Clear Sky Science · ja
教師なし手法による種の一般性と出現率の推定
普通種と希少種を数えることが重要な理由
自然が危機に瀕しているとき、私たちはしばしば絶滅寸前の希少な動物を思い浮かべます。しかし、周囲の生態系の大部分は非常にありふれた生物で構成されており、それらは一般的であったり、誰にも気づかれないまま静かに消えつつあったりします。ある場所で種がどれほど広く分布しているかを把握することは、汚染、土地利用、気候変動に対して生態系がどう反応するかを予測する上で不可欠です。本論文は、既存の目撃記録と現代のデータ解析のみを用いて、多くの種の一般性や希少性を同時に推定する手法を紹介します。目的は、現在および将来の生息可能性を予測する計算モデルに、より客観的な入力を提供することです。
単純な目撃情報から大きな生態学上の問いへ
生態学者は通常、ある環境が種にとって適しているかを推定するために、生態学的ニッチモデルと呼ばれる計算モデルを用います。これらのモデルは、気候変動や新たな地域で種がどこに現れるかを予測するのに役立ちます。重要な要素の一つが「出現率」で、概念的には調査された地点のうち種が存在する割合です。これは、追加の調査が行われる前に種が一般的か希少かという期待を符号化します。その期待は、モデルが生存適合度のスコアを存在確率に変換する方法や、地図上で「存在」と「不在」の境界を引くやり方に強く影響します。特に希少種について出現率の推定が誤っていると、予測が誤解を招き、保全計画が誤った場所に重点を置く可能性があります。
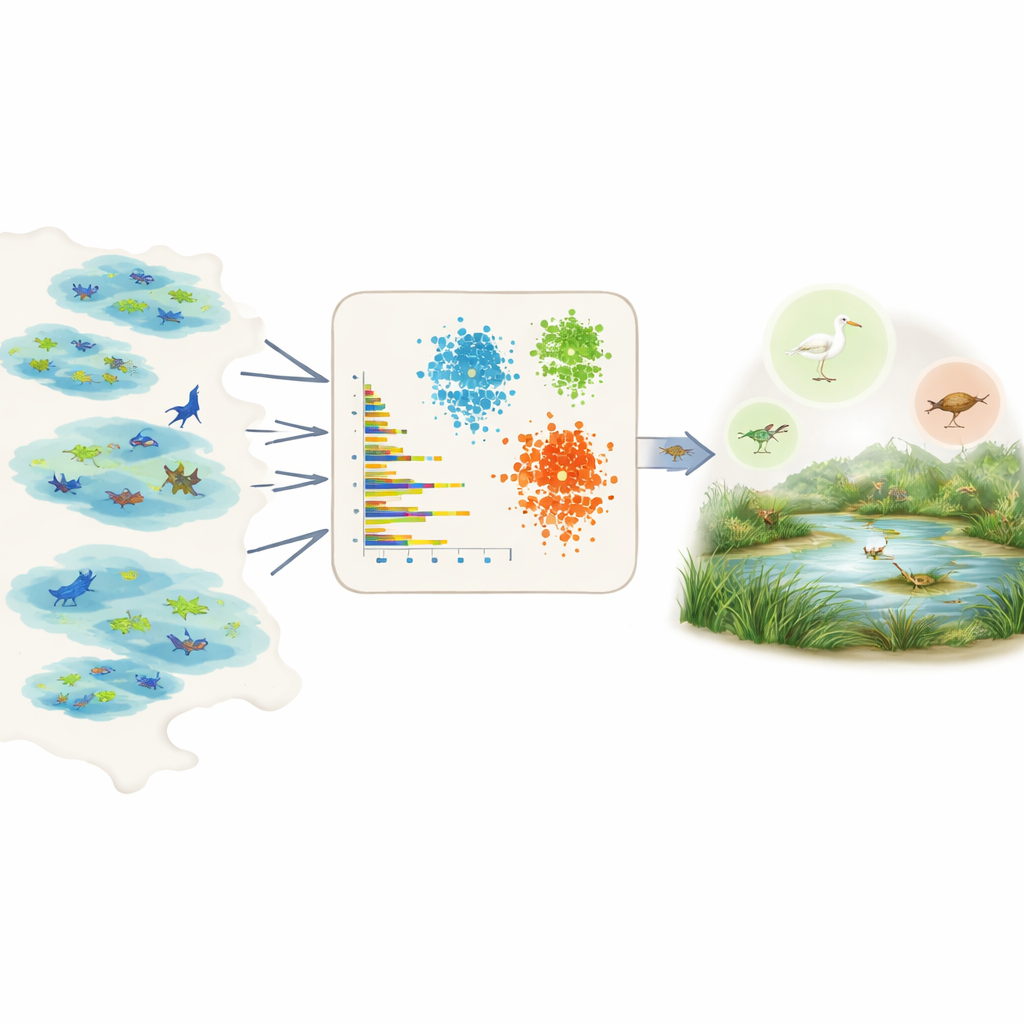
何百もの種についてデータに語らせる
出現率を直接測ることは難しく、現地データは不均一で偏りがあります。調査が集中する地域もあれば、見つけやすい種と見つけにくい種があり、多くの記録は市民科学プロジェクトからの不均等な努力に基づいています。各種について専門家の意見や種ごとの詳細な知見に頼る代わりに、著者らは膨大な公開種観察データベースであるGlobal Biodiversity Information Facility(GBIF)を活用します。選んだ地域の各種について、生の記録を数個の単純で比較可能な指標に要約します:1回の目撃あたり通常報告される個体数、どれだけ多くのデータセットや湿地にその種が含まれるか、これらの湿地内でどれほど広く分布しているか、時間を通じてどの程度頻繁に観察されるか(観察が一時的に急増することがどれほどあるかを含む)などです。
機械に一般種と希少種を分類させる
これらの要約特徴を用いて、チームは3つの教師なし学習ツールを適用します。2つのクラスタリング手法と変分オートエンコーダとして知られる深層学習モデルで、どの種が一般的か希少かを事前に教えずにパターンを探索します。クラスタリング手法は、出現頻度、分布の広がり、観察頻度が似た種をまとめます。オートエンコーダは「典型的な」種の記録がどのようなものかを学び、異常なパターンを検出します。これらの異常はしばしば希少種や観察が不十分な種に対応します。モデルは各種を直感的な三つのクラス(非常に一般的、かなり一般的、希少)に割り当て、さらにそれらのクラスを生態学的ニッチモデルに事前確率として直接組み込める数値的な出現率に変換します。
脆弱な湿地での手法の検証
この枠組みが実際にどの程度機能するかを見るため、著者らはイタリア・トスカーナのマッサチウオッリ湖盆地に注目しました。ここは鳥類、魚類、昆虫その他の動物が豊富な低地の湿地です。この地域は生物多様性のホットスポットであり観光地でもありますが、気候変動や水不足、汚染に脆弱でもあります。湖に関連する161種の動物について、モデルは他のイタリアの湿地からの記録で訓練され、マッサチウオッリで各種がどれほど一般的であるべきかを推定するように求められました。地元のフィールド経験豊富な専門家2名が同じ種を独立に評価しました。比較の結果、深層学習モデルは専門家の総合的な見解とおおむね81~90%の種で一致し、クラスタリング手法や3手法のアンサンブルも良好な成績を示しました。
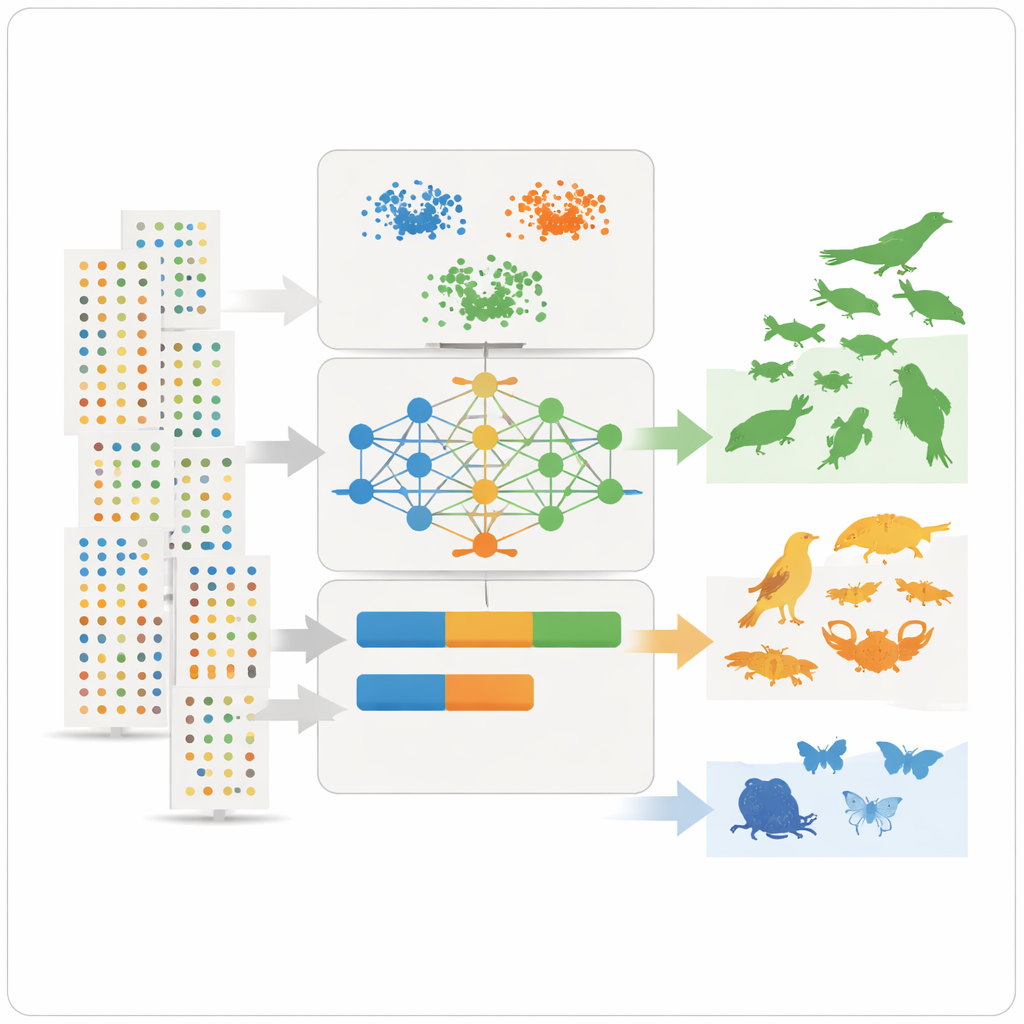
意見の不一致と隠れた偏りから学ぶ
すべてが完全に一致したわけではありません。湖周辺で豊富だと専門家に知られているがデータ上は希少と出た種がいくつかあり、これはしばしばその種が見つけにくい、報告が少ない、あるいは一部の湿地で特に注意深く観察されているためでした。これは重要な制約を浮き彫りにしました:大規模データベースは種が実際にどこにいるかだけでなく、人々がどこでどのように自然を探しているかを反映します。感度解析により分類に最も影響を与える特徴が明らかになり、データセット当たりの平均記録数、目撃あたりの個体数、年を通した観察の一貫性が特に有益な指標として浮上しました。偏りは残るものの、この手法は明確で再現可能な出現率推定を提供し、モデリングの必要に応じてより細かいまたは粗いクラスに調整できます。
将来の自然予測にとっての意義
専門外の人にとっての主なメッセージは、既存の生物多様性データをより賢く利用して、各ケースごとに手作業で調整することなく、ある環境でどの種が一般的、中程度、希少である可能性が高いかを評価できるようになったことです。ノイズの多い観察記録を透明でデータ駆動な出現率推定に変えることで、この枠組みは生息適合性や将来の生物多様性動向に関する生態学モデルの予測をより現実的にします。これにより、マッサチウオッリのような湿地や世界中の多くの生態系に対するより良い計画立案を支援でき、現地データが不完全で専門家の時間が限られている場合でも有用です。
引用: Bove, P., Bertini, A. & Coro, G. Estimating species commonness and prevalence through unsupervised methods. Sci Rep 16, 8331 (2026). https://doi.org/10.1038/s41598-026-38900-1
キーワード: 種の出現率, 生物多様性モデリング, 湿地生態系, 機械学習と生態学, 種の一般性