Clear Sky Science · ja
境界の移動で不均衡データを処理する手法
日常データで希少事例が重要な理由
銀行の不正や医療診断から顧客の離脱予測まで、コンピュータに任せる多くの判断は、まれだが重要な事象を見つけ出すことにかかっています。現実のデータセットでは、こうした重要な事例は通常の事例に比べて圧倒的に少数です。「通常通り」の事例ばかりを学習したモデルは、最も気にすべき状況に対して盲目になりかねません。本稿は、学習アルゴリズムが希少で影響力の大きい事例に適切に注目できるよう、不均衡なデータを再バランスする新しい手法を提示します。
片寄ったデータの隠れた落とし穴
あるタイプの例が他を大幅に上回ると、標準的な機械学習手法は多数派に注力し、少数派を静かに無視する傾向があります。例えば離脱予測システムは、実際の離脱者が極めて少ないためにほとんどの人を「継続する顧客」とラベル付けしても高精度を示せます。事故検出、詐欺監視、医療スクリーニングでも同様の問題が生じ、陽性(重要)事例は稀だが見逃すとコストが大きい。従来の対処法は大きく二つに分かれます:学習アルゴリズム側を少数派を重視するよう調整するか、データ自体を多数派の削減(アンダーサンプリング)や少数派の合成(オーバーサンプリング)で形作り直すかです。SMOTEのような人気のオーバーサンプリング手法は少数派の合成例を生成しますが、クラス間の微妙な境界領域を意図せずに雑然とさせてしまうことがあります。
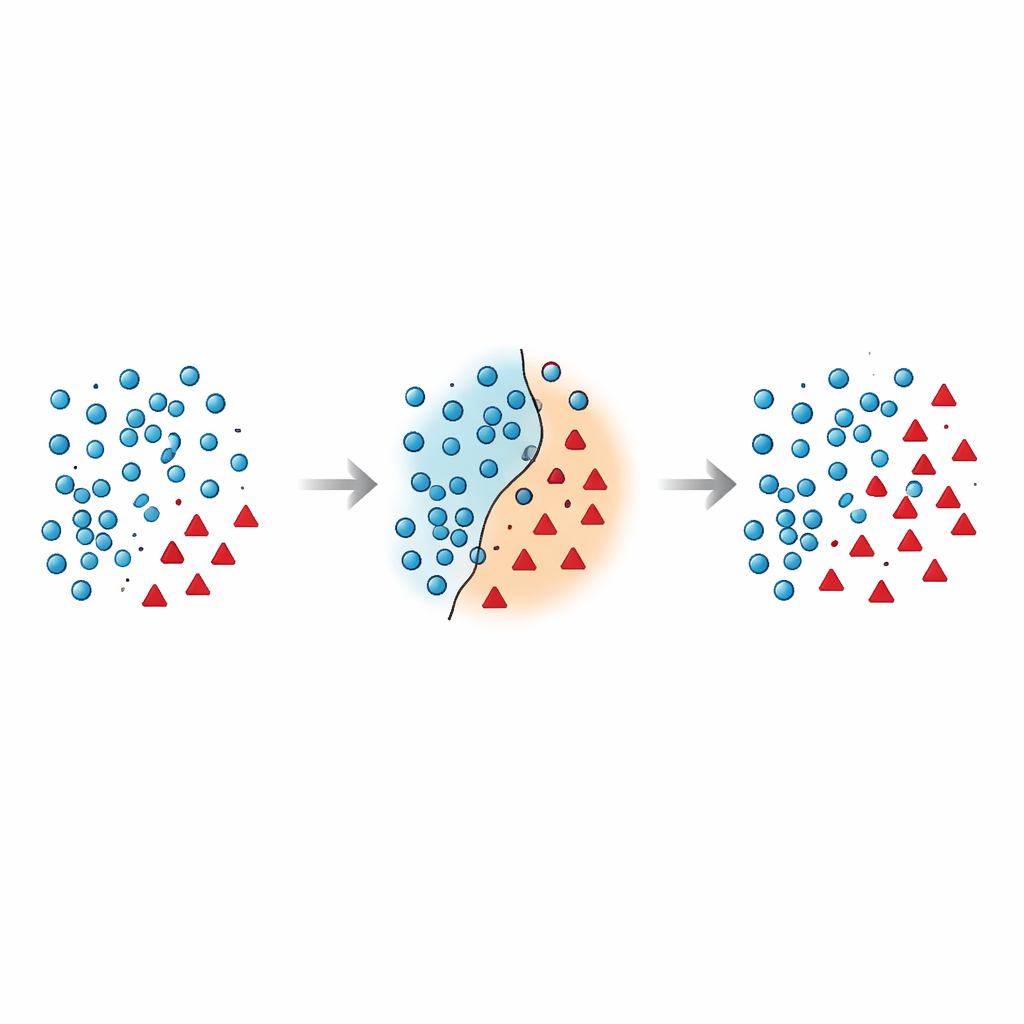
なぜグループ間の境界は脆弱なのか
著者らは、最も危険な誤りは決定境界付近、すなわち特徴空間で多数派と少数派が重なる領域で起きると主張します。既存の手法の多くは、このリスクの高い領域に合成点を追加する一方でそれを整理せず、あるいはデータを過度に削除して有益な例まで失ってしまいます。最近の研究では幾何学的制約や局所密度推定、ノイズ除去フィルタを用いる試みがありましたが、それでも多数派の境界付近の扱いを見直すことは稀です。その結果、分類器を混乱させ新しいデータで不安定な予測を招く重複やノイズの残存という問題が残ります。
境界を整理する二段階の方法
本論文はBorderline Shifting Oversampling(BSO)を導入します。これは問題のある境界領域を明示的に対象とする二段階のデータ再整形法です。まず各多数派サンプルの近隣を走査し、そのサンプルが安全な領域にあるか、境界上にあるか、あるいは明らかな誤り(ノイズ)であるかを判定します。少数派の近傍に囲まれた多数派点は少数側へ再分類されるかノイズとして除去され、結果的に境界を掃除し移動させて基礎的なパターンをより正確に反映させます。第二段階では、洗練された境界周辺の少数派サンプルの周りに限定してSMOTE類似の補間で新しい合成少数サンプルを生成します。最も有益な場所にデータを集中的に追加し、明らかにノイズと思われる箇所を避けることで、BSOはサイズ面でよりバランスが取れ、構造的にもよりクリーンな訓練セットを構築します。
手法の実地検証
実務でどれだけ有効かを確認するために、研究者らは不均衡度や重なりの度合いが異なる30のベンチマークデータセットでBSOを評価しました。比較対象にはランダムなオーバー・アンダーサンプリング、SMOTE、Borderline‑SMOTE、NearMiss、そしてオーバーサンプリングとノイズ除去を組み合わせたSMOTE‑TomekやSMOTE‑ENNといった広く使われる7つの代替手法が含まれます。各リサンプリング後のデータセットに対して、サポートベクターマシン、ナイーブベイズ、ランダムフォレストの3つの代表的な分類器を訓練しました。単純な正解率に頼らず、F1スコア、G‑mean、再現率、適合率、ROC曲線下面積(AUC)といった不均衡下でより情報量のある指標を用いました。ほとんどのデータセットと分類器において、BSOはスコアが高いか同等であり、かつ変動が小さいことが示され、特定モデルや設定に依存しない一貫した利点が確認されました。
実世界の意思決定にとっての意味
日常表現では、Borderline Shiftingアプローチは混乱したデータに対する注意深い編集者のように振る舞います:クラスを分ける境界付近の紛らわしい例を掃除し、その上でちょうど良い場所にだけ現実的な少数派事例を追加します。その結果、学習アルゴリズムはノイズによる誤誘導を受けずに希少だが重要な事象をより正確に認識できるようになります。詐欺検出、事故予測、医療トリアージのように少数事例の見落としがコスト高となる応用において、この手法はモデルをより公平で感度が高く信頼できるものにする実用的な手段を提供します。その際、計算負荷の増加は控えめに抑えられます。
引用: Malhat, M.G., Elsobky, A.M., Keshk, A.E. et al. An approach for handling imbalanced datasets using borderline shifting. Sci Rep 16, 8264 (2026). https://doi.org/10.1038/s41598-026-39118-x
キーワード: クラス不均衡, オーバーサンプリング, 決定境界, 異常検知, 機械学習のロバスト性