Clear Sky Science · ja
大規模言語モデルは多言語ファクトチェックにおいてダニング=クルーガー様の効果を示す
なぜ賢いファクトチェックが誰にとっても重要か
誤情報はこれまでになく速く拡散し、健康、政治、科学、日常生活に関する人々の信念を形作っています。多くのプラットフォームや報道機関は、特に大規模言語モデル(LLM)といった人工知能に、拡散する主張が真実かどうかを検証する手助けを期待し始めています。本研究は一見単純だが極めて重要な問いを投げかけます:これらのシステムに事実を判断させるとき、どれほど正しいか、どれくらいの確信を示すか、そしてそれは言語や地域によって変わるのか?
研究者は実際の噂を使ってどのようにAIを検証したか
著者らは人工的な例を作る代わりに、世界中の専門的なファクトチェック機関が既に調査していた5,000件の実際の主張からテストを構築しました。これらの主張は47言語を網羅し、グローバルノースとグローバルサウスの両方を含み、オンライン上の多文化的で混沌とした現実を反映しています。複数のファクトチェッカーにより合意された「真」または「偽」の明確な評決のみが含まれ、比較のための強固なグラウンドトゥルースが確保されました。
その後、著者らは小規模なオープンソース系から高度な商用モデルまで、広く使われている9つの言語モデルを各主張に対して実行しました。人々が実際にチャットボットとやり取りする様子を反映するために、ほとんどのプロンプトは「これは本当ですか?」や「これは偽ですか?」といった単純な質問で、主張と同じ言語で書かれました。4番目のより専門的な設定では、モデルを仮想ファクトチェッカーに変える詳細な指示を英語で与え、構造化された出力を求めました。人間の注釈者がモデルの回答を注意深く読み、主張を「真」「偽」と判断したか、あるいは明確な評決を拒否したかにラベル付けしました。
正誤だけでなく「わからない」と言うべき時を測る
研究チームは正答・誤答の集計以上のことを行いました。モデルの振る舞いを捉えるために、3つの主要な指標を用いました。まず「選択的精度」は、モデルが実際に立場を示して真偽を宣言した場合にどれだけ正しかったかを見ました。次に「棄権許容精度」は、モデルが推測するよりも不確かさを認めることを受け入れられる、むしろ望ましい行動として扱うもので、医療や選挙のような敏感な領域で重要です。三つ目の「確定率」は、モデルがどれだけの頻度で明確な回答を与えたかを追跡し、モデルの振る舞い上の自信の粗い代替指標となります。
ステップごとの指示を含む専門的スタイルのプロンプトは、すべてのモデルで一貫して精度を高めました。しかしそれはトレードオフも明らかにしました:小さなモデルはしばしば決定的になったものの信頼性は上がらず、一方で大きなモデルはその構造を利用して回答の数を減らしつつも質の高い回答を出すようになりました。日常的なチャット風のプロンプトは特に弱いモデルでより慎重な挙動を生みましたが、同時に精度をやや下げる傾向もありました。
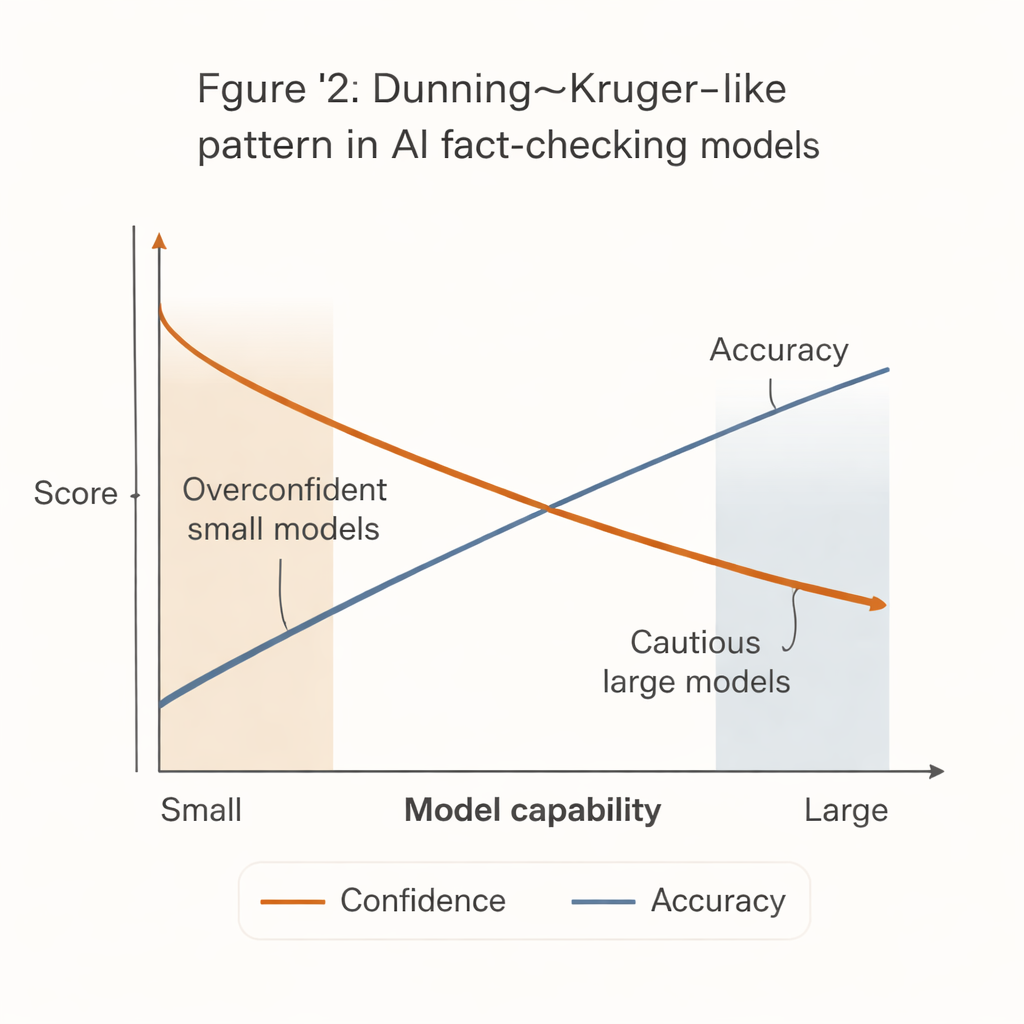
能力の低いシステムほど自信満々に振る舞うとき
人間の心理学でよく知られるダニング=クルーガー効果を反映する際立ったパターンが浮かび上がりました:能力が最も低いシステムほど最も自信を示したのです。小型で安価なモデルは多数の主張に対して断定的な評決を出す傾向がありましたが、精度は明らかに低めでした。対照的に、最も強力なモデル(例えば高度なGPT系)は、コミットしたときの正確さははるかに高かったものの、とくに難解や曖昧な主張に対しては棄権する可能性が高くなりました。
この「確信–能力ギャップ」は現実世界での影響を持ちます。資金の限られた多くのニュースルーム、市民団体、地域のファクトチェック機関は最も強力なAIシステムを導入する余裕がありません。彼らは決定的に見えるが誤りが多い小型で安価なモデルを採用しがちです。これらのツールが十分な安全策なくワークフローやコミュニティ・モデレーションに組み込まれると、自信満々で誤ったファクトチェックを大量に生み、誤情報をむしろ増幅してしまう危険があります。
言語や地域による不平等な性能
本研究はまた、これらのシステムが全員に等しく機能するわけではないことを明らかにしました。主要な複数の言語にわたり、モデルは一般に英語の主張で最も良く、ポルトガル語とヒンディー語でやや劣る傾向がありました。大きなモデルは非英語圏の言語ではより慎重に応答する傾向がありましたが、それでも小型モデルより精度は上回っていました。著者らがグローバルノースとグローバルサウスに結びつく主張を比較したところ、大半のモデルは後者で躓きやすかったです。小型システムは自信を保ちながら精度を落とすことが多く、一方で大規模モデルは確信度の低下が大きいものの正確さの低下は小さく、自己の不確実性を察知して控えめになる傾向が示唆されました。
信頼できるAIツールの未来に向けての示唆
非専門家向けの核心は明快です:現時点のAIファクトチェッカーは均質ではなく、最も手に入りやすいものが最も誤解を招きやすい場合があるということです。強力なモデルは慎重かつ正確であり得ますが、コストが高く時に過度に消極的です。弱いモデルは大胆ですが誤りやすく、特に英語以外やグローバルサウスに関する話題でその傾向が顕著です。著者らはAIは人間のファクトチェッカーを支援するものであって代替すべきではなく、システムに「沈黙すべき時」を教える較正の改善と高品質なツールへのより公平なアクセスを促す政策や設計上の選択が必要だと主張します。さもなければ、誤情報と戦うために構築された同じ技術が、解決しようとする情報的不平等を深めてしまう恐れがあります。
引用: Qazi, I.A., Khan, Z., Ghani, A. et al. Large language models show Dunning-Kruger-like effects in multilingual fact-checking. Sci Rep 16, 7594 (2026). https://doi.org/10.1038/s41598-026-39046-w
キーワード: 誤情報, ファクトチェック, 大規模言語モデル, AIの確信度, 多言語バイアス