Clear Sky Science · ja
複雑なクラウド−エッジ−エンド環境における生成的敵対的模倣学習を用いたDT支援リソース割り当て
モノのインターネットのための賢いデータハイウェイ
都市や工場、家庭が接続されたセンサーやデバイスで満ちると、大量のデータが生まれ、それらを迅速かつ確実に処理する必要があります。すべてを遠隔のクラウドサーバに送るのは遅すぎることがあり、エッジ上の小さなデバイスは十分な計算能力を持たないことが多いです。本稿は、デバイス、近隣のエッジサーバ、クラウドの間で計算・記憶・ネットワーク資源を自動的にルーティングし割り当てる新しい手法を探ります。これにより、実世界の状況が混沌として予測不能でも、スマートなアプリケーションの動作が高速かつ堅牢に保たれます。
なぜ既存手法は苦戦するのか
現代のシステムはしばしば深層強化学習に依存しており、環境からの報酬信号を用いて試行錯誤で学習します。しかし、複雑でノイジーなネットワークでは、その報酬を定義・測定するのが難しいです。報酬関数が誤っていたり干渉で歪められると、安全でないあるいは無駄な行動を学んでしまう可能性があります。多くの既存手法はトラフィックパターンやデバイス挙動に関する豊富な事前知識を前提としますが、実際の産業ネットワークではそのような知識は稀です。さらに、ほとんどの解法は計算資源など単一の資源タイプだけを最適化し、記憶やネットワーク帯域幅を無視することが多く、実世界の性能はこれら三者の相互作用で決まる点が見落とされています。
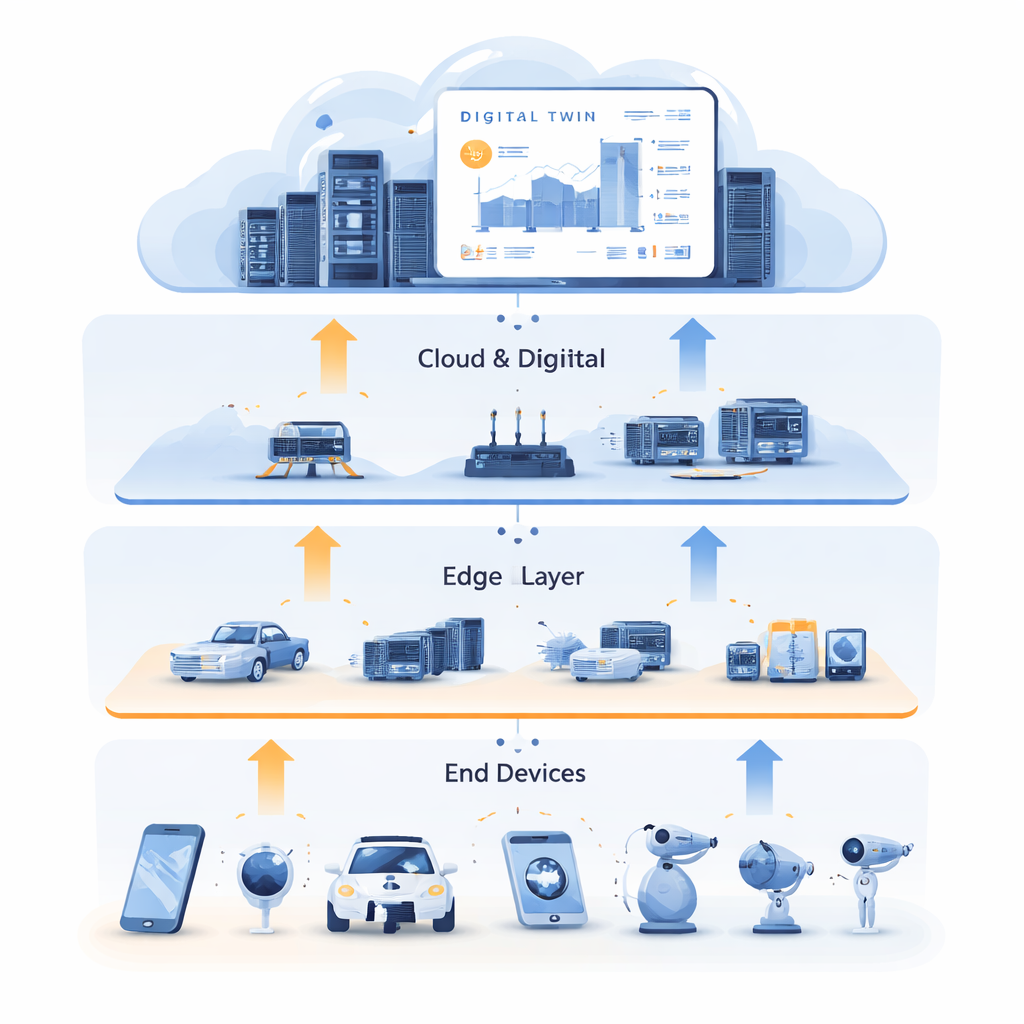
デジタル・ダブルから学ぶ
この行き詰まりを打開するために、著者らはリソース割り当てとデジタルツイン技術を組み合わせます。デジタルツインは物理ネットワークの詳細な仮想レプリカで、クラウド上で維持されます。それはエッジサーバ、リンク、タスクの状態を時系列で反映し、センサーやログからの豊富な履歴データを利用します。本研究では、デジタルツインは単なる可視化ダッシュボードではなく、訓練の場になります。過去データを用いて優れた判断の“エキスパート”事例を生成し、タスクを計算とキャッシュにどう分配するか、低遅延のためにどこで処理すべきかといった意思決定を捉えます。この訓練は本番のサービスを妨げずにオフラインで行われ、クラウドの豊富な計算資源を活用して多様な状況を探索できます。
試行錯誤ではなく模倣で学ぶ
直接報酬から学習する代わりに、提案モデル(E‑GAIL)は模倣学習を採用します:エージェントはエキスパートの振る舞いを模倣しようとします。まず著者らは、NoisyNet層を備えたActor–Criticフレームワークを用いて複数のエキスパート方策を構築します。意思決定ネットワークに慎重に制御されたノイズを注入することで、これらのエキスパートは実際の無線干渉や変動する負荷を模した撹乱を含む多様な条件を経験し、その軌跡がより現実的になります。次に、系は複数の単一エキスパートの軌跡をゲーム理論の手法を用いて単一の“マルチエキスパート”参照に融合します。エキスパート間でナッシュ均衡を追求することで対立を避け、より広範な状況をカバーするコンセンサス戦略を生成します。
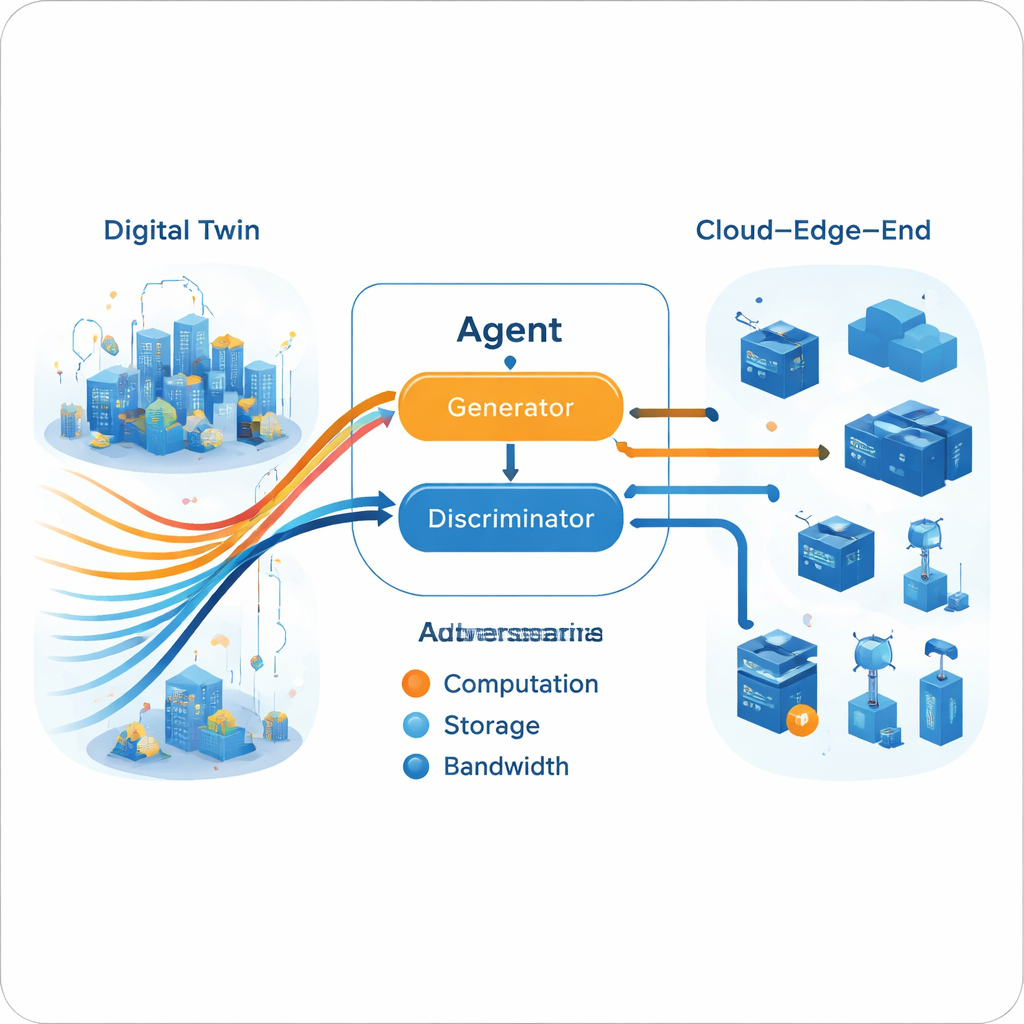
意思決定のための生成的敵対エンジン
マルチエキスパート軌跡がデジタルツイン内で構築されると、ライブのエージェントは生成的敵対設定を用いてこれを模倣するよう学習します。これは画像生成ニューラルネットワークの考え方に似ています。ジェネレータは現在のネットワーク状態を与えられてリソース割り当てアクションを提案し、ディスクリミネータは一連のアクションがエージェント由来かエキスパート軌跡由来かを判定しようとします。時間とともにこの敵対的ゲームはジェネレータを、ディスクリミネータがエキスパート行動と区別できない決定を出すよう駆り立てます。重要なのは、この過程に実環境からの明示的な報酬関数が不要である点です。訓練は分割されており、重いオフライン学習(クラウド側)がエキスパートとジェネレータを洗練し、軽めのオンライン更新(エッジ側)がモデルを現在の状況に合わせて維持し、エッジ機器の実運用上の制約に応えます。
どれほどうまく機能するか
著者らはE‑GAILを複数の代表的なベースライン(深層Q学習、ゲーム理論的オフロード、貪欲ヒューリスティック、クラウドのみ処理、ランダム割り当てなど)と比較実験しています。端末数、チャネル、タスク構成、負荷、データサイズ、距離、ノイズパターンを変えた多くの実験において、E‑GAILは一貫してエキスパート方策に非常に近いエンドツーエンド遅延を達成し、他の自動化手法より明らかに優れています。計算負荷重視と記憶重視のタスク間でシフトするとき、ネットワークが大きくなるとき、干渉が強まるときにも適応がよく、デジタルツインはエキスパート軌跡の生成を高速化し質を向上させ、マルチエキスパート融合は再学習なしに扱えるシナリオの幅を広げます。
日常システムにとっての意味
非専門家向けの要点は、このアプローチにより不確実性の高い状況でもネットワークがより賢く自己管理できるようになる、ということです。手作業でルールを作ったり脆弱な試行錯誤学習に頼ったりする代わりに、E‑GAILはデジタルツインが供給する豊かなシミュレーション経験と、数学的に調整された複数の熟練“エキスパート”に学びます。その結果、タスクをどこで実行しデータをどこに置くかを素早く決定できるリソースアロケータが生まれ、条件が変わっても応答時間を低く保てます。将来の産業用途やスマートシティでは、このような自己学習型の調整器が裏方で計算、記憶、帯域を巧みにさばき、接続された世界をより高速で信頼性が高く、エネルギー効率のよいものにする可能性があります。
引用: Zhang, X., Xin, M., Li, Y. et al. DT-aided resource allocation via generative adversarial imitation learning in complex cloud-edge-end scenarios. Sci Rep 16, 7657 (2026). https://doi.org/10.1038/s41598-026-38367-0
キーワード: デジタルツイン, エッジコンピューティング, 模倣学習, リソース割り当て, 産業用モノのインターネット