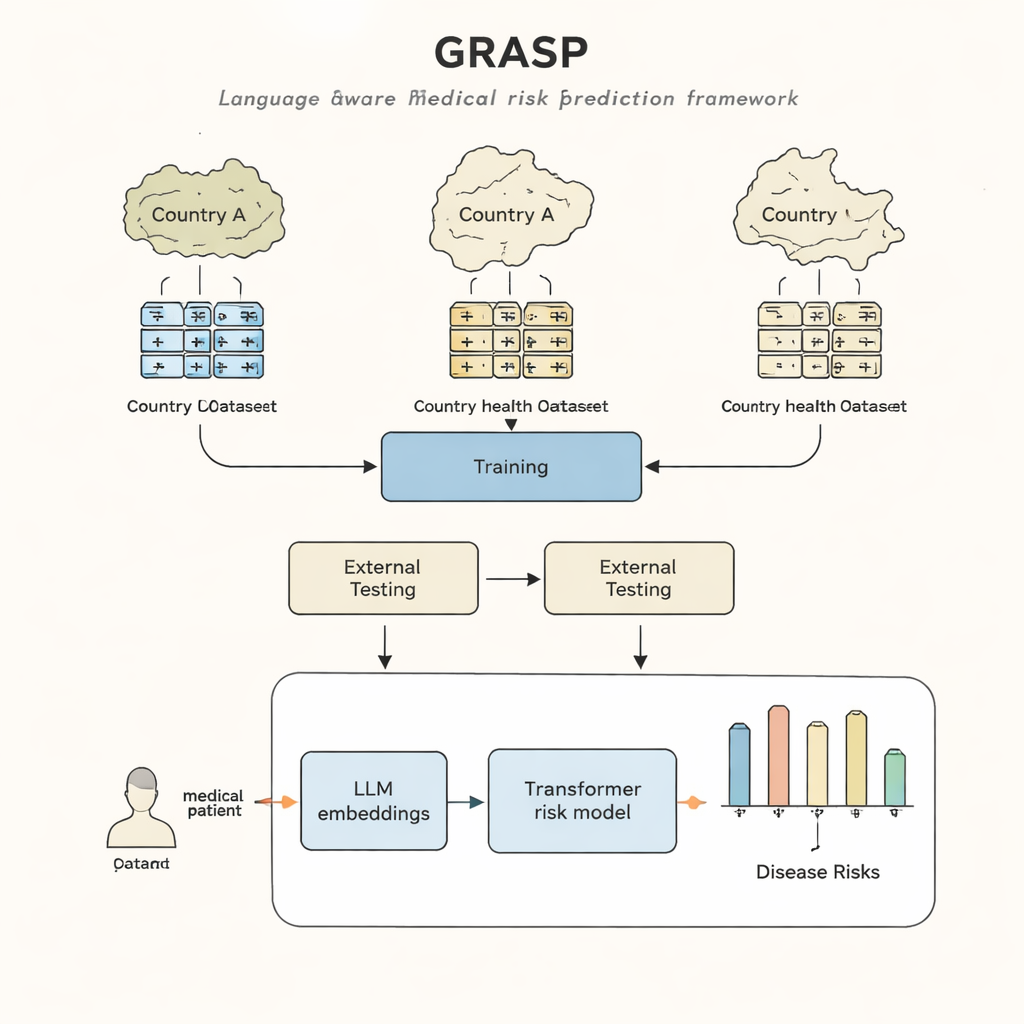
世界中の病院や診療所には情報の宝庫があります。診断、治療、経過を何年にもわたって記録した電子カルテです。理論上は、こうした情報を用いれば医師は症状が明確になる前に重篤な病気のリスクが高い人を早期に見つけることができます。しかし実際には、各国や医療機関ごとに健康データの記録方法が異なるため、今日のコンピュータモデルはある国や病院システムから別の場所へ「移動」して使うのが難しいのが現状です。本研究はGRASPと呼ばれる新しい手法を提案します。これは人工知能の進歩を利用して、ある保健システムで学習したモデルが他でも信頼して機能するようにそのギャップを埋めます。
病院ごとに異なる「言語」
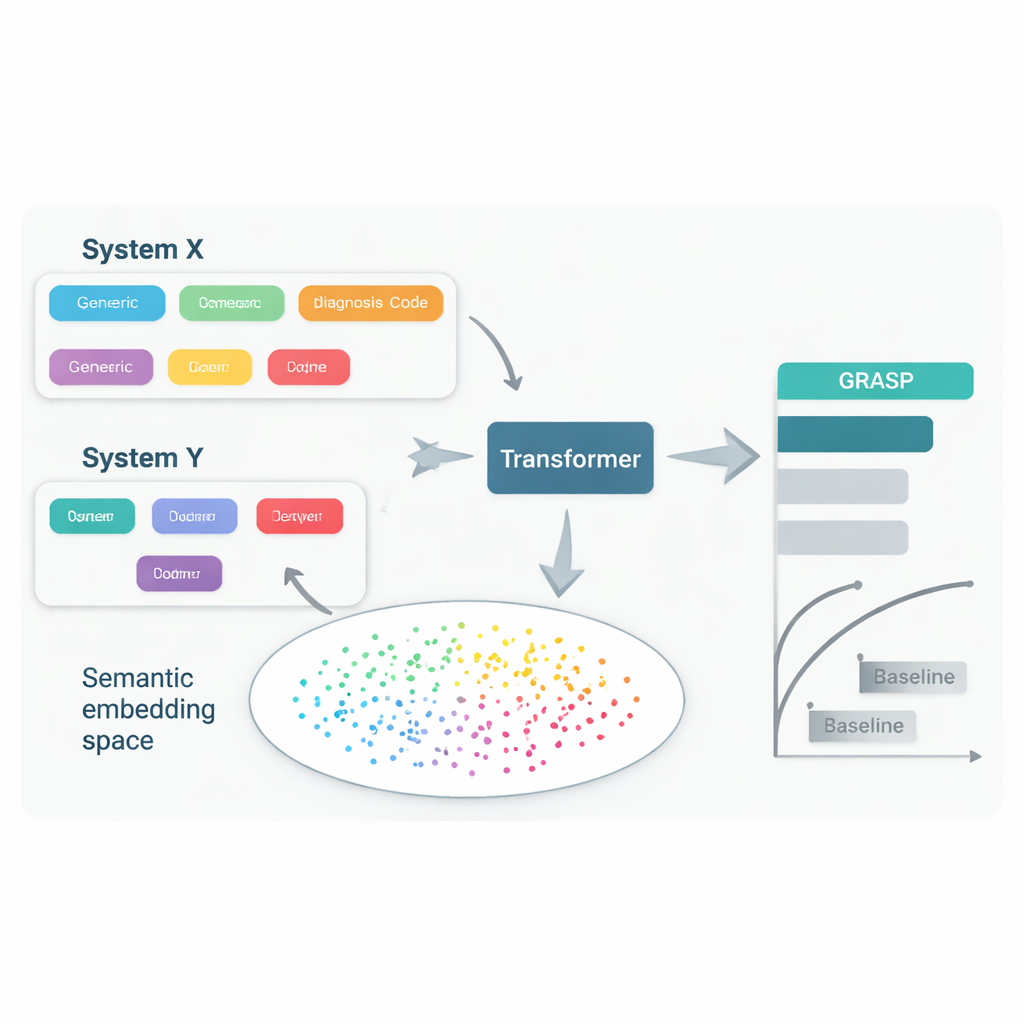
同じ病気を扱っていても、医師や施設は病歴に記録する際に異なるコード体系や慣習を使うことが多くあります。ある病院は「高血糖」を一つのコードで記録するかもしれませんが、別の病院は「高血糖症(hyperglycemia)」という別のコードを使い、さらに別のところではまったく違う体系を採用していることもあります。大規模な国際的コード標準へと統一しようとする取り組みは有用ですが、遅く、費用もかかり、重要な差異を残してしまいがちです。その結果、ある国の記録から疾患を予測するモデルは別の場所で精度を落とすことがあり、こうしたツールの恩恵を受けられる人が限られてしまいます。
コードだけでなく意味を読ませる
GRASPのアプローチは単純な発想に立ちます。各医療コードを意味のない識別子として扱うのではなく、「急性上気道感染」などコードに付随する人間の記述を大規模言語モデルに読ませ、その意味を数値化した「埋め込み(embedding)」に変換するのです。これらの埋め込みは、異なるコード体系や国から来た概念であっても関連するものを近くに配置する共有空間を作ります。GRASPは標準的な医療用語を何百万件も事前に埋め込み化してルックアップテーブルに保存します。患者の医療履歴はこうした豊かなベクトルの列として表現され、それらをトランスフォーマーネットワーク—多様な入力の集合を扱うのに適したニューラルネットワーク—に与え、21の主要疾患と全体的な死亡リスクを推定します。
国や記録システムを越えた検証
研究者たちはまず英国バイオバンクのほぼ40万人のデータでGRASPを訓練し、再訓練なしで2つのまったく異なる環境でテストしました:フィンランドのFinnGenプロジェクトとニューヨーク市の大規模病院ネットワークです。GRASPは、人気のある手法であるXGBoostや、言語に基づく埋め込みを使わない類似のトランスフォーマーを含む強力な代替手段に対して同等かそれ以上の成績を示しました。フィンランドでは特に顕著で、ぜんそく、慢性腎臓病、心不全といった病態で明確な改善が見られました。注目すべきは、アメリカの病院データが共有標準に変換されずに別のコード体系のままであっても、GRASPはコード記述の文言を理解することでコードを整合させられたため、人口統計情報だけよりも優れた予測を提供できた点です。
少ないデータでより多くを引き出す
GRASPのもう一つの利点は効率性です。言語モデルが既に多くの医療概念が関連していることを学習しているため、予測ネットワークがそれらの関連性を一から再発見する必要がありません。著者らが英国データのかなり小さなサブセット—わずか1万人にまで—でGRASPを訓練したときでも、同じ限られたサンプルで訓練された競合モデルより優れた成績を示し、英国内だけでなく海外への転移時にも優位性を保ちました。さらに、GRASPのリスクスコアは複数の疾患について遺伝的な素因とより近く一致しており、単に一つのデータセットのパターンを記憶しているだけでなく、疾患感受性のより深い側面を捉えていることを示唆しています。
今後の医療にとっての意義
専門外の方への主要なメッセージは、GRASPは現代の言語ベースのAIが、各医療システムを硬直した一つのコード体系に無理に統合することなく「同じ言語を話す」ように助け得ることを示している点です。医療用語の意味を読み取ることで、GRASPは国や記録フォーマットを越えて一般化しやすい疾患リスク予測を、より少ない患者例で実現できます。実際の臨床利用に先立ち、この手法は慎重な検証、再校正、公平性のチェックが必要ですが、ある場所で開発された強力なリスクツールを世界中の病院や診療所と安全かつ効率的に共有できる未来を示しています。
引用: Kirchler, M., Ferro, M., Lorenzini, V. et al. Large language models improve transferability of electronic health record-based predictions across countries and coding systems. npj Digit. Med. 9, 177 (2026). https://doi.org/10.1038/s41746-026-02363-5
キーワード: 電子カルテ, 疾患リスク予測, 大規模言語モデル, 医療データ共有, 医療分野のAI