Clear Sky Science · ja
最適化手法を用いた直列カスケード型ハイブリッド適応深層ネットワークによる歌詞テキスト分類
より賢い楽曲フィルタが重要な理由
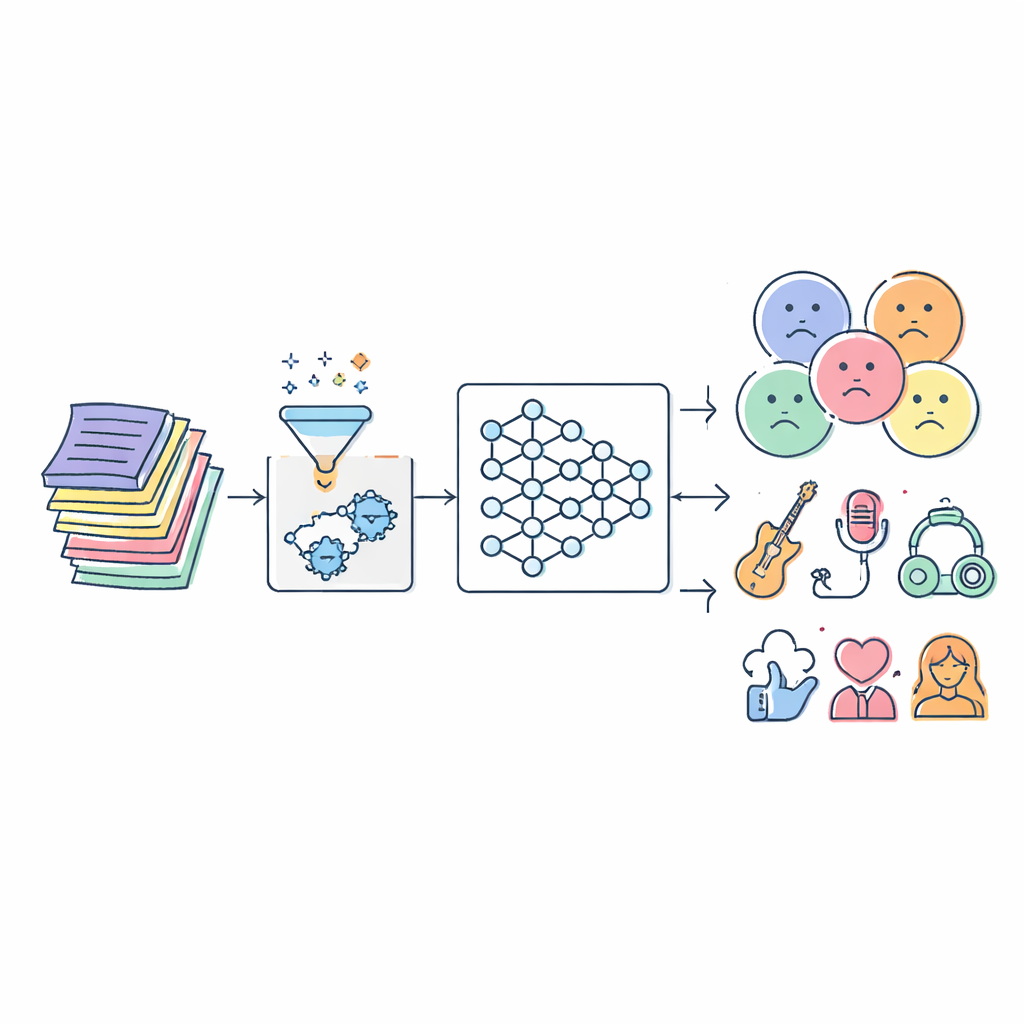
音楽はほとんど途切れず私たちの生活に流れ込み、その多くはアルゴリズムが選んでいます。しかし、こうしたシステムの多くはいまだに簡単な問いに苦労しています:曲の歌詞は具体的に何を伝えており、誰に適しているのか? 本論文はこの問題に取り組み、歌詞を自動で読み取り、ムード、ジャンル、感情、さらには演者のタイプまで分類する高度な人工知能(AI)モデルを構築します。目的は、子ども向けに安全なプレイリストを作ること、ムードに基づく推奨の精度向上、音楽研究者向けのより良いツールの提供です。
歌詞に潜む課題
歌詞は単なる良い/悪い言葉の一覧よりもずっと複雑です。同じフレーズでも一方の曲ではやさしく感じられ、別の曲では脅迫的に受け取られることがあり、聴き手は自身の経験を持ち込んで解釈します。従来のフィルタは静的な不適切語リストや単純な統計手法に頼ることが多く、文脈を見落とし、流行語の変化についていけず、誤ったラベリングを起こしがちです。同時に、デジタル音楽の爆発的な増加によって、言語やスタイルの異なる何百万ものトラックを分析する必要があり、手作業のラベリングや旧来のアルゴリズムでは対応が難しくなっています。
生の歌詞のクレンジング
著者らはまず、複数のジャンルと言語にまたがる数十万曲を収めた3つの公開データセットから大規模な歌詞コレクションを組み上げます。AIがテキストから学習する前に、歌詞はクリーンアップされなければなりません。システムは句読点や特殊記号、繰り返しや無関係な断片を除去し、関連する語形を共通の語幹に統一します(たとえば「singing」「sings」「sang」はすべて「sing」にする)。この前処理はノイズを削ぎ落としつつ意味を保持することで、後続の段階が形式的な差異や綴りの揺れではなく、感情的なトーンや話題に集中できるようにします。
注意深い聴き手のように読む多層AI
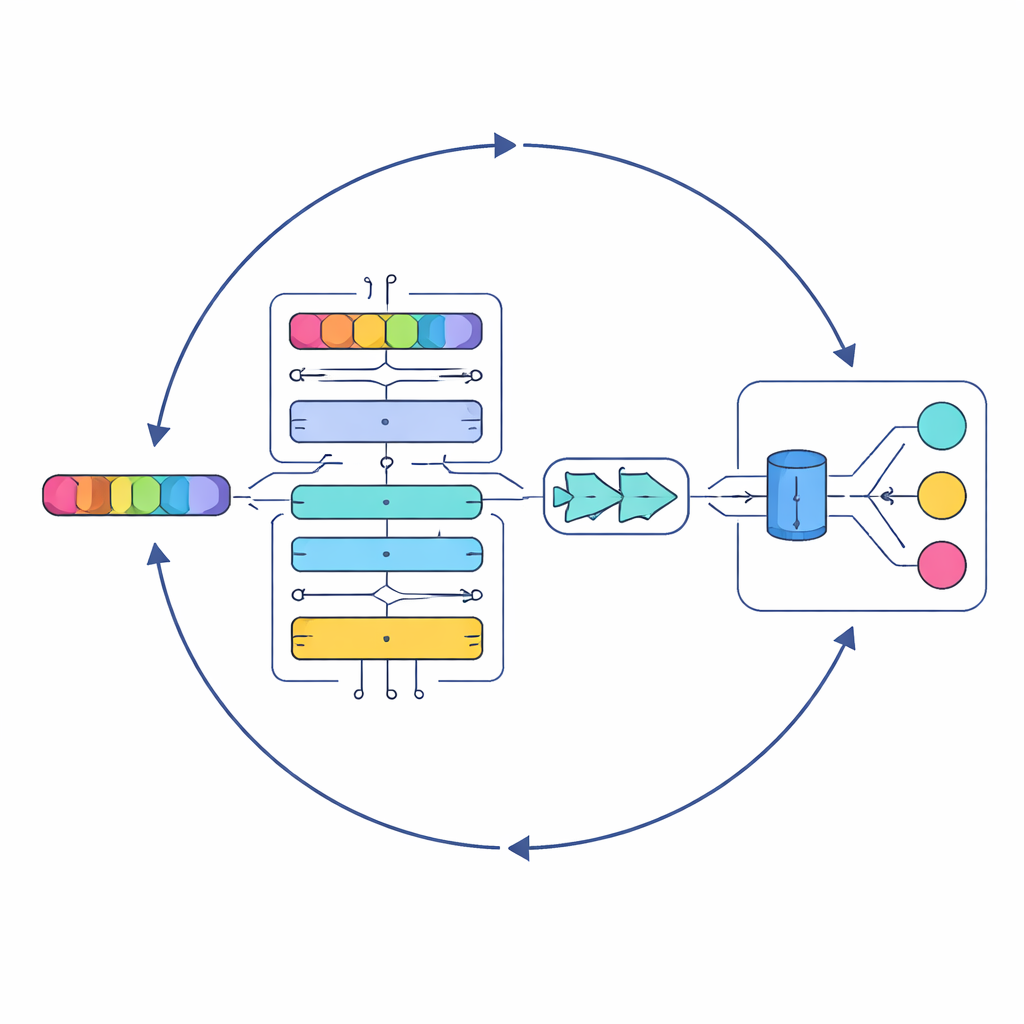
研究の中心には、Serial Cascaded Hybrid Adaptive Deep Network(SCHADNet)と呼ばれる新しいモデルがあります。これは現代の言語AIの三つの強力な考えを組み合わせています。第一に、トランスフォーマーに基づくエンコーダは歌詞全体にわたる単語同士の関係を捉え、局所的な隣接関係だけに依存しません。第二に、双方向の長短期記憶(Bi-LSTM)層が歌詞を前後両方向に読み、前の行が後の行の意味をどう彩るかを理解する助けになります。第三に、ゲート付き再帰ユニット(GRU)層がこれらの情報を精緻化して最終判断に適した凝縮された要約にまとめます。これらの要素は合わさって、曲のテキストの異なる側面に焦点を当てる専門的な読み手の合唱のように機能します。
海から借りた戦略
単に深層学習層を積み重ねるだけでは不十分で、ニューロン数や学習時間といった内部設定は性能に強く影響します。これらの選択を手作業で調整する代わりに、著者らは海洋捕食者の狩りのパターンに着想を得た最適化手法を用います。改良型マリンプレデターアルゴリズム(IMPA)は多数のパラメータ組合せを探索し、最良の結果を出すものへと徐々に収束します。元のアルゴリズムのうちこの設定で寄与しなかった部分を削ることで、収束性を改善し、より速く、より安定して良い解に到達できるようにしています。
システムの性能
研究者たちはSCHADNetとIMPAを三つの異なる歌詞データセットで評価し、従来法と比較しました。比較対象には古典的な機械学習分類器や、単純なLSTM、トランスフォーマーのみのシステム、各種ハイブリッドネットワークなどの人気深層学習モデルが含まれます。精度、再現率(真に関連する曲をどれだけ見つけられるか)など複数の評価指標で、新手法は一貫して上位に立ちました。ある大規模な多言語データセットでは約93%の正分類率を示し、特に陰性的予測値(フラグ付けされたカテゴリに該当しない歌詞を正しく認識する能力)が高く、過剰なブロックや誤分類を避ける点で重要な性能を示しました。
聴き手とクリエイターにとっての意義
一般読者にとっての結論は明快です:著者らは歌詞をより細やかに、信頼性高く読み取るシステムを構築しました。粗い語リストに頼るのではなく、フレーズ全体や文脈、大規模な楽曲群にわたるパターンを見て、自動的にムードやスタイル、若年層への適合性などのラベルを付与します。モデルは複雑で計算負荷も高いものの、より賢いペアレンタルコントロール、充実したムード別プレイリスト、そしてポピュラー音楽の傾向を研究する新たな手法への道を開きます。将来的にはデータ要求量を減らし学習を高速化することが目標ですが、現状でもSCHADNetは音楽プラットフォームが歌詞を注意深い人間の聴き手に近い形で理解する未来を指し示しています。
引用: Jasmine, R.L., Mukherjee, S., Robin, C.R.R. et al. Serial cascaded hybrid adaptive deep networks-based lyrics text classification using optimization approach. Sci Rep 16, 8527 (2026). https://doi.org/10.1038/s41598-026-38813-z
キーワード: 音楽レコメンデーション, 歌詞解析, テキスト分類, 深層学習, コンテンツモデレーション