Clear Sky Science · ja
ビデオベースの人物再識別のためのマルチレベル集約を備えたCNN-RNN Siamese フレームワーク
カメラ間で人を追跡することが重要な理由
現代の都市は多数のカメラで覆われていますが、それらのカメラが互いに「連携」することは稀です。人物が路地から駅へ移動すると、各カメラは異なる角度や照明、しばしば群衆越しに同じ人を捉えます。異なるビデオクリップに写る人物が同一人物であるかを自動的に識別すること(ビデオベースの人物再識別)は、事件後の移動経路の追跡、行方不明者捜索の支援、混雑する公共空間での解析などに役立ちます。しかし、特に限られたハードウェア上で正確かつ効率的にこれを行うことは大きな技術的課題です。
動く人物を照合するためのよりシンプルな“脳”
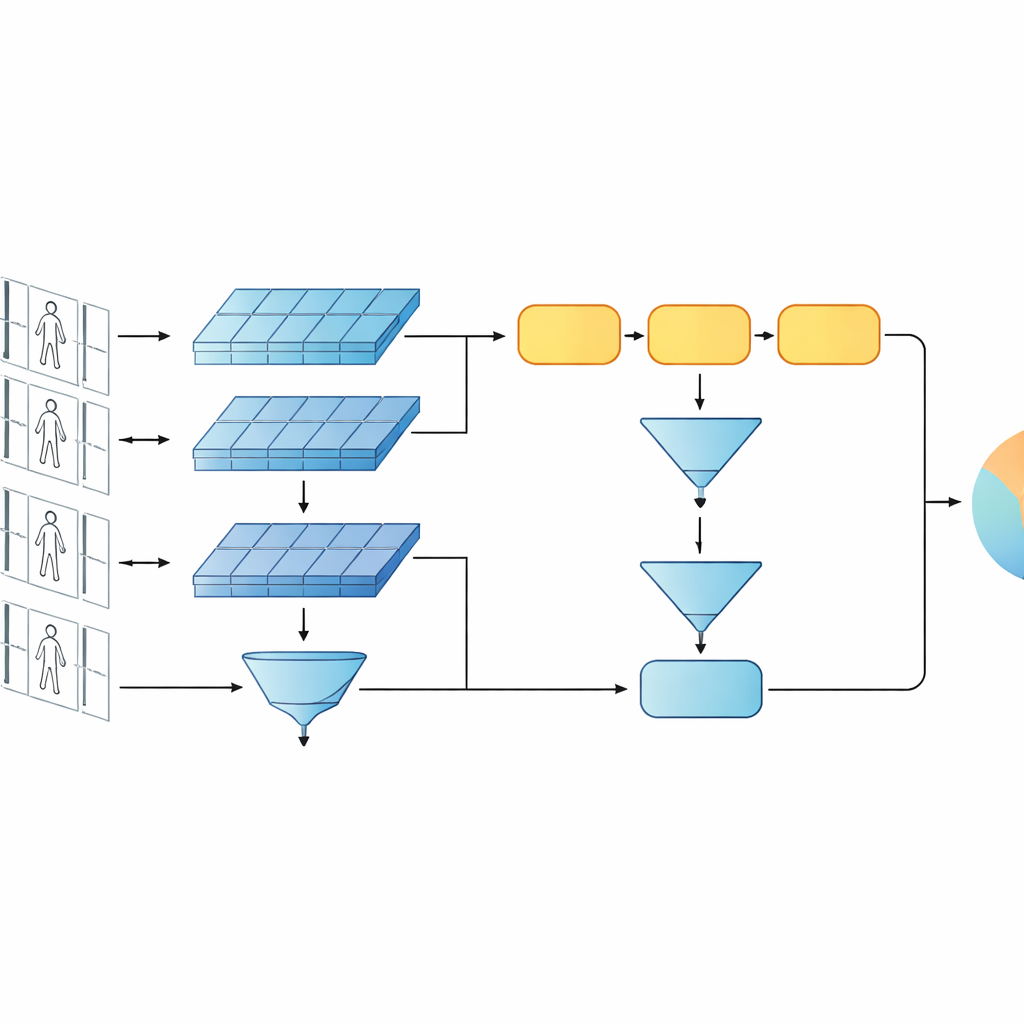
本研究は、2つの短いビデオクリップが同一人物を写しているかを判別するために設計されたコンパクトな人工知能システムを提案します。非常に深いネットワークやトランスフォーマーベースの最近の流行に従うのではなく、著者らはもっと簡潔な設計を採用しています。フレームごとに映像を解析する畳み込みネットワーク(CNN)と、外観の時間的変化を追うゲート付き再帰ユニット(GRU)という2つの古典的要素を組み合わせています。これらの2つの枝はSiamese(双子)構成で配され、内部の設定を共有する同一のネットワークが二つ並びます。各ネットワークは一方のビデオ系列を処理し、システムは同一人物のクリップには類似した内部表現を、異なる人物のクリップには明確に異なる表現を出すよう学習します。
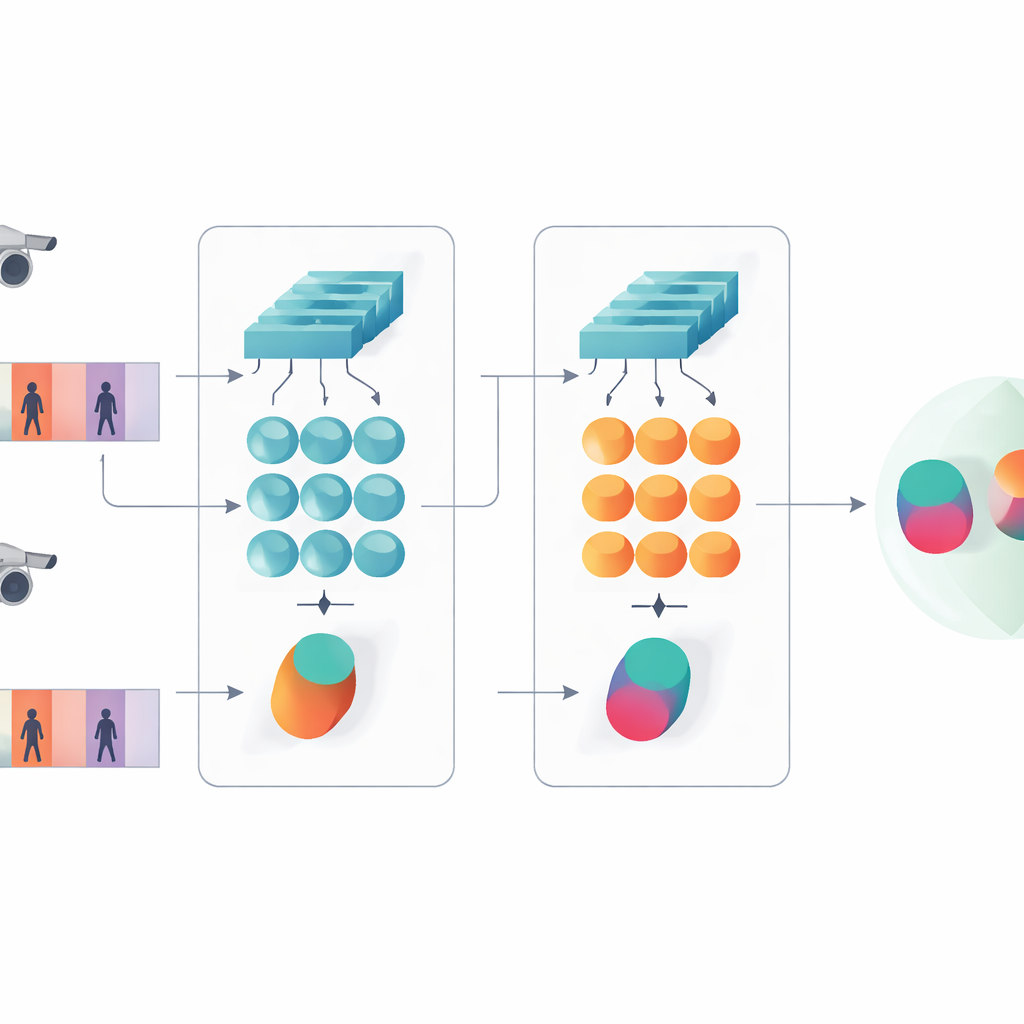
細部と時間的パターンの両方を捉える
本研究の重要な考え方は、認識がネットワークの最も深い抽象特徴だけに依存すべきではないという点です。初期層にはジャケットの織り目、ズボンのストライプ、バックパックの輪郭など、カメラ角度の変化にも耐える鮮明な視覚的手がかりが残っています。提案モデルはそのために二重の記述レベルを保持します。1つの枝は初期層の特徴を全フレームにわたってプーリングし、細かなテクスチャや局所的パターンを要約します。もう1つの枝は後期の特徴をGRUに入力し、フレームごとに系列を追跡した後に内部状態を時間平均します。この平均化により最後の数フレームに過度に依存することを避け、クリップ全体を通した外観と動きの合意的な表現を捉えます。
双子ネットワークを同意させ、分類させる訓練
システムに重要なことを学習させるために、著者らは二つの訓練目的を組み合わせます。まず検証(ベリフィケーション)目的は、同一人物の動画に対しては双子の枝が近い表現を、異なる人物には遠い表現を出すよう促します。次に分類目的は、各訓練クリップを特定の識別子に割り当てることをネットワークに求めます。低レベルと高レベルの両方で同時に最適化することで、モデルは人物間で差別的であると同時に雑音や遮蔽、時折の低品質フレームに対して頑健な内部表現を学びます。層数とパラメータは浅めに保たれており、比較的小さなビデオデータセットでの過学習を避けるのに役立ちます。
実際の監視風ビデオでの検証
このフレームワークは、PRID-2011とiLIDS-VIDという広く使われる二つのビデオベンチマークで評価されます。これらは、それぞれ異なるカメラ対から撮影された数百人分の短い歩行シーケンスを含みます。研究ではGRUを他の再帰ユニットに置き換えた場合、再帰層の数の変更、特徴の時間的プーリング方法の変更、低・高レベル枝のオン/オフといった異なる設計選択を注意深く検証します。これらのテストを通じて、単層GRUと平均プーリング、およびマルチレベル構成の組合せが一貫して最良の精度を示しました。本モデルは多くのより複雑な再帰型やSiameseシステムに匹敵またはそれを上回り、注意機構を使った設計と比べても競争力がありながら、はるかに少ないパラメータと計算量で動作します。
現実世界での展開に向けた効率性
精度に加えて、本研究は実用性を重視します。ネットワーク全体の学習可能パラメータはおよそ100万〜200万程度で、人気のある深い残差ネットワークやトランスフォーマーベースのバックボーンより桁違いに少なく、フレームあたりの計算コストもそれらのごく一部にとどまります。これにより、カメラ近傍のエッジサーバなど、メモリや処理能力が限られたデバイスへの配備に適しています。実験はまた、ギャラリーのシーケンスを長くして保存されている各人物のフレーム数を増やすと認識率が大幅に向上することを示していますが、その分処理コストは線形に増加します。著者らは、このようなコンパクトで注意深く設計されたアーキテクチャが、今日の大規模モデルの高コストを伴わずに信頼性の高い人物再識別を提供できると主張します。
日常的な監視システムにとっての意味
平たく言えば、本論文は「賢い設計は単に大きなモデルに勝ることがある」ことを示しています。浅めの画像解析、軽量な系列モデリング、視覚類似性の二重レベルの統合により、モデルを小さく高速に保ちながらカメラ間で誰が誰であるかを高い信頼性で追跡できます。多くのカメラ上で稼働し、しばしば厳しいハードウェアやエネルギー制約を抱える将来のシステムにとって、この種の効率的でマルチレベルなアプローチは、より高度で責任あるビデオ解析の現実的な導入を後押しする可能性があります。
引用: Wang, YK., Pan, TM. & Sun, CP. A CNN-RNN Siamese framework with multi-level aggregation for video-based person re-identification. Sci Rep 16, 8224 (2026). https://doi.org/10.1038/s41598-026-39277-x
キーワード: 人物再識別, ビデオ監視, Siamese ニューラルネットワーク, 時間的モデリング, 効率的な深層学習