Clear Sky Science · ja
構造化プロンプトでファインチューニングした大規模言語モデルにより肺がんナレッジグラフの効率的構築が可能に
医療テキストを地図化する意義
肺がんは世界でも最も致命的ながんの一つであり、その診断や治療に関する情報は研究論文、病院の記録、オンラインの相談、伝統医学の症例集などに分散しています。医師や研究者はこのテキストの洪水に追いつくのが難しい。 本研究は、細かく散在する知識をファインチューニングした大規模言語モデルと精緻なプロンプト設計を用いて自動的に一つのナビゲート可能な“地図”—肺がんナレッジグラフ—に変換する新たな方法を探ります。結果は複雑な医療知識をコンピュータが検索しやすく、専門家が意思決定支援ツールで利用しやすくすることを目指しています。
散在する記述からつながる事実へ
著者らは単純な発想に着目します:医療テキストから誰が何を誰にしたか(who-does-what-to-what)を確実に抽出できれば、それらの事実をグラフとしてつなげられるということです。実務上は、自由記述の文を「トリプル」と呼ばれる小さな構成要素に変換することを意味します。トリプルはエンティティの組とそれを結ぶ関係で、たとえば「肺がん – 治療される – 化学療法」のようになります。従来のグラフ構築法は大量のアノテータを必要としたり、細かな差異や新しい発見を見落とす脆弱なルールに依存したりします。これを克服するためにチームは既存の中国語大規模言語モデルであるChatGLM-6Bをファインチューニングし、オンラインの患者–医師の対話から構造的データベースや中医の記録まで幅広い情報源から肺がんに関する医療上有意義なトリプルを抽出する専門化を行いました。 
AIに整った単位で考えさせる教育
汎用の言語モデルに単に「情報を抽出して」と頼んでも、出力は散漫で会話調になりがちです。そこで研究者たちは厳格なプロンプト設計を行い、ほぼ5万件の良好な例でモデルをファインチューニングしました。各例は指示と期待される正確なトリプル形式の出力を示します。プロンプトはモデルに専門的なテキストマイニングのエキスパートとして振る舞うよう求め、コンピュータで読み取り可能な構造化トリプルのみを出力させ、文が入れ子の詳細(たとえば治療、使用薬剤、その用量)を含む場合は“段階的に考える”ことを指示します。役割設定、形式規則、段階的推論の組み合わせにより、モデル(現在はKGLMと呼ばれる)は会話型アシスタントから機械可読の事実を厳格に抽出する装置へと変わります。
多様な声を一つの明確なグラフに融合
テキストから得られる生のトリプルは物語の一部に過ぎません。同一の疾患や薬が異なる呼称で現れることはよくあります—例として「慢性閉塞性肺疾患」と「COPD」。混乱や冗長を避けるために、著者らは非構造化のウェブテキスト、半構造化の臨床ケース、既存の医療ナレッジグラフという三つのデータ流をまたいで同等のエンティティを統合する融合ステージを設計しました。まず高速な文字列類似チェックで明白な一致を検出し、不十分な場合はより深い文脈的意味類似モデル(Sentence-BERT)で意味を比較します。重複と判断されたエンティティは単一の正準ノードにまとめられ、短い名称が優先され、他の表記は別名として保存されます。専門家が端境ケースをレビューして誤解を招く記述や低品質な記述を除去することで、Neo4jデータベースに格納されるよりクリーンで一貫性のある肺がんナレッジグラフが得られます。 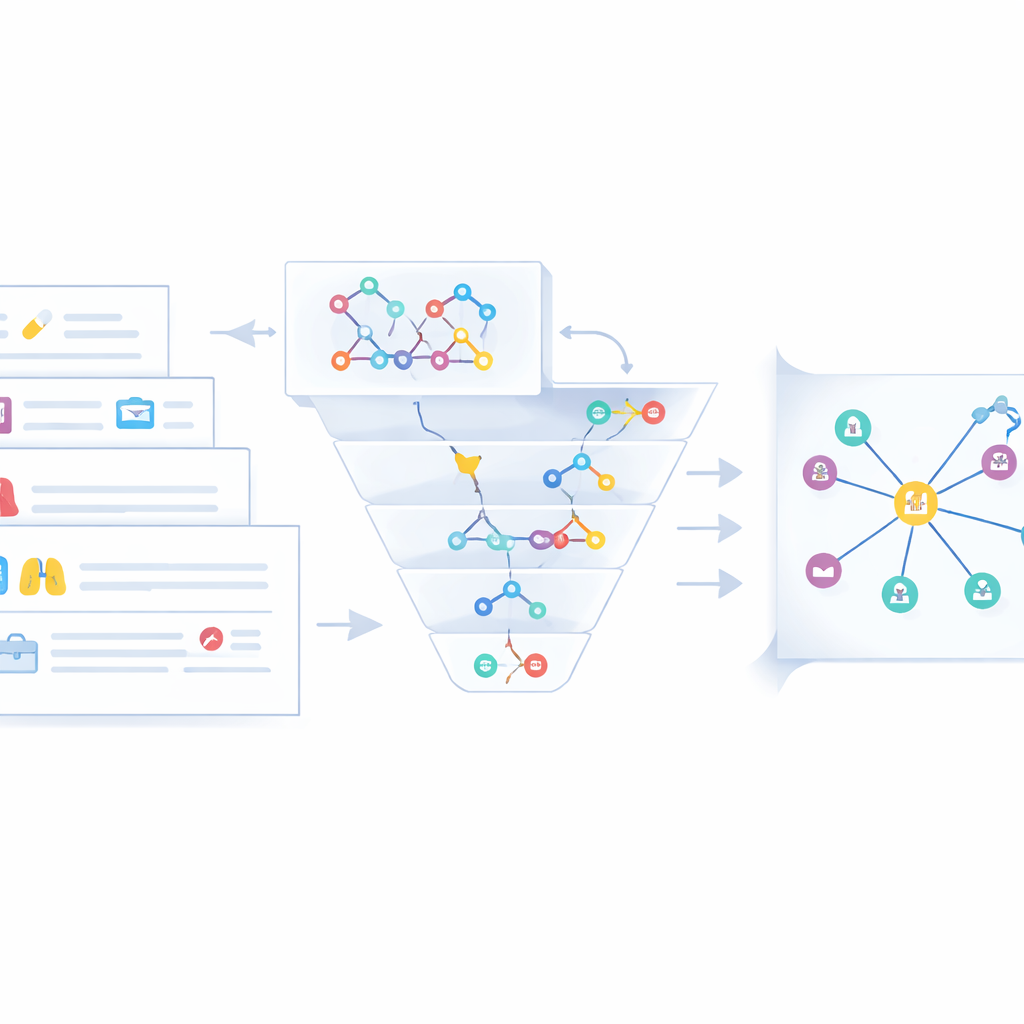
この知識地図の性能はどれほどか
性能評価のために、チームはKGLMをBERTや畳み込みネットワークに基づく標準的な深層学習手法、およびファインチューニングしていない元のChatGLMモデルと比較しました。関係抽出のタスク—どのエンティティがどのように結びつくかを判断する課題—において、ファインチューニングされプロンプトで導かれたKGLMはF1スコアで約0.82を達成し、テストした全てのベースラインを上回り、出発点のモデルに比べて約25%の改善を示しました。アブレーション実験では各プロンプト要素が影響を及ぼすことが示されており、専門家役割、厳密なトリプル形式、あるいは“段階的に考える”指示を削ると、特に入れ子の属性や中医学用語を含む複雑な文で精度が低下しました。臨床とインフォマティクスの専門家パネルも、ファインチューニングや構造化プロンプトなしで構築されたグラフより、本手法で得られたグラフの方がより正確で、使いやすく、臨床的関連性が高いと評価しました。
今後の医療ツールへの示唆
平たく言えば、本研究は適切な訓練と指示があれば、大規模言語モデルが現実世界の雑多な肺がんテキストを効率的に構造化された検索可能な事実の網に変換できることを示しています。この肺がんナレッジグラフは依然として研究プロトタイプであり、中国語情報源と単一疾患領域に限定されていますが、継続的に更新される“知識地図”が意思決定支援システム、教育ツール、研究探索を支える未来を示唆します。著者らはそのようなグラフは慎重に検証され定期的に更新される必要があり、専門家の監督なしに医療行為を導く準備ができているわけではないと強調します。それでも、ファインチューニングした言語モデルと巧みなプロンプト設計の組み合わせは、医療知識の整理という困難な課題をよりスケーラブルかつタイムリーにする可能性を示しています。
引用: Zhou, C., Gong, Q., Luan, H. et al. Fine-tuned large language models with structured prompts enable efficient construction of lung cancer knowledge graphs. Sci Rep 16, 9505 (2026). https://doi.org/10.1038/s41598-026-38959-w
キーワード: 肺がん, ナレッジグラフ, 大規模言語モデル, 関係抽出, 医療AI