Clear Sky Science · ja
コスト効率的な参加者選定を伴う異種電子カルテシステムのためのフェデレーテッドラーニング
病院データ共有がこれほど難しい理由
現代の病院は、検査結果やバイタルサインから投薬や処置まで、患者に関する膨大なデジタル情報を収集しています。理論的には、多数の施設の記録を結合すれば、誰がリスクにあるかやどの治療が最も有効かを予測するより賢いコンピュータモデルを構築できます。しかし実務では、病院ごとに異なるソフトウェアを使い、互換性のない形式でデータを保管し、患者のプライバシーと予算を厳格に守らなければなりません。本研究は、記録を複製したり支出を過度に増やしたりせずに、病院同士が互いのデータから学べるようにする方法を探ります。
生データを共有せずに共同で学習する
著者らはフェデレーテッドラーニングと呼ばれる手法を基にしています。各病院が自施設の患者記録でローカルモデルを学習し、生データではなくモデル更新のみを共有します。中央の「ホスト」病院がこのプロセスを調整し、重症患者の合併症予測などホスト自身のニーズに沿った予測モデルを改良することを目指します。他の病院(サブジェクト)は報酬を得て参加します。この仕組みは敏感な記録を施設間で移動させることを避けますが、二つの難問を生みます:多様な記録システムにどう対処するか、そして実際にはモデルに寄与しない参加先へ支払いをしないようにするにはどうするか、です。
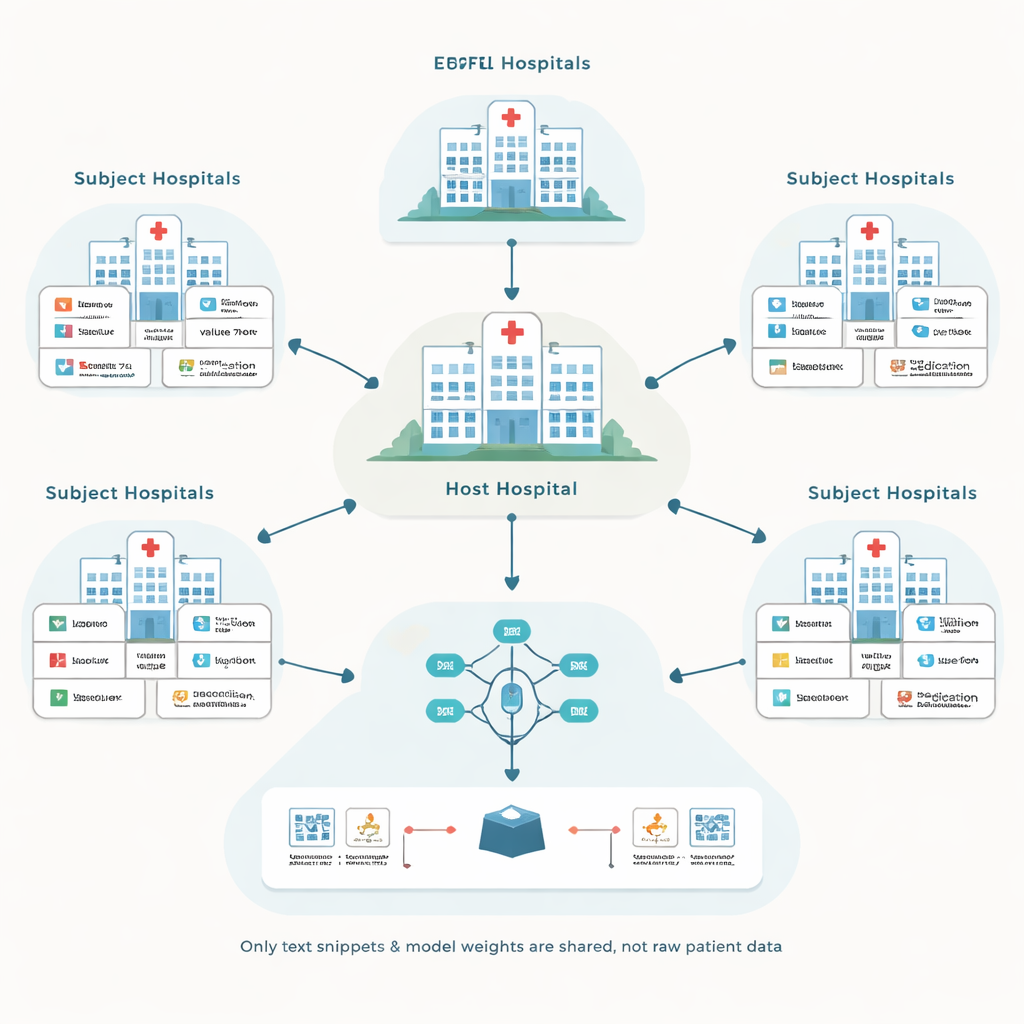
雑多な記録を共有可能な言語に変える
電子カルテシステムは情報のラベリングやコーディングが大きく異なります。ある病院では血糖検査が数値コードで保存され、別の病院では同じ検査に別のコードを使うことがあります。従来の解決策はすべてを単一の精緻に設計された標準データベースに変換することでしたが、これは高価で多くの専門家の工数を必要とします。代わりに提案されたフレームワークEHRFLは、各医療イベントを短いテキストに変換します。たとえばグルコースの検査記録は「lab event glucose value 70 mg/dL」のようなフレーズになります。各病院はすでにローカルコードを人間が読める名称に対応させる辞書を保持しているため、この変換はカスタムの手作業をほとんど必要とせず自動化できます。
テキストから患者プロファイルを構築する
イベントをテキストにした後、EHRFLは最新の自然言語処理モデルを使って各イベントを数値ベクトルに変換し、多数のイベントを組み合わせて単一の「患者埋め込み」──一定時間内のその人の医療履歴をコンパクトに要約したもの──を作ります。これらの埋め込みは入院中の死亡予測や集中治療入院後の腎障害予測など、複数の臨床タスクを同時に扱う予測層に入力されます。著者らは異なる病院、時期、記録システムにまたがる5つの大規模実世界重症患者データセットでフェデレーテッド学習を実行しました。一般的なフェデレーテッド手法を含む一連のアルゴリズムで、テキストベースの手法で訓練されたモデルは、基礎となるデータ形式が異なっていても、単一病院のみで訓練したモデルを一貫して上回りました。
プライバシーを守りながら適切な協力先を選ぶ
参加病院が多ければ必ずしも結果が良くなるわけではありません。ある施設は患者構成や記録パターンがホストと大きく異なり、参加が学習を遅らせたり性能をわずかに低下させたりする一方でコストだけを増やすことがあります。これに対処するため、著者らは病院間の患者埋め込みの類似度に基づく選定ステップを提案します。ホストはまず自施設データでモデルを訓練し、その重みを共有します。各候補病院はそれを用いて患者埋め込みを算出します。プライバシー保護のため、各サブジェクトは埋め込みの極端な値を切り詰め、それらを平均化した単一ベクトルにまとめたうえで、慎重に調整したランダムノイズを加えてそのノイズ付き平均のみをホストに送ります。ホストは自らの平均と各サブジェクトのそれを単純な類似度指標で比較し、完全なフェデレーテッド実行に参加させる最も類似した病院のみを選びます。
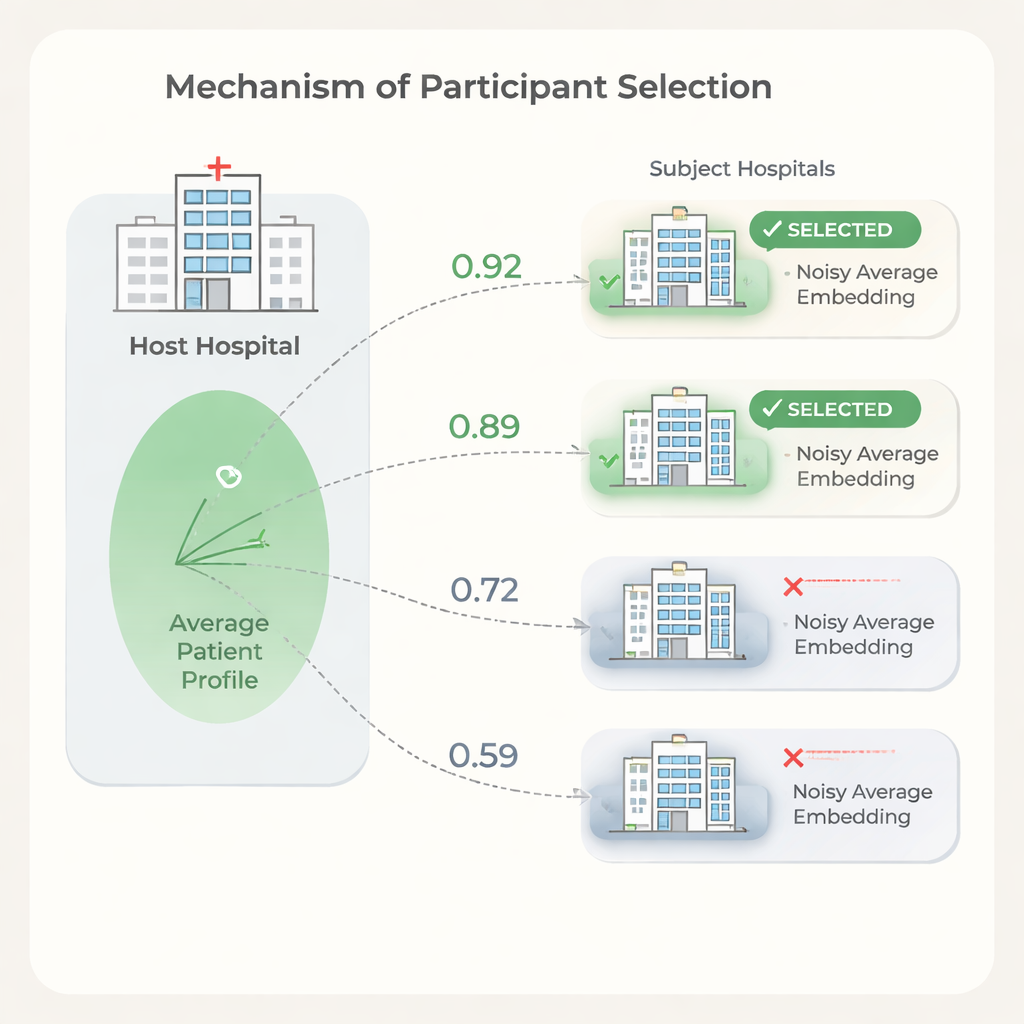
精度を落とさずに費用を節約する
実験により、病院間の平均患者埋め込みの類似度は、それぞれの病院がホストの予測性能にどれだけ寄与するか(あるいは害するか)と一致することが示されました。この信号を用いて協力先を選べば、ホストは低類似度の病院を除外しつつ、すべてのサイトを使った場合と比べて予測品質を維持または改善できます。著者らはコストモデルも示しており、データ使用料や学習時間は参加病院数に比例して増えるため、参加者を適度に減らすだけで大きな節約につながる可能性があると述べています。同時に、選定ステップは軽量です:モデルは一度だけ訓練され、各病院は単一の平均ベクトルに対して単純な計算を行うだけです。
将来の医療AIにとっての意義
分野外の読者に向けた主要なメッセージは、病院が生の患者記録をプールすることなく「共に学ぶ」ことが可能になり得る点と、それをプライバシーと財政的制約の両方に配慮して実施できる可能性があるということです。多様な記録を共有可能なテキスト形式に翻訳し、患者集団のプライバシー保護された要約を使って互換性のある協力先を選ぶことで、EHRFLは施設固有の予測ツールを構築する実用的な道筋を提供します。本研究は集中治療データに焦点を当てていますが、同じ考え方は外来クリニックや救急部門、さらには組織がデータの管理権を手放さずにより良いモデルで協力したい非医療分野にも応用できるでしょう。
引用: Kim, J., Kim, J., Hur, K. et al. Federated learning for heterogeneous electronic health record systems with cost effective participant selection. Sci Rep 16, 6876 (2026). https://doi.org/10.1038/s41598-026-38299-9
キーワード: フェデレーテッドラーニング, 電子カルテ, 患者のプライバシー, 臨床予測, ヘルスケアAI