Clear Sky Science · ja
LLMに基づく動的戦略を備えた頑健な自然言語テキスト→SQL生成フレームワーク
日常の疑問をデータベースの答えに変える
現代の組織はデータにあふれていますが、大半の人はそれを照会するための専門的な言語を扱えません。本稿はTriSQLを紹介します。TriSQLはユーザーが平易な言葉で質問すると、それを正確なデータベースコマンドに自動変換するシステムです。大規模言語モデルが扱う複雑さを慎重に管理することで、このフレームワークは最も難しい質問に対しても、データアクセスをより正確かつ信頼できるものにすることを目指しています。
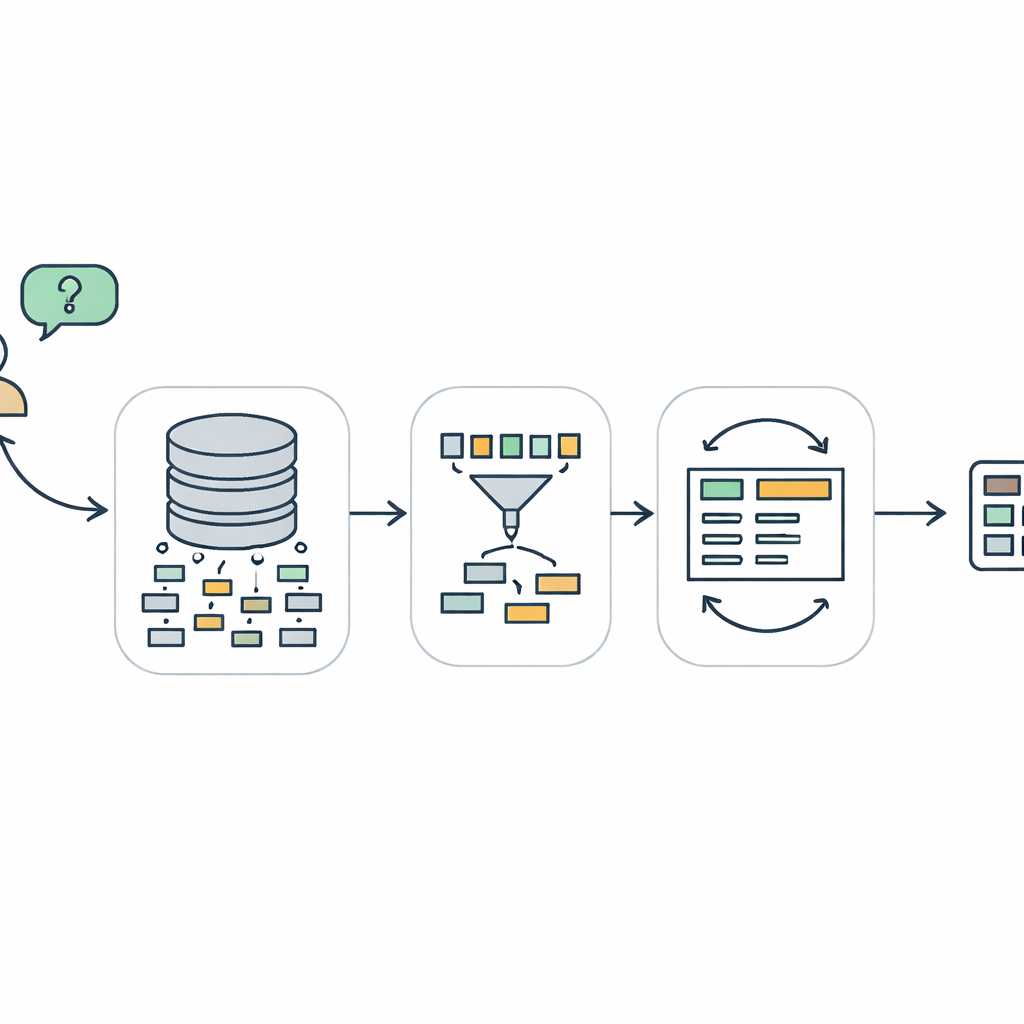
なぜデータベースと話すのは難しいのか
「先月5点以上購入した顧客は誰ですか?」のような質問を入力すると、コンピュータはそれを多くのデータベースで使われる専門言語であるSQLに翻訳しなければなりません。このタスクはtext-to-SQLと呼ばれ、一見単純ですが意外に困難です。システムはユーザーの意図を理解し、時に巨大で散逸したスキーマの中から適切なテーブルと列を見つけ出し、構文的に正しくかつ元の意図に忠実なクエリを構築する必要があります。従来のシステムや大規模言語モデルを活用した手法は、多数のテーブル結合、入れ子の論理、微妙な条件を含む質問でしばしば失敗します。見た目は正しそうなクエリを生成しても、実行できなかったり、実行しても誤った結果を返したりすることがあります。
質問からクエリへの三段階の道筋
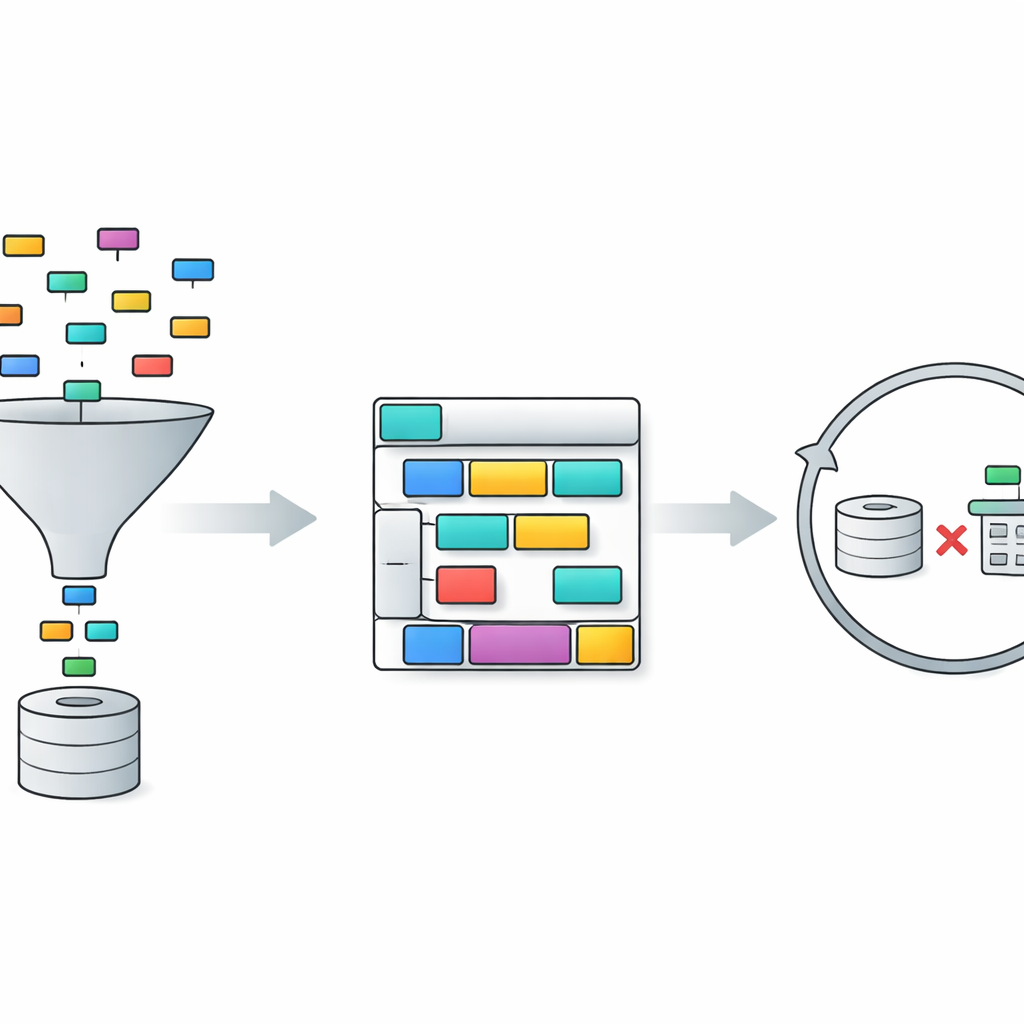
TriSQLは三段階のパイプラインでこれらの問題に対処します。まず、質問依存のセレクタがユーザーの言葉とデータベース全体の構造を検討し、本当に関連するテーブルと列を決定します。スキーマ全体をむやみに言語モデルに見せるのではなく、重要な部分だけに視点を絞ります。次に、構造認識型ジェネレータが詳細を埋める前にSQLクエリの形を設計します。まず高レベルのスケルトン—どの句が必要でそれらがどう組み合わさるか—を描き、その後に具体的なテーブル、結合、条件を挿入します。「構造を先に、内容を後にする」このアプローチは、特に長く複雑なクエリにおいてSQLの厳格な文法を守るのに役立ちます。最後に、複雑度認識型のリファイナが初期クエリを検査・改善し、質問の難易度に応じた異なる戦略を適用します。
質問の難易度に応じて工数を調整する
リファイン段階はTriSQLが大規模言語モデルを特に新規に活用する部分です。システムは各質問と下書きクエリの複雑さを、結合されるテーブル数、入れ子の深さ、使用される制約の種類などの要素を考慮してスコア化します。単純なケースでは軽微な修正(小さな文法ミスの訂正など)だけを適用します。中程度のケースでは句の再編成やクエリと選択されたスキーマの整合性のチェックを行います。最も難しい質問では、より深い推論のために言語モデルを呼び出し、問題をサブタスクに分解したり代替クエリを試行したりします。重要なのは、TriSQLが元のクエリとリファイン後のクエリの両方をデータベース上で実行し、それらの挙動—実行できるか、実行時間、返される結果—に基づいてどちらを採用するか、あるいはさらに別のリファインを試みるかを決定する点です。
システムの試験運用
TriSQLの性能を評価するために、著者らは広く用いられるベンチマークであるSpiderや、ドメイン知識、奇妙な文型、より現実的なクエリ構造を導入したいくつかの難易度の高い変種でテストを行いました。評価指標は二つで、生成されたSQL文字列が人手で書かれた参照と完全一致するかを確認するexact matchと、実行したときに実際に正しい答えを出すかを確認するexecution accuracyです。これらのデータセット全体で、TriSQLはこれまで報告されている中で最高の実行精度を達成しつつ、exact matchでも最良の既存手法に競争力のある成績を示しました。さらに堅牢性も高く、質問の難易度が易しいから極めて難しいへ移るにつれて、TriSQLの性能低下は競合手法に比べてずっと緩やかです。実世界の送電網管理データセット上の追加実験では、このフレームワークが単なるデータ取得だけでなく、挿入、更新、削除、テーブル作成コマンドにも対応できることが示されました。グラフデータベース(Cypher)やMongoDBパイプラインへの試験的な適用も、三段階設計が古典的なSQLの枠を超えて拡張可能であることを示唆しています。
日常のデータ利用にとっての意義
平易に言えば、この研究は人々が今や検索エンジンと気軽にやり取りするのと同じように、複雑なデータベースと対話できる世界に一歩近づけます。データベースのどの部分に注目するかを慎重に選び、詳細を埋める前にクエリの構造を計画し、各質問の難易度に応じて大規模言語モデルの利用を調整することで、TriSQLは実行されやすく意図した結果を返す可能性の高いクエリを生成します。曖昧な質問や未知のデータベースに対処するなど課題は残りますが、本研究は段階的で考え抜かれた設計が自然言語によるデータインターフェースを、日常の利用者にとってより強力で予測可能なものにし得ることを示しています。
引用: Su, X., Gu, Y., Wang, P. et al. A robust natural language text-to-SQL generation framework with dynamic strategies based on LLMs. Sci Rep 16, 7892 (2026). https://doi.org/10.1038/s41598-026-39128-9
キーワード: text-to-SQL, 自然言語インターフェース, データベース照会, 大規模言語モデル, クエリの頑健性