Clear Sky Science · ja
2Dエンコーダのみで実現するデータ効率の高い3D医療ビジョン・ランゲージモデル
3Dスキャンからより賢い支援を
医師がCTやMRIを読むとき、単一の画像を見るだけでなく、数百枚のスライスを頭の中でつなぎ合わせて三次元で問題を把握します。コンピュータに同じことをさせられれば、診断が速く、一貫性が増し、患者向けの報告も明確になる可能性があります。しかし現状の3Dスキャンを扱う人工知能は非常に「データを食う」ため、多くの病院がもつ十分なラベル付き大規模データを必要とします。本論文は、既存の2D画像技術を活用して3Dレベルの理解を得る手法を提案し、構築と導入が容易で低コストな強力なツールを実現する道を示します。
なぜ3DスキャンはAIにとって難しいか
現在の「ビジョン–ランゲージ」システムは、既に2Dの医用画像を見て質問に答えたり、一般的な言葉で報告を作成したりできます。それを3Dボリュームに拡張すれば、臓器全体や多くのスライスを見ないと明確にならない微細な病変について推論できるようになります。問題は、多くの既存の3Dシステムが、専用の3D画像エンコーダをスクラッチで学習させることに依存しており、巨大でラベル付きのスキャン集合を必要とする点です。こうしたデータセットは希少で注釈が高価、しばしば資金力のあるセンターに限られるため恩恵を受けられる場所が限られます。同時に、各スライスを独立した2D画像として扱うだけでは、スライス間の連続性が失われ、モデルは冗長な情報に溺れてしまいます。
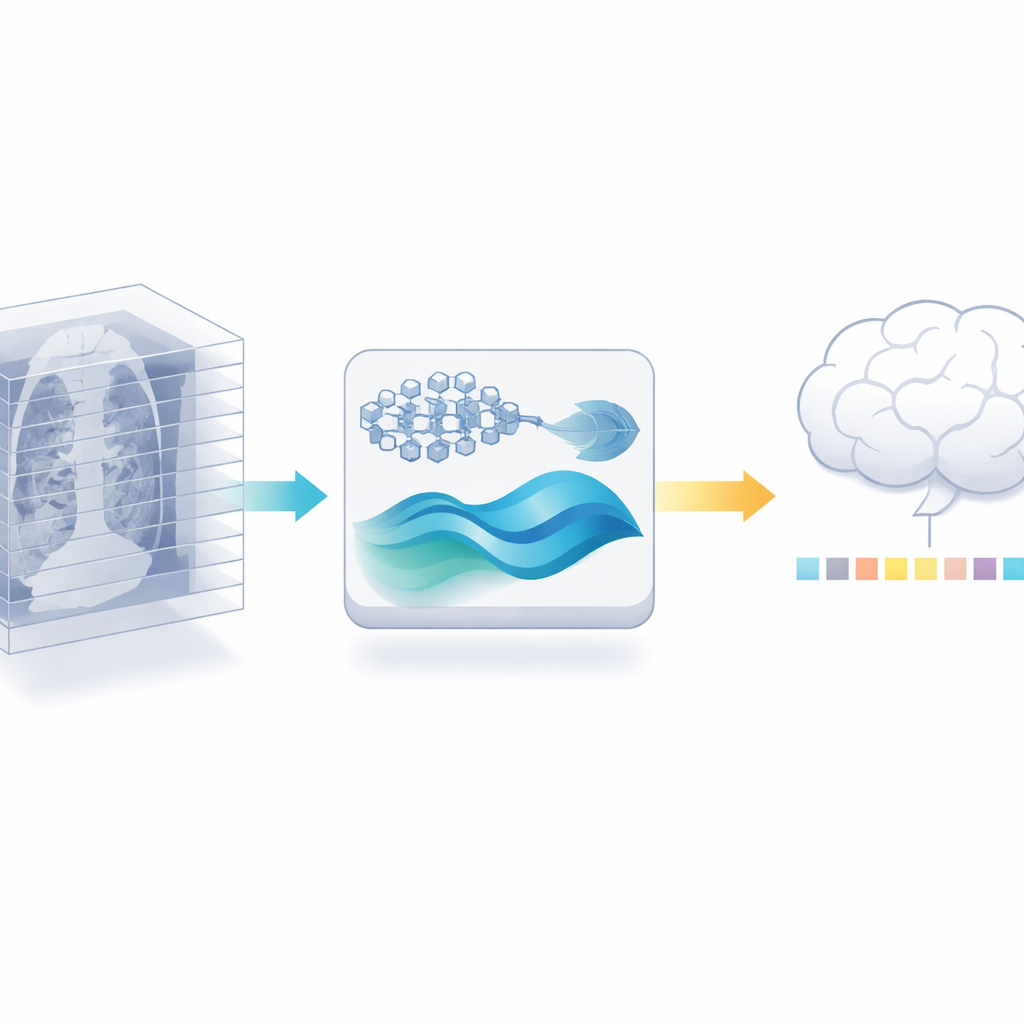
2Dの専門家を3D作業に再利用する
著者らは別の道を提案します:新しい3Dエンコーダを訓練する代わりに、医学文献から数百万枚のラベル付き画像で既に学習済みの強力な2D医用画像モデルを再利用するのです。まず各3Dスキャンを個々のスライスに分割し、この2Dモデルに各スライスから詳細な特徴を抽出させます。次に冗長性を丁寧に削ぎ落とします。スキャン内の隣接スライスはしばしばほとんど同じに見えるため、類似性チェックで多くの近似重複を除外し、最も情報量の多いビューを残します。このステップだけで、後段が扱うデータ量を増やすことなく大幅に削減できます。
断片から3Dの物語を再構築する
トリミングの後、システムは残ったスライスを一貫した3D像に「つなぎ直す」必要があります。著者らはこれを、データの互補的な二つの見方を組み合わせることで実現します。一方の経路は局所的な形状やエッジに注目し、ボリューム内を移動する拡大鏡のように鋭い境界やテクスチャに敏感です。もう一方はデータを周波数領域に変換し、スライス間にまたがる広範なパターンや長距離構造、例えば腫瘍の伸び方や臓器の全体形状を捉えやすくします。適応的な融合ステップが各点でどちらをどれだけ信用するかを学習し、細部と全体文脈の両方を尊重する表現を得ます。これらはすべて2Dスライスから出発しているにもかかわらずです。
微小な手がかりを残して圧縮する
質問に答えたり報告を書く大規模言語モデルと連携するために、視覚情報は限られた数のトークン(「視覚単語」)に圧縮される必要があります。単純に縮小すると、診断で重要な小さな石灰化や微妙なテクスチャ変化といった微小だが重要な信号がぼやけてしまいます。これを避けるために、著者らは二重トラックの表現を作ります:一方は詳細に富む高解像度版、もう一方はより小さくコストの低い版です。注意機構により、小さい方の各点が選択的に高解像度版を「参照」して最も鋭い詳細を取り込むことができます。その結果、放射線科医が重視する手がかりを保ちながらコンパクトな視覚的要約が得られ、それが次に言語モデルへ渡され推論に使われます。
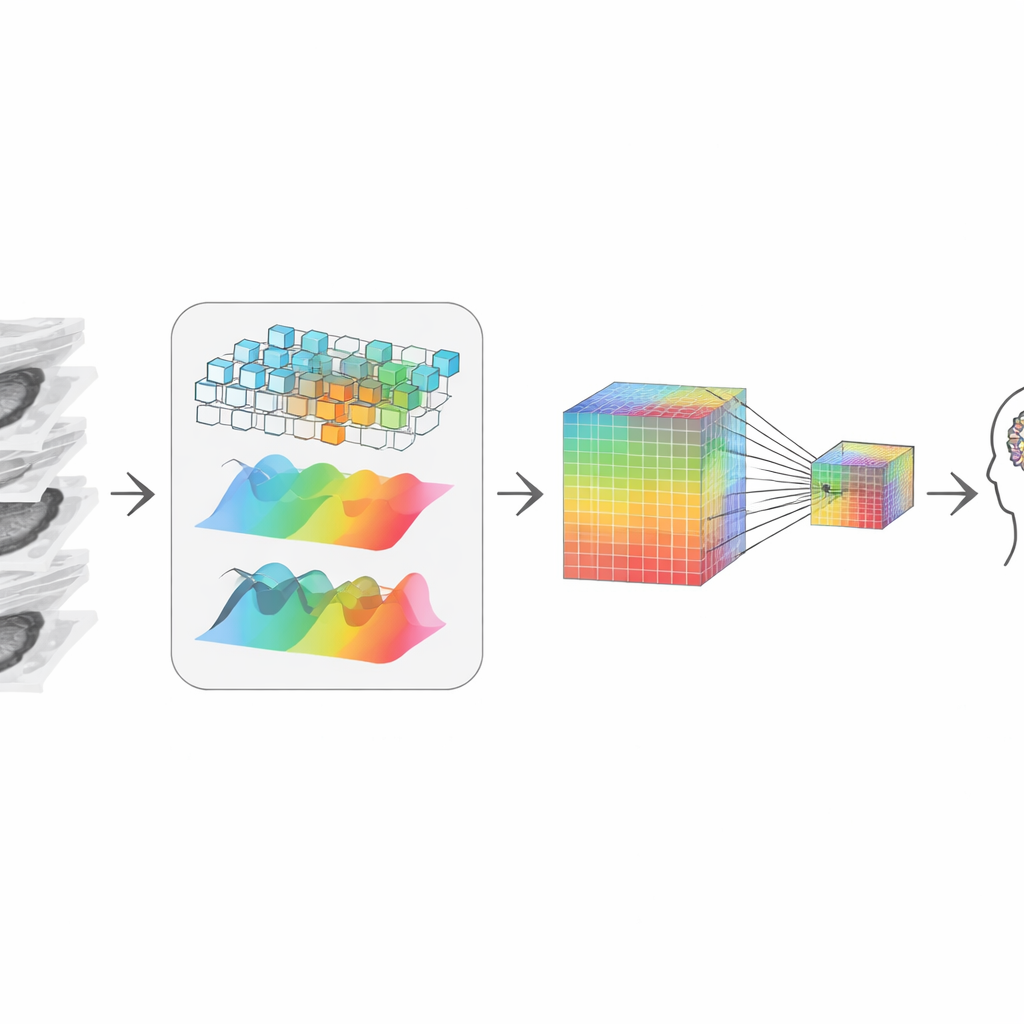
実際の医療タスクでの実証
設計を検証するため、研究者らは公開の3Dベンチマークで評価を行いました。そこで問われる主な点は二つ:システムは3Dスキャンについて放射線科風の正確な記述を生成できるか、そして可視なものに関する質問に答えられるか、です。3D専用のエンコーダを一度も学習させていないにもかかわらず、彼らのアプローチは両方のタスクで複数の優れた3Dベースモデルを上回りました。より精密で臨床的に豊かな報告を生成し、臓器や異常、位置に関する難しい質問にもより正確に答えました。さらに処理は高速で必要とする3D訓練データは格段に少なく、MRIやPETなど異なるスキャン種別にもよく一般化しました。
今後の医療にとっての意義
日常的な観点から見ると、本研究は体積スキャンについて高品質なAI支援を得るためにデータを大量に消費する3Dモデルを最初から用意する必要はないことを示しています。強力な2Dの専門家を賢く再利用し、情報量の高いスライスを注意深く選び、微細な詳細を保持しながら3D像を再構築することで、著者らははるかに少ないデータと計算で最先端の性能を達成しました。広く採用されれば、この種のアプローチは、より良い報告、明確な説明、信頼性の高いトリアージなどの高度なAI支援を、大規模なデータ資源を持たない病院や診療所にも届くようにし、洗練された画像解析を日常診療に近づける可能性があります。
引用: Lian, Y., Xie, Y., Jiang, Y. et al. A data-efficient 3D medical vision-language model using only a 2D encoder. Sci Rep 16, 8809 (2026). https://doi.org/10.1038/s41598-026-39526-z
キーワード: 3D医療画像, ビジョン・ランゲージモデル, 放射線科向けAI, データ効率の高い学習, CTおよびMRI解析