Clear Sky Science · ja
スケルトン運動のトポロジーマスク予測とコントラスト学習による自己教師あり人間行動認識
身体言語をコンピュータに読ませる
ビデオドアベルからスマートなリハビリツールまで、多くの現代システムは人の動きだけを見て何をしているかを理解する必要があります。しかし、コンピュータに人間の行動を認識させるには、通常、波や蹴り、握手といった動作が手で注釈された膨大で精緻なラベル付きデータセットが必要です。本研究は、ラベルなしの生の運動データ、すなわち身体の動くスケルトンだけを用いて機械が学習する方法を提示します。顔やフルカラー映像を使わずに、ラベルを必要としないため、行動認識をより高精度でプライバシー配慮しつつ、人的注釈への依存を大幅に減らせます。
なぜスケルトンだけで十分なのか
本手法はフレーム全体の映像を解析する代わりに、肩、肘、股関節、膝など主要関節の時系列座標からなる3Dスケルトンデータを扱います。この簡潔な身体表現にはいくつか利点があります。顔や衣服が除かれるためプライバシー問題を大幅に回避でき、長時間の記録でも効率的に処理できるほどデータがコンパクトです。さらに、背景の雑音や照明変化に強く、通常の映像ベースのシステムが混乱する場面でも堅牢です。しかし、多くの既存のスケルトンベース手法は依然としてラベル付き例に大きく依存しており、関節がどのように協調して動くかを完全には捉えられていません。
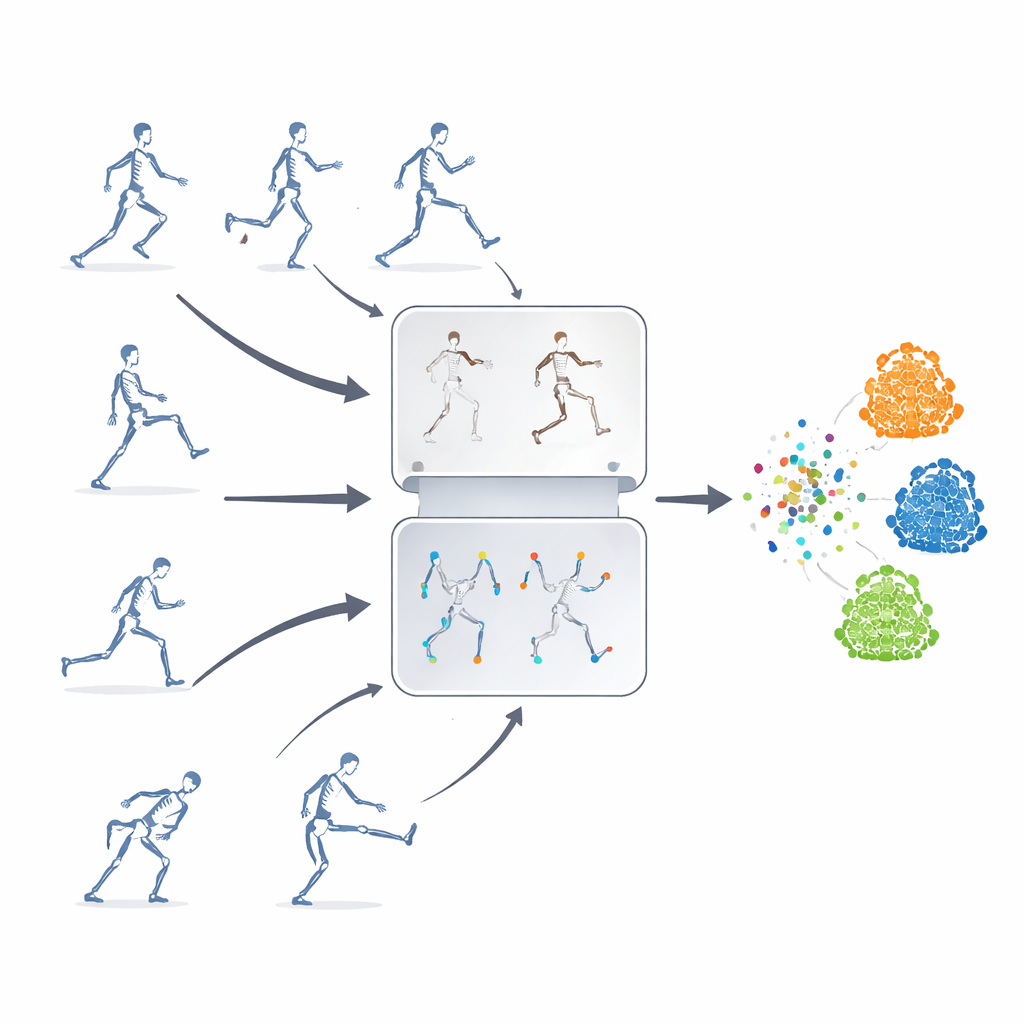
ラベルなしで学ぶ
著者らは自己教師あり学習の枠組みを提案しています。これは、システムがラベルのないスケルトン系列から自ら学ぶことを意味します。主要なアイデアは、通常は別々に使われる二つの強力な手法を組み合わせることです。一つは「マスク予測」で、スケルトンデータの一部を意図的に隠し、残りの文脈から欠損した動作を推定させます。もう一つは「コントラスト学習」で、同じ動作の複数の変形バージョンを示して、それらが根底にある同一の動きであることを学習させます。これらを組み合わせることで、関節運動の細部と行動の大局的な意味の両方を同時に学べます。
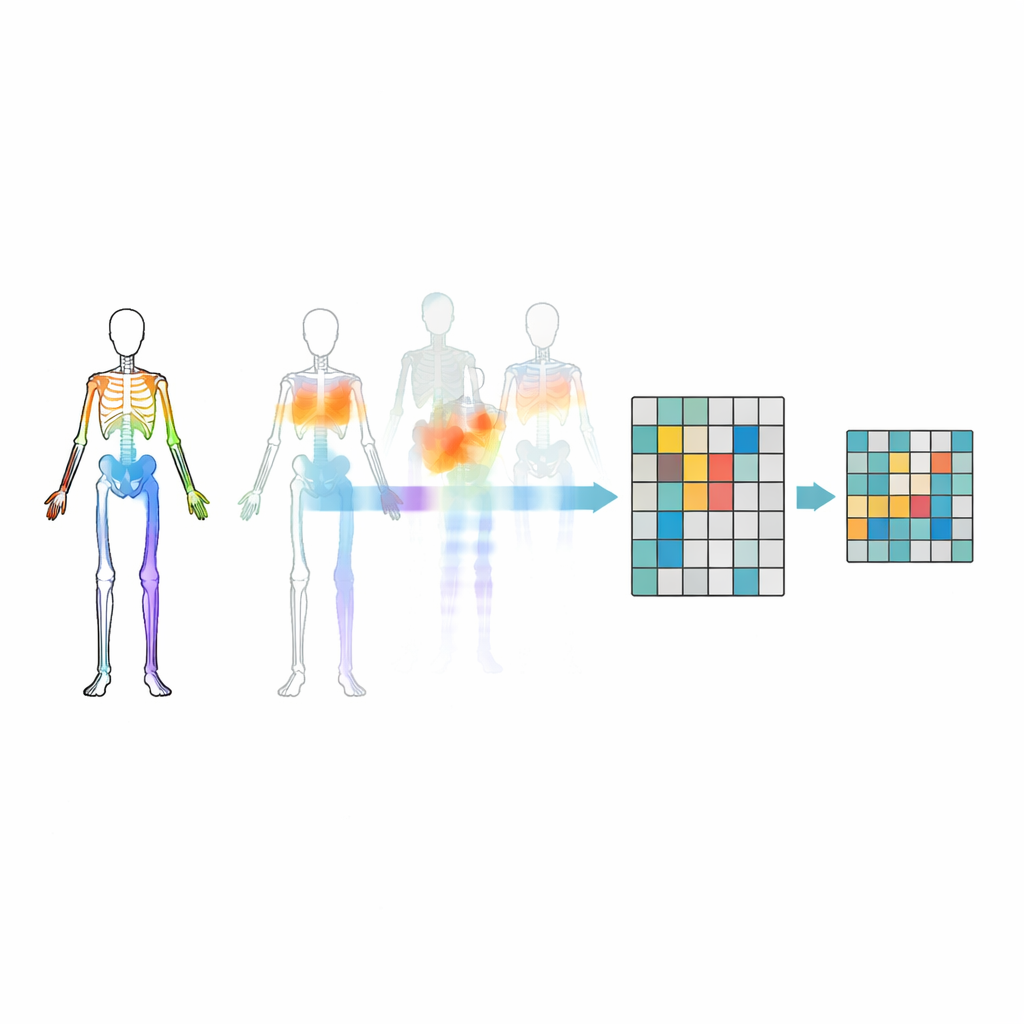
適切な関節を隠す
単にランダムに関節をマスクするだけでは不十分です。モデルが身体部位間の重要な関係を無視したり、最も目立つ動きに固執してしまう恐れがあります。そこで研究者たちは運動–トポロジーマスキング戦略を導入しました。関節を腕、脚、胴幹といった意味のある領域にグループ化し、各領域が時間を通じてどれだけ強く動くかを測定します。マスクの決定は身体の構造と各領域の運動量の両方に基づいて行われ、時には非常に活発な部分を隠してモデルに残りの部分からそれらを推定させます。この標的型の隠蔽により、モデルは派手な動きを丸暗記するのではなく、行動中に関節がどのように協働するかを学習します。
動作を多様に伸ばす
コントラスト学習の部分を訓練するために、同じ元のスケルトン系列を多数の「ビュー」に変換します。時間窓のクロップや軌跡のわずかな歪みなど穏やかな変化から、反転、回転、強めのノイズといったより極端な変換まで含まれます。こうした多段階の増強は、モデルに多様な運動パターンを曝露し、表面的な細部よりも行動の核となる構造に注目するよう促します。同時に、軌跡誘導の特徴ドロップモジュールがモデルが最も頼っている運動特徴を追跡し、それらを意図的に抑制します。いわば“お気に入りの手がかり”を一時的に取り除くことで、モデルは補助的な手がかりを発見し、より一般化可能な表現を学ぶよう促されます。
どの程度うまくいくか
この枠組みは、日常行動、医療関連の動作、人同士の相互作用を含む三つの大規模公開3D人間行動ベンチマークで評価されました。スケルトン関節データのみと比較的軽量な再帰型ニューラルネットワークを用いるにもかかわらず、本手法はより複雑な入力やアーキテクチャに依存する多くの最先端システムと匹敵するか上回る性能を示しました。特に注釈が乏しい場合や一部の身体部位が遮蔽される状況では強みを発揮し、現実世界で頻出する条件に対して有利です。異種データセット間での知識転移能力にはまだ改善の余地がありますが、ラベルあり学習とラベルなし学習の差を大きく縮めることに成功しています。
実世界のシステムにとっての意義
専門外の読者にとっての結論は、本研究がコンピュータに人の身体言語を、すべての動作の意味を逐一教えなくてもはるかにうまく読み取らせる方法を示したことです。訓練時にスケルトンデータを賢く隠し、歪めることで、モデルは照明や視覚的雑音、欠損関節の下でも有効な堅牢な動作パターンを学び、必要な人的ラベルを大幅に削減できます。これにより、家庭内モニタリングやスポーツ指導、医療リハビリ、人間–ロボット相互作用など、よりプライバシーに配慮したスケーラブルで適応可能な行動認識システムの実用化が進む可能性があります。
引用: Hui, Y., Li, F., Hu, X. et al. Skeleton motion topology-masked prediction and contrastive learning for self-supervised human action recognition. Sci Rep 16, 8100 (2026). https://doi.org/10.1038/s41598-026-39330-9
キーワード: 人間行動認識, 3Dスケルトンデータ, 自己教師あり学習, コントラスト学習, 運動解析