Clear Sky Science · ja
CGDFNet: コンテキスト誘導型ディテール融合を備えた二重分岐リアルタイム意味セグメンテーションネットワーク
車に通り全体を見せることを教える
現代の自動車やロボットは、道路、歩道、人、車両、標識などをリアルタイムで把握するためにカメラにますます依存しています。本論文は、特に混雑した都市の通りでこの種の「シーン理解」をより高速かつ高精度に行うために設計された新しいコンピュータビジョンシステム、CGDFNet を紹介します。交通信号の支柱や自転車の車輪のような細部と、道路や建物のような大局的な構図の両方を同時に重視することを学習することで、CGDFNet は自動運転やその他のリアルタイム視覚タスクをより安全で信頼できるものにすることを目指します。
画素レベルの視覚がこれほど要求の高い理由
意味セグメンテーションでは、画像中の各画素に対してカテゴリ(道路、車、歩行者、空など)を割り当てます。これは単に車にボックスを描くよりもはるかに要求が高く、システムは物体の境界や小さな形状を高精度にたどる必要があります。高精度な手法は多く存在しますが、一般に遅く消費電力が大きいため、車両やドローン、ウェアラブル機器のリアルタイムシステムには不向きです。一方で高速に動作する軽量な手法は、多くの場合、細部を犠牲にしたり広いシーンを見失ったりして、小さな物体や細い構造、混雑した都市環境で苦戦します。
二つの道筋:ディテールのための枝とコンテクストのための枝
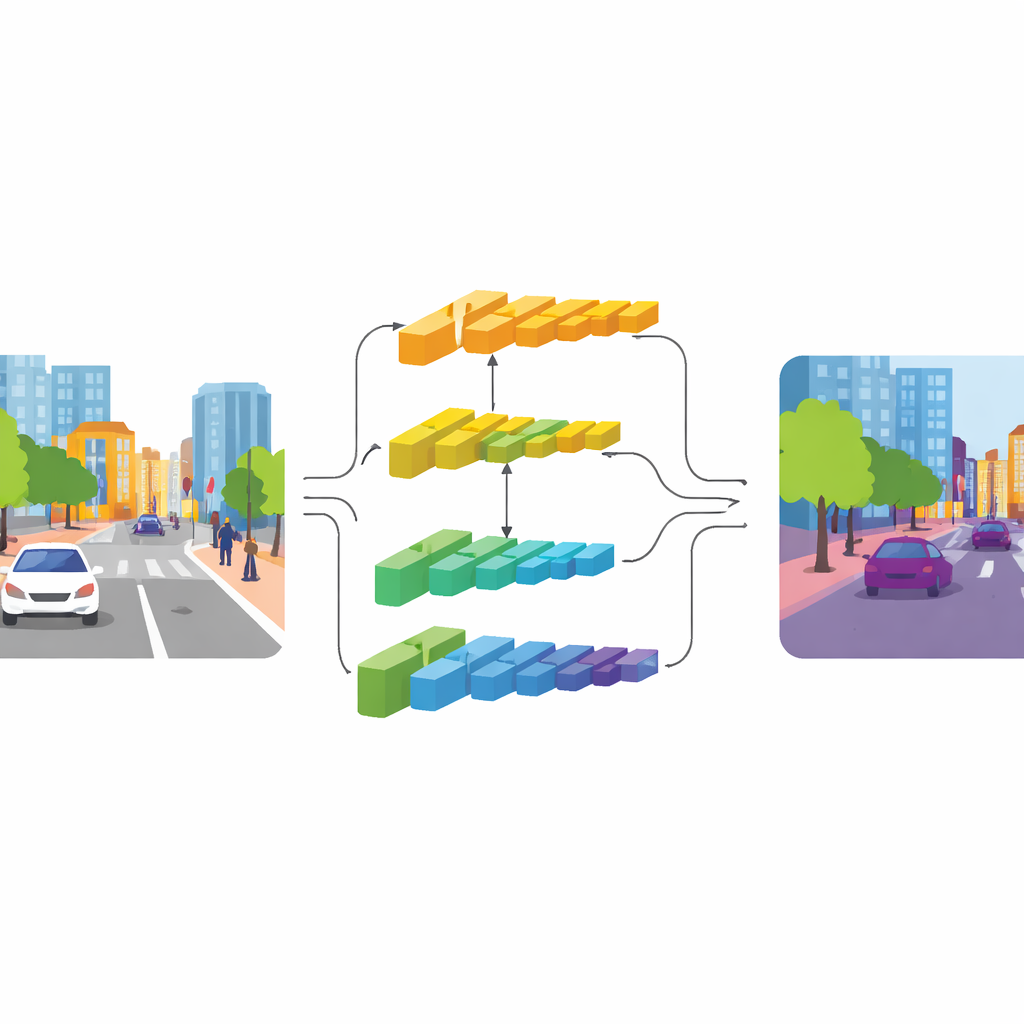
CGDFNet はこの緊張関係に二重分岐設計で対処します。一方の枝は鮮明なディテールに焦点を当て、もう一方の枝は広いコンテクストを捉えます。効率的なバックボーンネットワークを基盤に、低層は高解像度を保ってエッジやテクスチャを保持する「ディテール枝」へ供給されます。深い層はより圧縮された形でシーンを俯瞰する「コンテクスト枝」へ供給され、全体構造や物体間の関係を理解するのに適しています。従来の二重枝設計がこれらの流れをほとんど切り離したまま単純に足し合わせるのと異なり、CGDFNet は処理の全体で両者が相互にやり取りすることを促進し、細部が常に全体像と照らし合わせて検証されるようにします。
意味でディテールを導く
この相互作用を強化する2つの主要コンポーネントがあります。コンテクスト枝では、セマンティックリファインメントモジュールが特徴マップの中で最も情報量の多い領域とチャネルを強調することを学習します。これは局所的な手がかり(どの部分が近傍で活性化しているか)とグローバルな手がかり(画像全体でネットワークが何を見ているか)を組み合わせることで実現され、表現には近傍の詳細とシーンレベルの意味が共に含まれます。ディテール枝では、コンテクスト枝からのセマンティック情報を用いて、バスの輪郭や自転車のフレームなど重要なエッジや細い構造に注意を向けるコンテキスト誘導ディテールモジュールが働きます。これは隣接画素間の変化に敏感な特別な畳み込みに依存しており、パラメータを大きく増やすことなく輪郭や小物体を自然に強調します。
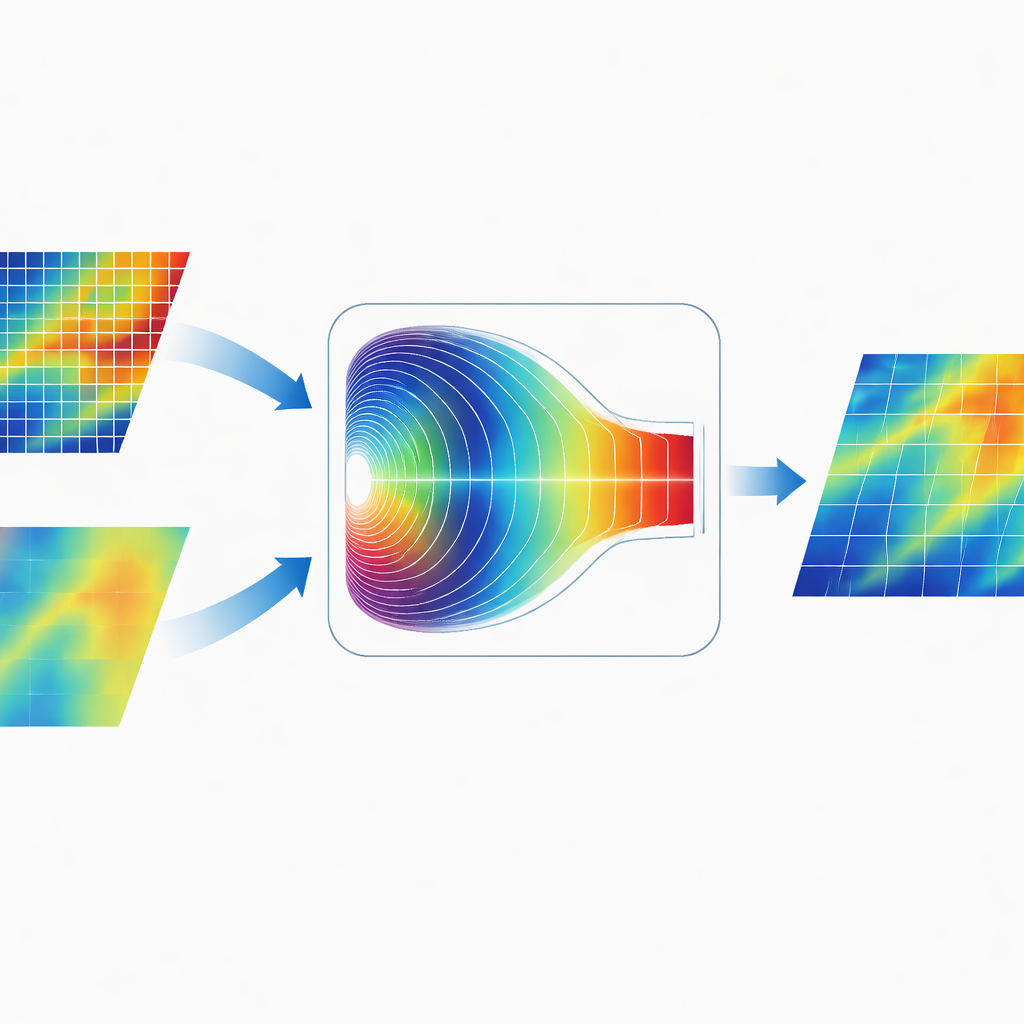
周波数領域で情報をブレンドする
CGDFNet の特徴的な点は、両枝の融合方法にあります。単純に画像空間でマップを加算する代わりに、著者らはフーリエ領域適応融合モジュールを設計しました。このモジュールは結合された特徴を一時的に周波数領域に変換し、そこでパターンは緩やかな広がり(低周波)や鋭い変化(高周波)として表現されます。適応ゲーティング機構がどの周波数成分をディテール枝から強調し、どれをコンテクスト枝から強調するかを学習します。この重み付けの後、特徴は再び空間に戻され、従来の空間領域のみの融合よりも鮮明なエッジと一貫したグローバル構造を効果的に結び付けた表現が得られます。
実際の道路での結果
研究チームは CGDFNet を都市走行シーンの広く使われるベンチマーク、欧州の都市から収集された Cityscapes と英国の運転者視点で取得された CamVid で評価しました。CGDFNet は大きな画像をリアルタイム速度で処理し、Cityscapes で約88フレーム毎秒、CamVid で約129フレーム毎秒を達成しつつ、多くの最先端システムに匹敵またはそれを上回るセグメンテーション精度を示しました。境界や小さな構造の保持が重要なフェンス、交通標識、バス、自転車などのカテゴリで特に良好な性能を発揮しました。
日常技術にとっての意義
実用的に見れば、CGDFNet はリアルタイム使用に十分な高速性と、複雑な都市シーンにおける安全性に関わる小さなディテールを尊重する慎重さの両立が可能であることを示しています。ディテール重視の枝、コンテクスト重視の枝、そして周波数領域における賢い融合ステップを組み合わせることで、ネットワークは通りをバランスよく把握します:各物体がどこにあり、どこで始まり終わるかを知るのです。密集した群衆や悪天候など課題は残るものの、このアプローチは自動運転車からスマート交通カメラ、支援ロボットに至るまで、将来のオンデバイス視覚のための有望な青写真を提供します。
引用: Zhao, S., Fu, W., Gao, J. et al. CGDFNet: a dual-branch real-time semantic segmentation network with context-guided detail fusion. Sci Rep 16, 9191 (2026). https://doi.org/10.1038/s41598-026-39370-1
キーワード: リアルタイム意味セグメンテーション, 自動運転視覚, 二重分岐ニューラルネットワーク, フーリエ基盤の特徴融合, 都市シーン理解