Clear Sky Science · ja
分散型機械学習およびAI臨床モデルを地域内・集中型代替と比較する:系統的レビュー
データを共有せずに医療知見を共有することが重要な理由
現代医学は、病気を早期に発見し、適切な治療を選び、誰が最もリスクが高いかを予測するために、ますます人工知能に依存しています。しかし、優れたAIツールには膨大な患者データが必要であり、病院が記録を単純に統合することは、厳しいプライバシー規制や倫理的懸念のためにできません。本稿は「分散型」学習、つまり生データを共有することなく病院が共同でAIを訓練する手法に関する10年以上の研究をレビューし、実用的な問いを投げかけます:これらのプライバシー保護手法は、従来のアプローチと比べて実際にどれほど性能が出るのか?
プライバシーを守りながら患者から学ぶ新しい方法
従来の集中型学習では、病院がすべてのデータを一つの大きなデータベースにコピーして単一のモデルを訓練します。一方でローカル学習では、各機関が自らのデータで独立してモデルを構築し、協力は行われません。分散型学習はその中間を提供します。例えばフェデレーテッドラーニングでは、各病院がローカルでモデルを訓練し、モデルのパラメータ(ニューラルネットワークの「つまみ」に相当するもの)だけを送信して共有モデルに統合します;患者記録は現場を離れません。スウォームラーニングは中央の調整者を排し、機関同士がモデル更新を直接交換できるようにします。他の分散型アプローチには、複数のローカルモデルの予測を組み合わせる方法や、モデル自体をサイト間で分割する方法があります。これらの手法は、がん検出やCOVID‑19診断から心疾患、糖尿病、脳疾患、精神疾患に至るまで多様な問題で試されています。
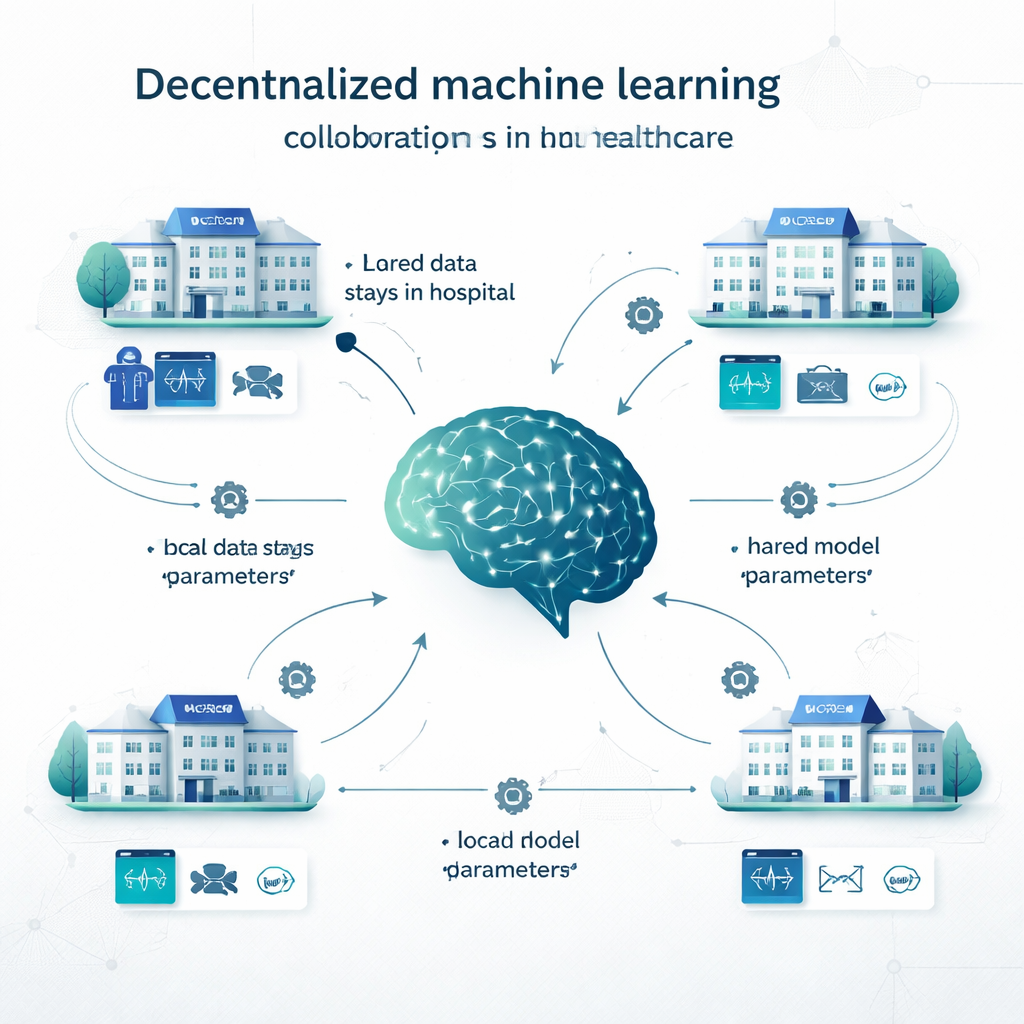
研究者が調べたこと
著者らは11の主要データベースを系統的に検索し、2012年から2024年3月までに公表された165,010件の研究を精査しました。重複や実際の臨床判断を伴わない研究を除外した後、160件の論文が残りました。これらの論文は合わせて710の分散型モデルと、集中型またはローカルモデルに対する8,149件の直接的な性能比較を報告していました。多くの研究は診断に焦点を当てていましたが、画像セグメンテーション(例えば腫瘍の輪郭抽出)、生存や合併症など将来のアウトカム予測、複合タスクに関する研究も多数ありました。カバーされたデータ型は、電子カルテ、CTやMRI、X線、デジタル病理スライド、心・脳の信号、さらには遺伝学データに至るまで、医療で用いられるほとんどの主要な情報源を網羅していました。
プライバシー保護型モデルは集中型AIとどう比べられるか
分散型モデルと、プールされたデータで訓練された集中型モデルを比較すると、集中型学習がわずかに優位に出ることが多かったです。特に精度やDice係数のような「閾値ベース」の指標での勝率が高く、約4分の3で集中型が勝ち、その差は中程度から大きめの利点と見なされることがありました。しかし、患者を低リスクから高リスクへと順序付ける能力を示すAUROC(ROC曲線下面積)のような順位付け型指標では、分散型と集中型の差は小さく、集中型にわずかな優位があるにとどまりました。重要なのは、著者らが「臨床的に実用的」と呼ぶ性能(0.80以上のスコア)に両者が到達した場合、集中型の典型的な利得は控えめで、しばしば1〜1.5パーセンテージポイント未満であることです。多くの状況では、これは「優秀と許容可能」の差に相当し、「利用可能と無用」の差ではありませんでした。
なぜ分散型学習は単独より優れるのか
レビューで最も明確だった信号は、分散型モデルと純粋にローカルなモデルを比較した際に得られました。精度、AUROC、F1スコア、感度、特異度、特に適合率など、主要な指標のほとんどで分散型手法はほぼ常に優れ、多くの場合その差は大きかったです。直接比較では、精度、適合率、AUROCといった主要指標で分散型学習がローカルモデルを上回った割合は80%を超えていました。多くのケースでローカルモデルは臨床的有用性の閾値である0.80に達せず、一方で対応する分散型モデルは余裕を持ってクリアし、感度を最大で27パーセンテージポイント改善することもありました。著者らはこれを、多施設モデルが得る「より広い経験」に帰しています:多数の病院からのパターンを“見る”ことで、スキャナや記録方法に特有の偏りに惑わされにくくなり、本当に一般化する疾患の特徴により敏感になるのです。
性能、プライバシー、実用性のバランス
レビューの結論は、プライバシー規則や運用上の理由でデータ統合が可能であり、かつ性能のわずかな差が重要な場面(例えば極めて稀な疾患)では、集中型学習が依然としてゴールドスタンダードであるというものです。しかし、分散型学習はGDPRやEU AI法のような法律、あるいは機関の方針によりデータ共有が制限される状況において、強力で臨床的に受け入れられる代替手段を提供します。モデルを完全にローカルに保つ場合と比べて、分散型アプローチは精度と信頼性の両面で大きな改善をもたらしつつ、データを病院内に留めます。著者らは、将来の研究ではプライバシー技術や計算コストをより明確に報告すべきであり、医療機関がわずかな性能トレードオフがプライバシーと協力の大きな利点に見合うかどうかを判断できるようにするべきだと主張しています。
引用: Diniz, J.M., Vasconcelos, H., Rb-Silva, R. et al. Comparing decentralized machine learning and AI clinical models to local and centralized alternatives: a systematic review. npj Digit. Med. 9, 174 (2026). https://doi.org/10.1038/s41746-025-02329-z
キーワード: フェデレーテッドラーニング, 医療分野のAI, 医療データのプライバシー, 分散型機械学習, 臨床予測モデル