Clear Sky Science · ja
ペルシア語リウマチ学ボード試験における大規模言語モデルの性能評価:GPT‑4oとGPT‑5.1の正答率と臨床的推論
医師と患者にとってなぜ重要か
人工知能は急速に医療の教室や診療現場に入りつつありますが、これらツールの検証は英語が中心になりがちです。本研究は何百万ものペルシア語話者にとって重要な問いを投げかけます:高度なAIチャットボット、具体的にはGPT‑4oとGPT‑5.1は、ペルシア語で書かれた複雑なリウマチ学の試験問題をどれだけ正確に扱えるのか?その答えは、教育者、研修医、患者が、これらツールが安全に学習支援に使える領域と人間の専門知識が不可欠な領域を理解する助けになります。
AIを試験にかける
研究者らは、2023年と2024年のイラン公式リウマチ学ボード試験から204問の多肢選択式問題を収集しました。これらは専門医認定のために合格が必要な同じ試験です。欠陥のある7問を除外した結果、197問を解析に用いました。各問題は、付随する画像やグラフを含めてペルシア語でGPT‑4oとGPT‑5.1に、それぞれ別の新規チャットで入力されました。モデルには最良の解答を選び、その理由を説明するよう求められ、研修医が学習中にAIに問いかける状況を再現しました。
解答と推論の両方を検証
性能評価は二つの方法で行われました。まずモデルの選択肢を公式解答と照合し、正誤の単純な正答率を算出しました。次に、6名のボード認定リウマチ科医が各説明の質を5段階で独立に評価し、明らかに誤った推論から完全かつ臨床的に妥当な推論までを判定しました。各モデルの解答は、互いに盲検化された別々の2名のリウマチ科医が採点しました。これにより、AIが「偶然正解を選んだ」かどうかだけでなく、その論理が専門家の考え方に似ているかを検証できました。
新しいモデルの成績
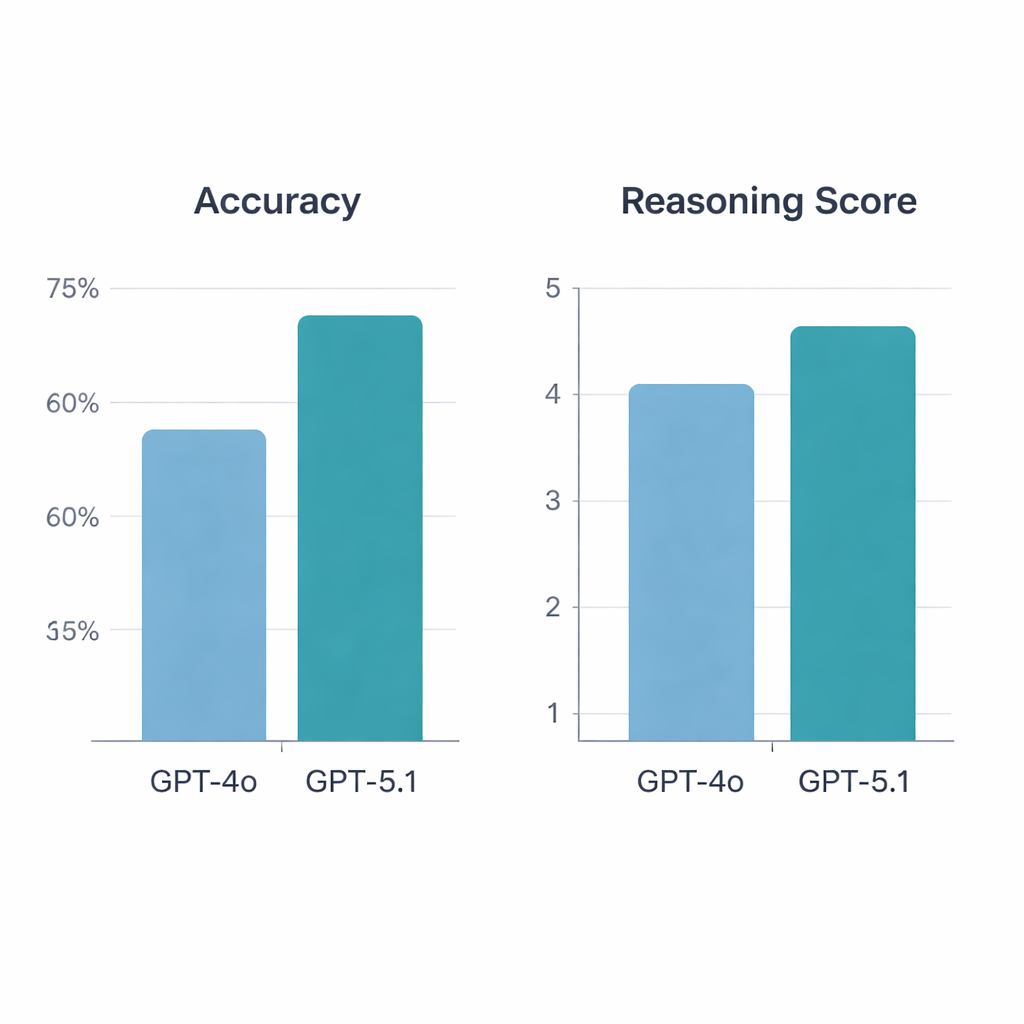
GPT‑5.1はGPT‑4oより明確に優れました。197問に対してGPT‑4oの正答率は64.5%であったのに対し、GPT‑5.1は76%に達し、統計的に有意な向上を示しました。両モデルとも113問を正解し34問を不正解としましたが、GPT‑5.1はGPT‑4oが取りこぼした追加の36問を正しく解き、GPT‑4oのみがユニークに正答したのは13問にとどまりました。リウマチ科医が説明を採点した結果でもGPT‑5.1が上回り、平均推論スコアは5点満点中4.47でGPT‑4oの4.13より高く、最高評価もより多く獲得しました。GPT‑4oは基礎科学、症例要約、診断、治療といった問題カテゴリによって推論の質がばらついたのに対し、GPT‑5.1は全カテゴリでより均一な性能を保ちました。
強み、課題、そして人間側の見解の不一致
研究は重要なニュアンスを明らかにしました。モデルの最終解答が誤っていても、専門医はその推論を比較的筋の通ったものと評価することがあり、試験の採点と実臨床的思考の間にギャップが存在することを示しました。同時に、リウマチ科医間の評価一致度は限定的であり、「良い推論」とは何かについて臨床医自身が意見を異にすることも浮き彫りになりました。言語も影響するようで、英語やスペイン語での先行研究は類似モデルでより高いスコアを報告しており、AIは主要な世界言語をペルシア語よりも優勢に扱う傾向があることが示唆されます。著者らは、これらチャットボットが説得力のある説明を生成する一方で事実誤認を隠す可能性があり、システムのアップデートによって性能が変わり得る点を強調しています。
今後の意味
一般読者に向けた要点は、新世代のAIチャットボットはペルシア語の専門医試験を扱う能力が向上しているものの、厳格な訓練や専門家の判断に取って代わる段階には達していないということです。GPT‑5.1はリウマチ学の研修における有用な学習パートナーになり得ます—トピックの要約、症例の手順説明、構造化された解説の提供などに役立ちますが、診断や治療に関わる重大な判断の最終決定としては信頼すべきではありません。著者らは、より大規模で多言語の研究、時系列での反復テスト、現実的な臨床シミュレーションの実施を求めており、これらツールが医学教育や将来的に日常的な患者ケアに安全に組み込まれる方法を明らかにする必要があると結論づけています。
引用: Rafiei, F., Sadeghipour, S., Sheikhalishahi, S. et al. Evaluation of large Language model performance on Persian rheumatology board exams: accuracy and clinical reasoning of GPT-4o vs. GPT-5.1. Sci Rep 16, 7274 (2026). https://doi.org/10.1038/s41598-026-38716-z
キーワード: リウマチ学, ペルシア語の医学教育, 大規模言語モデル, 臨床推論, ボード試験