Clear Sky Science · ja
データ不足下における鉱床有望度マッピングのためのアンサンブル機械学習戦略
手がかりが少ない中で鉱床を見つける
現代社会は鉛や亜鉛のような金属を電池、電子機器、インフラに依存していますが、最も見つけやすい鉱床はすでに発見されていることが多いです。新しい地域では、地質学者が頼れるのはごくわずかな確定した鉱床、散在する化学サンプル、不完全な地図だけということがよくあります。本研究は、機械学習を過去データで可能な限り高いスコアを追うために使うのではなく、情報が乏しい状況でも意思決定者が実際に信頼できる予測を提供するためにどう使うかを示しています。
現実にデータが薄い理由
鉱床有望度マッピングは、地形のどの部分が鉱床を含む可能性が高いかを示すことを目的としています。岩石種類、断層、衛星画像、河川堆積物の化学組成などの情報層を組み合わせて、現地調査やボーリングを導く確率マップを作ります。しかし初期段階のプロジェクトでは、既知の鉱床が少数しかなく、地図の多くの領域は一度もサンプリングされていないことが多いです。標準的な機械学習手法は大規模でよくラベル付けされたデータに適しており、陽性例が数十しかないような場合には不安定になり過信しがちで、精度が高く見える数値を出しても現実と乖離していることがあります。
乏しい手がかりを実用的な信号に変える
著者らはイラン中央部のデハーク鉛–亜鉛地区で作業しました。この地域では鉱化は特定の石灰岩層、断層、化学的変質帯に結びついています。地質調査と衛星画像から宿主岩、断層密度、変質のデジタルマップを作成し、624件の堆積物サンプルから地球化学的異常を抽出しました。この豊富だが偏りのある証拠から、最終的にラベル付けされた地点は108個に絞られました:既知の鉱床がある27点とない81点です。多数クラスが少数の鉱床例を圧倒するのを避けるために、著者らは既存の鉱床点の間を補間して現実的な合成鉱床点を生成する手法を用い、学習データ内だけでクラスを均衡化しました。これにより、検証・テスト用のセットは実世界の希少性を反映したまま、よりバランスの取れた学習用例が得られました。 
一人のヒーローではなくモデルのチームを構築する
単一のアルゴリズムに依存する代わりに、本研究は異なる強みを持つ手法を組み合わせました。あるアンサンブルはクラス間に最も鋭い境界を引くサポートベクターマシンと、単純な確率モデルであるガウシアンナイーブベイズを組み合わせました。もう一方は多変数の複雑なパターンを捉えるのに優れたツリーベースの手法、LightGBMとAdaBoostを混成しました。どちらの場合も最終予測は構成モデルの確率推定の平均であり、この戦略は性能の振れを抑えることが多いです。重要なのは、著者らがモデルの正解率だけでなく、予測確率がどれだけ現実に一致しているか――すなわち較正(キャリブレーション)の良さ――も比較した点です。
スコアではなく信頼のためにチューニングする
モデルの設定(誤分類にどれだけ厳しく罰を与えるか、木の本数など)は挙動を大きく変え得ます。チームは3つの一般的なチューニング戦略を試しました:固定された選択肢を系統的に走査するGrid Search、組み合わせをランダムに抽出するRandom Search、過去の試行を利用して有望な候補を推測するBayesian Optimizationです。紙上では、Bayesian Optimizationがサポートベクターベースのアンサンブルに対して単独で最高の識別能力スコア(ROC–AUC 0.95)を示しました。しかし著者らが予測確率と実際の結果を比較する較正曲線を調べたところ、両アンサンブルのGrid Search版が特に探索判断が置かれがちな中間確率域でより滑らかで安定した結果を示しました。 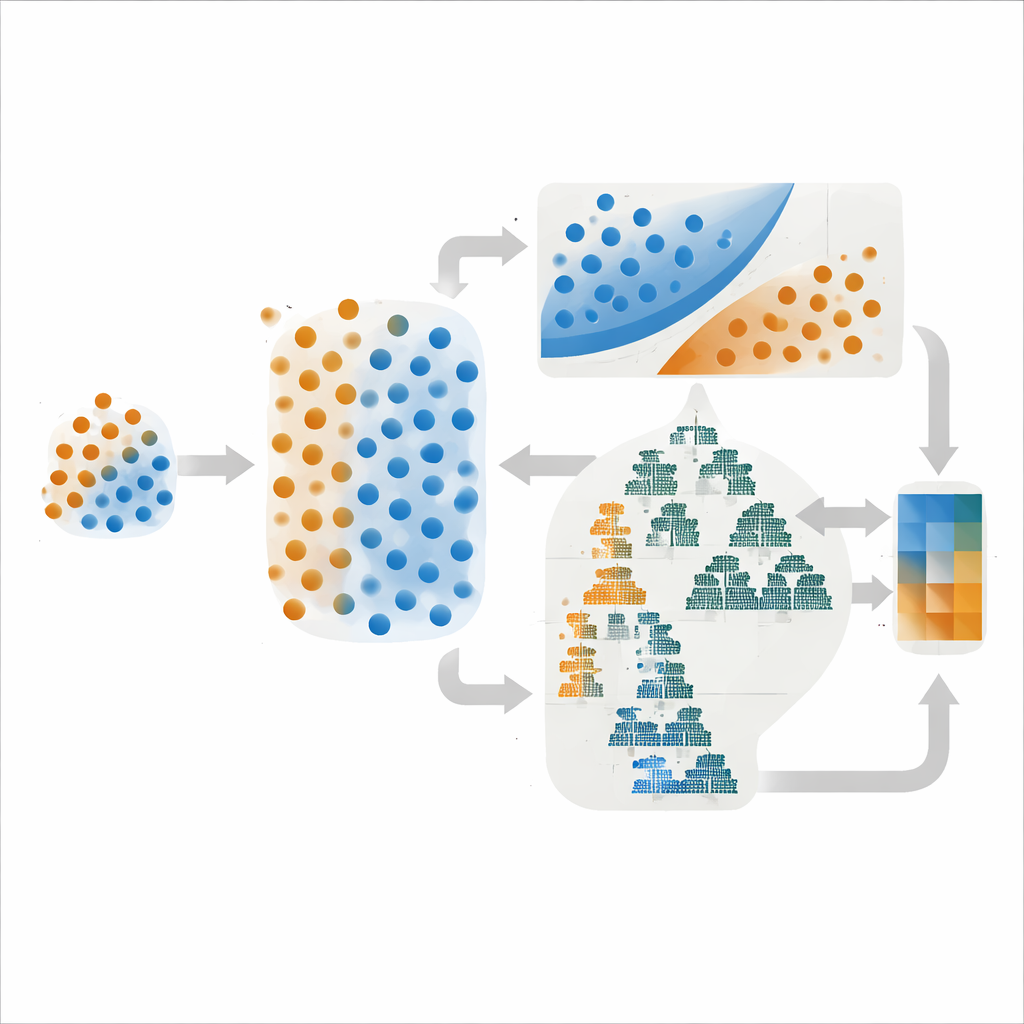
数値から現地での意思決定へ
ボーリング一本が高価な初期探査においては、著者らはわずかな精度向上を追うよりも、挙動が良好な確率がより重要だと主張します。彼らの最も実用的な推奨は、Grid Searchで調整したよりシンプルなサポートベクター+ベイズのアンサンブルです。これは識別能力が高い一方で、確率値と実際の発見率の間に最も信頼できる結びつきを提供し、地質学者が自己のリスク許容度に合わせて閾値を設定できるようにします。プロジェクトが成熟してデータが増えると、LightGBMアンサンブルのようなより複雑なツリーベースモデルを導入して予測を洗練することもできますが、常に較正に注意を払うべきです。こうして機械学習はブラックボックスのスコア生成器ではなく、次世代の鉱物資源を探す場所についてリスクを踏まえた意思決定を行うための透明なパートナーになります。
引用: Amirajlo, P., Hassani, H., Pour, A.B. et al. Ensemble machine learning strategies for mineral prospectivity mapping under data scarcity. Sci Rep 16, 9171 (2026). https://doi.org/10.1038/s41598-026-40125-1
キーワード: 鉱床有望度マッピング, アンサンブル機械学習, データ不足, モデル較正, 鉱物探査