Clear Sky Science · ja
適応的融合と知識蒸留を用いたエッジ機器向け説明可能なハイブリッドCNN–トランスフォーマモデルによる手話認識
なぜ小型の手話ツールが重要なのか
何十億もの日常的な会話は、話し言葉ではなく手の動きや表情、身体言語に依存しています。しかし、多くの携帯電話、タブレット、公共向け端末は依然として手話を理解できません。特に英語圏以外ではその傾向が強いです。本稿はTinyMSLRを紹介します。これは小型で説明可能な手話認識システムで、低消費電力の小型デバイス上でリアルタイムに動作するよう設計されています。一般的なハードウェアを、聴覚障害者や難聴者のための手頃で信頼できるコミュニケーション支援に変えることを目標としています。
より多くの言語を会話に取り込む
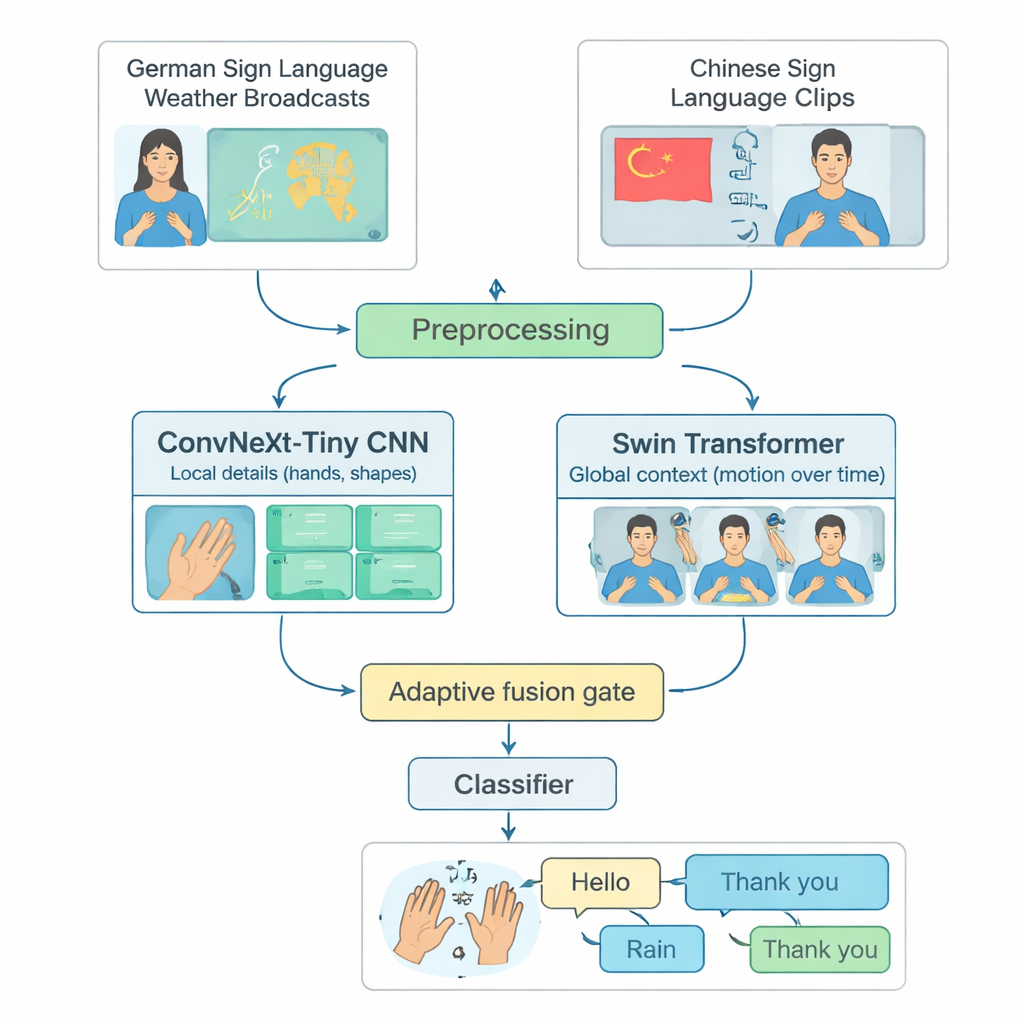
多くの先進的な手話認識システムは単一言語、たいていはアメリカ手話に焦点を当て、強力なコンピュータ上でのみ動作します。それにより、他の手話を使う人々や計算資源が限られた地域の人々が取り残されます。著者らはこのギャップに対処するため、2つの言語を用いた共通のテストベッドを構築しました:ドイツ手話の天気放送データと大規模な中国手話コレクションです。Hello、Weather、Rain、Happy、Yes、Thank youのような両言語に存在する20の一般的な日常表現を慎重に選びます。長い動画を単一の符号化を含む短いクリップに切り詰め、クラスごと・話者ごとのサンプル数を均一にすることで、隔離された単語(単独の手話)を言語横断で認識する能力を公平かつ再現可能に評価できる基盤を作りました。
ハイブリッドモデルが手と動きをどのように見るか
TinyMSLRは映像を捉えるための2つの補完的な手法を組み合わせます。一方の枝はConvNeXt‑Tinyという最新の畳み込みネットワークで、指の形や微細な質感など局所的な詳細を捉えるのに優れています。もう一方はSwin Transformerで、これは空間と時間にまたがるパターン—数フレームにわたる手や顔、上半身の動き—を追跡するのに優れます。各短尺クリップは32フレーム、224×224ピクセルに標準化され、軽い拡張(小さな回転や明るさ変化など)が施されてから両方の枝に並列に入力されます。各枝は見たものを表す768次元の要約を出力し、2つの要約を組み合わせることで鋭い局所的詳細とより広い動き・文脈の両方を捉えます。
何が重要かをモデル自身に決めさせる
ある手話は主に手形で区別され、別の手話は腕の大きな動きや表情に依存するため、TinyMSLRは両視点を結合する単一の固定式を採りません。代わりに、小さな「融合ゲート」を使って、各入力クリップごとに詳細志向の枝と文脈志向の枝のどちらをどの程度信頼するかを学習します。ゲートは両方の特徴要約を見て、合計が常に1になる2つの重みを出力し、最終表現はその重み付き和になります。訓練中は各枝に小さな分類器も与えられ、それぞれ単体でも有用になるよう学習します。さらに、大きめの“教師”ネットワーク(1つはCNN、1つはトランスフォーマ)がラベルだけでなく類似する代替ラベルの情報も示すことで小型モデルを穏やかに導きます。この知識蒸留という手法により、コンパクトなシステムがより重いモデルの精度に近づきつつ、エッジ機器向けのサイズと速度を維持できます。
システムが各決定を下す理由を可視化する
単なる精度にとどまらず、著者らはユーザーや開発者がモデルの注視点を検査できることを重視します。彼らはSHAPという一連の手法を採用し、入力の各部分に重要度を割り当てます。実際には中間特徴に対して説明を算出し、それをフレーム上にヒートマップや時間的プロットとして戻します。これにより、例えばRainとSnow、あるいはColdとBadのように視覚的に似た手話の判断を駆動するフレームや領域が明らかになります。多数の説明を集約すると、表情や頭の動きといった非手動の手がかりに加え、手首の向きや手形が特に影響力を持つことが示されます。これらの洞察は、システムが背景のアーティファクトではなく、実際に意味のある署名的側面に依拠していることを検証するのに役立ちます。

速度、節約性、そして今後の余地
20手のバイリンガルベンチマーク上で、TinyMSLRは学習および検証で約99%の精度、F1スコアもほぼ99%に達します。一方でパラメータ数は270万未満、1クリップあたりの演算量は約19億回程度に抑えられています。最新のGPU上では1つの手話を処理するのに約13.5ミリ秒、消費エネルギーは30ミリジュール未満、モデルの格納サイズは約7.2メガバイトに収まります。これらの数値は、低価格のボードや組込みシステム上でリアルタイムのオンデバイス手話認識が現実的であることを示唆しています。著者らは、本研究が短い単独の手話と2言語に限定され、表情を明示的な信号として扱っていない点に注意を払っています。語彙の拡張、連続文への対応、より多くの言語、表情や頭の動きの明示的モデリングは今後の課題です。それでも、TinyMSLRは説得力のある概念実証を提供します:正確で効率的、かつ解釈可能な手話理解ツールはクラウドに限定される必要はなく、日常的なデバイス上で直接動作し得るのです。
引用: Lamaakal, I., Yahyati, C., Maleh, Y. et al. An explainable hybrid CNN–transformer model for sign language recognition on edge devices using adaptive fusion and knowledge distillation. Sci Rep 16, 7143 (2026). https://doi.org/10.1038/s41598-026-38478-8
キーワード: 手話認識, 小型機械学習, エッジAI, 説明可能なAI, 多言語モデル