Clear Sky Science · ja
脳と大規模言語モデルにおける予測、構文、意味の基盤化
脳が次の語をどう予測するか
物語を聞いているとき、自然に内容についていけると感じることが多いですが、その背後では脳が常に次に来るものを推測しています。同時に、現代のAI、特に大規模言語モデル(LLM)も次の語を予測して流暢な文章を生成します。本研究はこの二つの領域を融合させ、人間の脳がリアルタイムで語をどのように予測するか、そしてその過程が高度なAIモデルの働きとどう比較されるかを問います。
実験室で物語を聴く
自然な言語理解を調べるため、研究者たちは単語の人工的な列や短く孤立した文を超えた手法をとりました。29人の若年成人の協力者がドイツ語のSFオーディオブックを約50分間聴いている間に脳活動を記録しました。併用した手法は、頭皮上の微小な電位変化を測る脳波(EEG)と、脳活動から生じる磁場を検出する脳磁図(MEG)です。これらを組み合わせることで、連続する物語を追いながら各単語への脳の反応をミリ秒単位で追跡できます。
異なる種類の語を追う
オーディオブックは自動的に個々の単語に分割され、文法カテゴリでラベル付けされました:名詞(例えば「planet」)、動詞(例えば「run」)、形容詞(例えば「dark」)、固有名詞。物語中の各単語について、研究者たちは語の前後の短い時間窓のEEGおよびMEG信号を切り出し、各語クラス内で平均化しました。これにより、意味や文構造に関連する既知の成分を含む、異なる語タイプに対する信頼できる電気的・磁気的“署名”が明らかになりました。重要な点として、名詞に対する活動は語が実際に始まる前から高まっており、文脈において脳が特にその種類の語に備えていることが示唆されました。
意味と運動が出会う場所
これらの信号が脳のどこから生じているかを調べるため、研究者たちはコンピュータモデルを用いて頭内部でのMEGおよびEEGパターンの推定源を求めました。名詞は時間葉の古典的な言語領域を活性化するだけでなく、運動や身体感覚に関与する領域の近くに位置する感覚運動系と整合する領域も巻き込みました。対照的に動詞はより異なり限定的なパターンを示しました。これは、特に具体的な名詞の理解が、抽象的な規則だけでなく知覚や行動に結びついたネットワークの再活性化によって意味が基盤化される、いわゆる「具現化された」言語の考え方を支持します。
脳と大規模言語モデルの比較
続いて研究チームは計算的な参照点としてMetaのLlama 3.2言語モデルに注目しました。まず「意味的予測」を試すため、オーディオブックの前後関係をモデルに入力し、実際に続く次の語がどれだけ高い確率だとモデルが判断するかを調べました。名詞はモデルにとって最も予測しやすく、物語を構築する上での中心的役割と一致しました。次に「構文的予測」を探るため、Llama内部の活性化(埋め込み)を調べました。追加学習を行っていなくとも、モデルの隠れ層は次に来る語の文法カテゴリに従って単語を自然にグループ化し、単純なプローブネットワークでしばしば次に来る語クラスを推定できました。層を重ねるごとに、固有名詞や名詞の内部構造がより明確に分離され、脳活動パターンで見られる役割の分化と呼応していました。
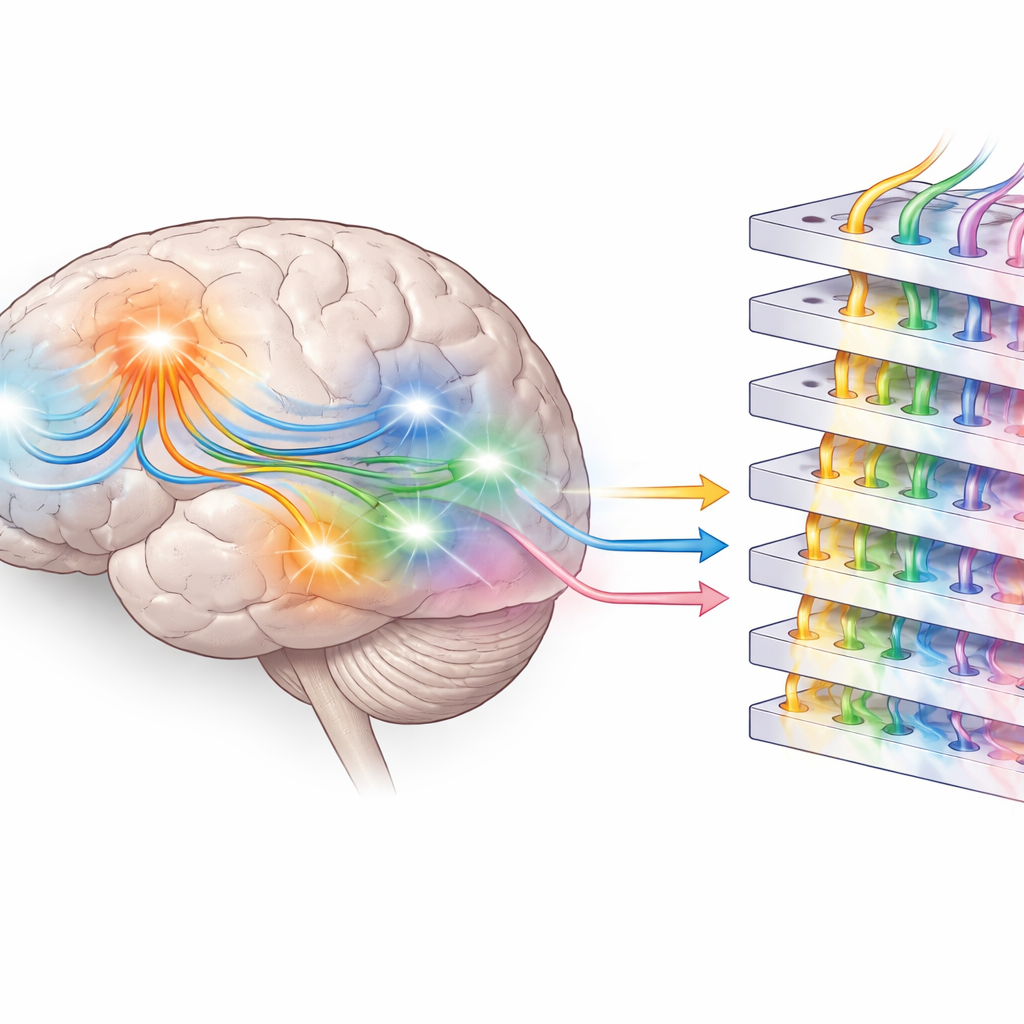
語に対する二つの備え
総じて、本研究の結果は脳が少なくとも二つのレベルで次の言葉に備えていることを示唆します。側頭領域では、語の出現前の活動がある種の文法的、つまり「構文的」な備えを反映しているように見えます—文中で特定の語タイプが現れやすい位置に関する知識です。より前方および感覚運動領域では、備えのパターンが名詞や固有名詞に特に結びついた、意味や経験に関連するより豊かな「意味的」期待を担っているようです。次の語を予測するだけで訓練された大規模言語モデルは、これらの区別を部分的に鏡映する層状の内部構造を発達させますが、物理的世界への直接的な基盤は欠いています。高速な脳記録と最先端AIの解析を組み合わせることで、この研究は人間が日常の聞き取り中に語をどのように予期しているか、そして現代の機械がその人間の言語理解の中核的特徴をどこまで近似しているかを明確にする手掛かりを提供します。
引用: Kölbl, N., Rampp, S., Kaltenhäuser, M. et al. Prediction, syntax and semantic grounding in the brain and large language models. Sci Rep 16, 8728 (2026). https://doi.org/10.1038/s41598-026-41532-0
キーワード: 言語予測, 脳とAI, 大規模言語モデル, 意味の基盤化, EEG MEG 言語