Clear Sky Science · ja
KM-DBSCAN:グリーンAIに向けたデータ削減のための、密度と重心に基づく境界検出フレームワークの拡張
AIを小さくすることが環境に優しくなる理由
人工知能には見えないコストがある:電力だ。最新の機械学習モデルの学習は、多くの場合、電力を大量に消費するハードウェア上で何百万ものデータ点を処理することを伴い、結果として炭素排出を生む。本論文は、モデルが実際に必要とする情報を捨てずにトレーニング前にデータセットを縮小する新しい手法、KM-DBSCANを紹介する。最も情報量の多いデータだけを残すことで、学習を高速化しエネルギー消費を削減しつつ、手書き数字認識から皮膚がんの早期検出までのタスクで高い予測精度を維持する。
データ過多はエネルギー過多につながる
長年にわたり、AIにおける支配的な考え方は「データが多ければ多いほどモデルは良くなる」というものだった。確かに精度を高めることがあるが、それは学習時間の延長、より大きな計算機、そして高い電気代を意味する。研究者たちは、コストを問わず精度を追求する「Red AI」と、性能と環境負荷のバランスを取ろうとする「Green AI」を区別し始めている。より環境に優しいAIへの有望な道の一つがデータ削減である:利用可能なすべての例をモデルに与える代わりに、特に分類器の判断を決める難しい境界例を含む、問題を十分に定義するはるかに小さな例の集合を特定する。
二つの単純な発想を組み合わせた賢いフィルター
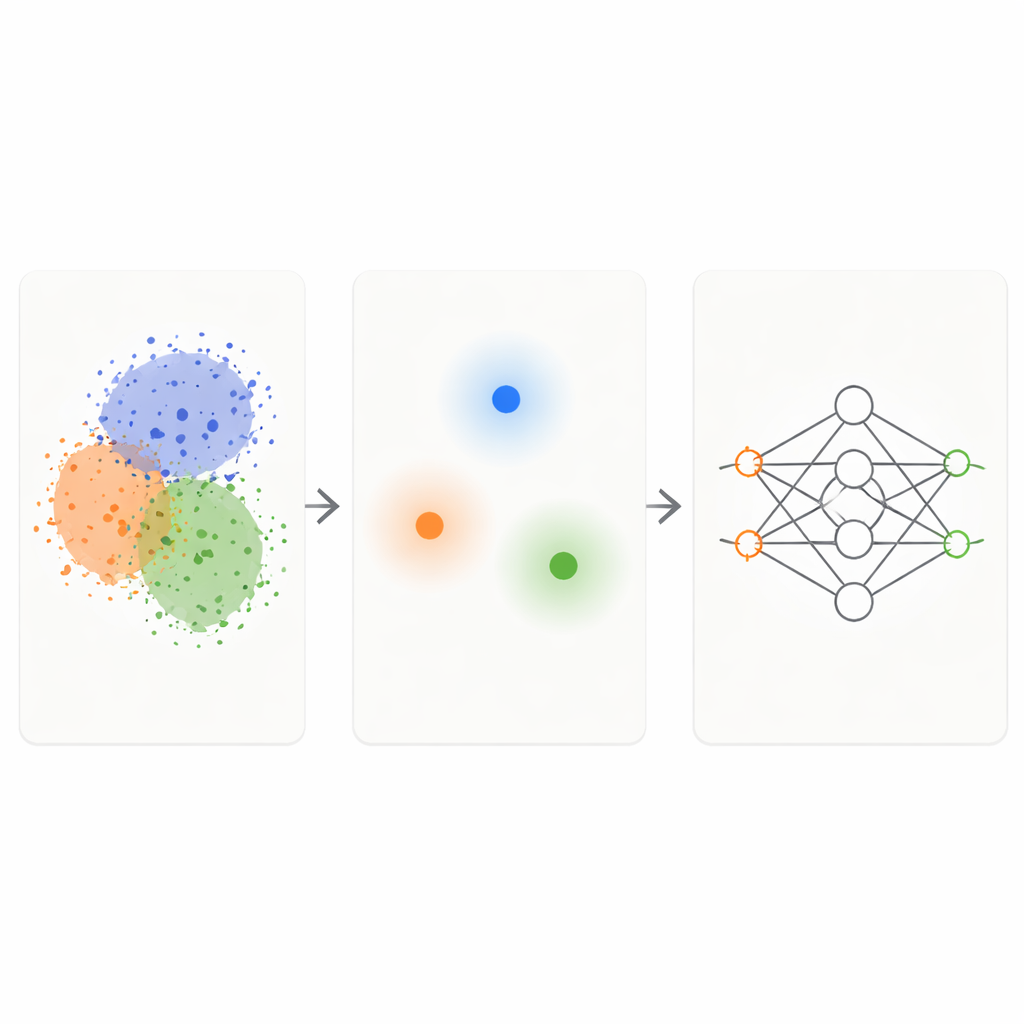
KM-DBSCANフレームワークは、二つのよく知られたクラスタリング手法を組み合わせて、生データに対するインテリジェントなフィルターとして機能する。まず、K-Meansという高速な手法が点をコンパクトなクラスタにまとめ、各群を代表する中心(セントロイド)で置き換える。これにより、何千あるいは何百万の点を数百の代表点に縮小できる。次に、密度ベースの手法(DBSCAN)をそのセントロイド上で実行し、クラスタ間の境界にある領域と、密で均質な内部や孤立したノイズ領域を見つける。セントロイドのレベルで処理することで、DBSCANは全データ点に直接適用する場合よりはるかに高速になり、パラメータ選定への過敏さも低くなる。

重要で難しい事例だけを残す
KM-DBSCANが異なるグループが接するまたは重なり合う場所を特定すると、境界近くにあるデータ点のみを残し、深い内部点と明確な外れ値は破棄する。内部点は主に冗長である:どれも似たような外観を持ち、そのクラスについてモデルに同じ情報を送る。これに対して境界点は、あるクラスがどこで終わり別のクラスがどこで始まるかをモデルに明示する。合成の簡易データセットでは、この戦略はほとんどの点を削除しても、分類器が元の全データから学ぶのと同じ決定境界を再現する。Banana、USPS手書き数字、Adult所得データセット、車両衝突データ、乾燥豆の品種、メラノーマ皮膚画像などの実世界データセットでも、削減された集合は問題の主要な構造を保持しつつ、サイズが一桁小さくなる。
速度向上、炭素削減、そして実用例
著者らはKM-DBSCANをサポートベクターマシン、多層パーセプトロン、畳み込みニューラルネットワークなど複数の一般的なモデルの前処理として評価した。多くの場合、削減データでの学習はほぼ同等の精度を保ちつつ数十〜数千倍速くなり、場合によっては精度がわずかに向上することもあった。例えば手書き数字認識では、学習セットを元の1.4%にまで削減しながら精度をわずかに向上させ、学習を284倍速くした。クラス不均衡のある所得予測タスクでは、約3%のデータでほとんど精度を落とさずに6907倍の高速化を達成した。メラノーマ検出の実験では、ディープニューラルネットワークが元の皮膚画像データセットの3分の1未満で90%を超える精度に達し、炭素排出を70%以上削減した。
日常のAIにとっての意義
専門外の人にとっての主要なメッセージは、賢い選択は単なる量より勝るということだ。KM-DBSCANは、モデルが見る例を慎重に選び—最も情報量の多い境界事例に焦点を当てることで—計算時間とエネルギー消費を大幅に削減しつつ予測の信頼性を保てることを示している。このアプローチは、データの質と学習パイプラインの設計が単なるモデルサイズと同じくらい重要であるという、グリーンAIの広い潮流にうまく適合する。広く採用されれば、医療画像解析から交通安全システムに至るまで、巨大な計算資源を持たない組織でも強力なAIツールを持続可能に利用できるようになるだろう。
引用: AboElsaad, M.Y., Farouk, M. & Khater, H.A. KM-DBSCAN: an enhanced density and centroid based border detection framework for data reduction towards green AI. Sci Rep 16, 10349 (2026). https://doi.org/10.1038/s41598-026-40062-z
キーワード: グリーンAI, データ削減, クラスタリング, 機械学習の効率化, メラノーマ検出