Clear Sky Science · ja
訓練速度と精度のバランスを保つ感染症予測モデルのデータプライバシー保護手法
なぜ健康データ保護がいまだに重要なのか
病院や保健機関は現在、インフルエンザやCOVID-19などの感染症の発生を数日から数週間前に予測するために人工知能に依存しています。こうした予測はワクチン接種計画、人員配置、緊急時の対応計画の指針になります。しかし、予測の精度を高める詳細な患者記録は極めてセンシティブでもあります。法律や市民の懸念によりデータを機関間で集約できないことが多く、モデルの性能が低下します。本論文は、各病院のデータを現地に安全に保ったまま、高品質な感染症予測システムを訓練する方法を提示します。
カルテを共有せず多病院から学ぶ
著者らはフェデレーテッドラーニングと呼ばれる手法を基に構築しています。この手法では複数の病院が共有の予測モデルを共同で訓練します。生の患者記録を中央サーバーにコピーする代わりに、各拠点がモデルをローカルで訓練し、モデルの内部パラメータに対する数値的更新のみを返送します。中央サーバーはこれらの更新を統合して改善されたモデルを配布し、このループを繰り返します。理論上、フェデレーテッドラーニングは個人情報が建物の外に出ないためプライバシーを保護します。しかし実際には、巧妙な攻撃者が共有された更新から元データの詳細を推測することがあり、追加の保護が必要です。 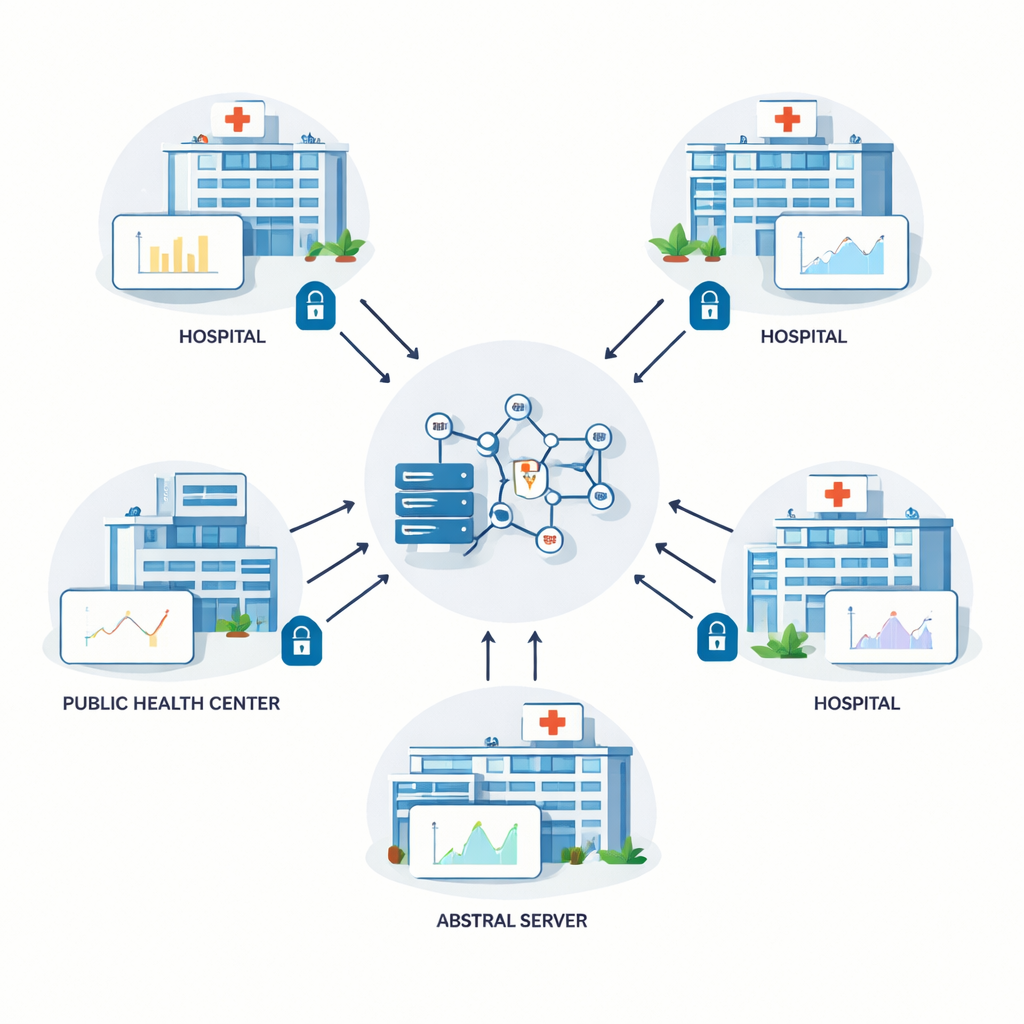
賢い暗号で数値をロックする
セキュリティを強化するために、研究チームは準同型暗号を採用しています。これは暗号化された数値に対して平文を復号せずに計算を行える「デジタルの錠」の一種です。従来のこの種の方式は非常に安全ですが、遅くてデータ消費が多く、大規模かつ複雑なモデル(例えばLSTMベースのモデル)では扱いにくいことが知られています。研究者らはモデルの異なる部分に対して異なる扱いをするハイブリッド方式を設計しました。最も情報をさらす可能性のある構成要素は強力だが重い暗号で保護し、あまり敏感でない部分はより軽量で高速な方式を使います。さらに、事前に決めたランダムなスケジュールにより、各訓練ラウンドで拠点が暗号化された更新を実際に送るかどうかを決め、冗長な通信を省けるようにしています。テストでは、この組み合わせは重い暗号方式を全てに適用する場合と比べて訓練を約25パーセント高速化しつつ、強力な暗号前提の下でデータ保護を維持することが示されました。
本当に重要な更新だけを送る
暗号を賢く使っても、モデルのごく小さな変化をすべて機関間でやり取りするのは時間とネットワーク帯域の無駄です。そこで著者らはData Selection–Distributed Selection Stochastic Gradient Descent(DS-DSSGD)と呼ばれる新しい訓練ルールを提案します。訓練中、アルゴリズムはモデルの各部分がステップ間でどれだけ変化したかを測定し、事前に設定した閾値を越えた更新のみを送信します。影響の小さい微細な変化は無視されます。同時に、アルゴリズムは最も大きく、情報量の多い変化に寄与したデータポイントを追跡します。これら影響力の大きい記録は精選されたデータセットに収集され、最終ラウンドの訓練に用いられます。宜昌市の3年分の実際の感染報告と地域のウェブ検索トレンドを用いた実験では、DS-DSSGDは複数の標準手法と比較して訓練時間をおよそ10パーセント短縮し、予測精度に有意な損失をもたらさないことが示されました。
安全な協働のための実用的プラットフォーム
技術的な進歩は、病院や研究所が実際に使えなければ意味がありません。このギャップを埋めるため、チームは自らの方法をYi Shu Fang XDP Privacy Security Computing Platformと呼ばれる実運用の計算環境に統合しました。XDPはデータの収集やクリーニングから暗号化された解析、結果の共有に至るまで健康データの一連の流れを管理します。統計学者やバイオインフォマティシャン、臨床医が使い慣れたツールをサポートし、研究者が生データをダウンロードすることなく管理されたワークスペース内で共同作業できるようにします。このプラットフォーム内でハイブリッド暗号方式とDS-DSSGDアルゴリズムはプラグイン可能なコンポーネントとして動作し、理論的枠組みを実用的なシステムに変えています。 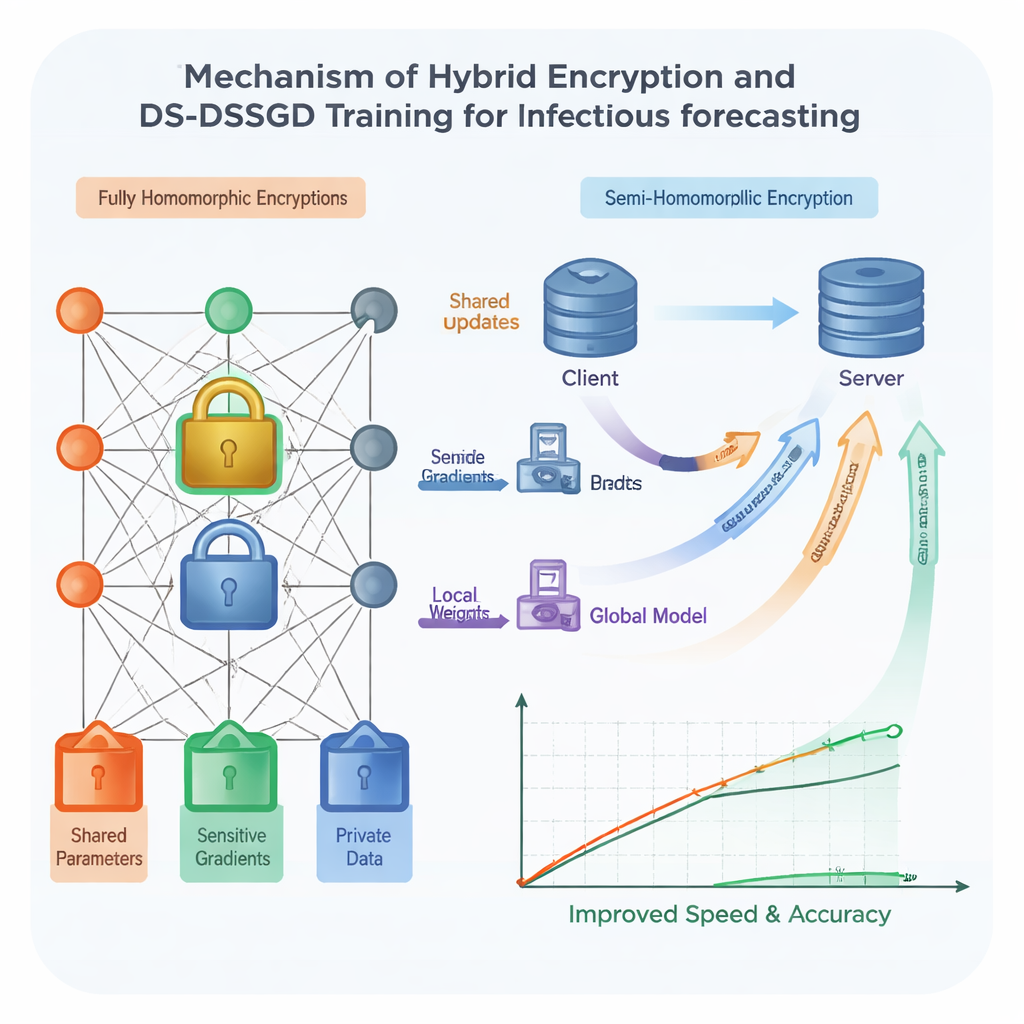
今後の発生予測にとっての意義
日常的な観点から、この研究は感染症予測において「両立が可能である」ことを示しています。すなわち、患者のプライバシーを保護しながら、複数の機関から得たデータで高速かつ精度の高いモデルを訓練できるということです。モデルの各部分に最適な強度の暗号を適用し、必要なときだけ更新を送信し、すべてを安全な協働プラットフォームに組み込むことで、プライバシー保護のコストを致命的な負担から管理可能なオーバーヘッドへと低減します。こうしたアプローチが広く採用されれば、病院や公衆衛生機関は個々の医療記録を露出することなく次の流行に対して知見を共有できるようになるでしょう。
引用: Wang, X., Jiang, Y., Pan, G. et al. A data privacy protection method for infectious disease prediction models with balanced training speed and accuracy. Sci Rep 16, 7415 (2026). https://doi.org/10.1038/s41598-026-38906-9
キーワード: 感染症予測, 健康データのプライバシー, フェデレーテッドラーニング, 準同型暗号, ディープラーニング